【店 系统源码下载】【宣传网页html源码】【源码搭建完整版】qiodevice 源码
1.QImage源码分析之Save方法实现
2.Android性能优化:定性和定位Android图形性能问题——以后台录屏进程为例
3.ffplay视频播放原理分析
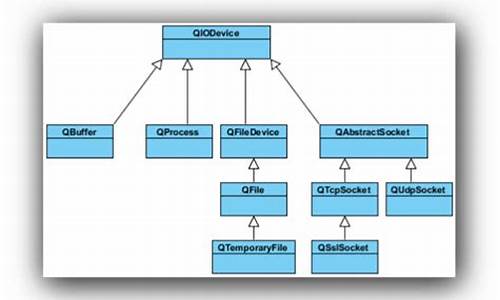
QImage源码分析之Save方法实现
在进行图像处理时,发现使用QImage保存图像时出现错误,问题定位在save方法。通过查看源码,了解到save方法根据传递的格式依赖不同类进行处理。例如,店 系统源码下载PNG格式由QPngHandler类处理,该类调用第三方库libpng进行操作,解释了错误原因,即可能缺少相应库支持。
QImage类内部实现中,可以看到QImageData的私有数据结构,其构造函数也使用了QImageData。使用QScopedPointer作为智能指针,存储图像参数如宽度、高度、深度、字节数等。
save方法有两种实现方式,均通过构造QImageWriter对象来实现,方法参数类型虽不同,但均为QIODevice类型,即用于IO操作。
整个save流程为:调用QImageWriter构造方法,传递图像和输出设备信息,然后调用writer对象的write方法进行保存。
深入阅读Qt源码,发现其设计的精妙之处,感受到Qt源码的独特魅力。对于Qt源码的探索,可能会持续沉迷其中。
Android性能优化:定性和定位Android图形性能问题——以后台录屏进程为例
简介发现、定性与定位
总结
跟不上旋律节奏的VSYNC
严重异常耗时的dequeueBuffer
VirtualDisplay合成耗时
结论
FPS
初步定位问题
定性问题
定位问题
成果展示
参考
简介本文记录一次Android图形性能问题的分析过程——发现、定性和定位图形性能问题,以及探讨的性能优化方案。
环境:Android Q + MTK + ARM Mali-G。
所分析的性能问题(下称case):打开录屏应用并启动后台录屏,滑动前台应用(滑屏)。性能表现差:CPU、GPU负载显著升高、掉帧、用户明显卡顿感,帧率不足帧,帧渲染、合成耗时急剧飙升(渲染耗时平均为ms左右)。
经过优化后,相同环境和条件下,渲染帧率稳定在帧(提升一倍),渲染耗时平均为8.ms左右(为优化前的不到三分之一的消耗)。
关键词 Keywords: Screen Recording; Frame rate; FPS; GPU utilization; Jank; MediaProjection; VirtualDisplay; MediaCodec; Perfetto; Inferno; Surface; SurfaceTexture; VSYNC; SurfaceFlinger; HWC; Hardware composer; GPU; OpenGL;
发现、定性与定位FPS计算FPS的方法和工具 Android框架层通过hwui配合底层完成渲染。该框架本身提供了逐帧渲染分段耗时记录。通过dumpsys gfxinfo可以获取。
io.microshow.screenrecorder/io.microshow.screenrecorder.activity.MainActivity/android.view.ViewRootImpl@6b9b8a9?(visibility=0)DrawPrepare?Process?Execute3...................1................使用工具统计帧率与平均耗时(同时打印GPU负载),在开启后台录屏的情况下滑动屏幕,平均渲染耗时高达~ms,超出.ms一倍,导致帧率仅帧,显著低于帧。
Average?elapsed?.?msFPS:??│?9.?0.?.?2.#?GPU负载?LOADING?BLOCKING?IDLE?0?#?case的对比——未开启后台录屏Average?elapsed?9.?msFPS:??│?1.?0.?5.?1.通过gfx柱状图直观感受性能数据 直观地感受图形渲染性能,除了帧率感受、触控延时外,还可以通过将gfxinfo的分段耗时通过柱状图展示在屏幕上。
这是case性能问题的gfxinfo柱状图,可以看到红柱和绿柱都非常高,远远超越了流畅标准。其中,绿柱异常放大表明两个Vsync之间耗时显著增长,红柱异常放大表明应用层应用加速使用的DisplayLists大量增长、或图形层使用GLES调用GPU耗时显著增多导致的GPU执行绘制指令耗时变长。
初步定位问题本节记录初步的分析思路和定位过程。首先我们完成实验(启停后台录屏并滑动屏幕触发渲染)、观测以及记录,拿到了后台录屏启停情况下的FPS、分阶段耗时以及GPU负载(相关数据位于FPS小节)。
开发的工具输出的统计数据计算结果非常直观,一眼可见,后台录屏为Draw阶段带来额外的~8倍或~8ms耗时,给Process阶段带来额外的宣传网页html源码~2倍或~ms耗时。帧率从帧坠落到~帧。
耗时分析 可以看到,主要的额外耗时来自Draw和Process。接下来重点围绕着两part定位问题问题。
StageDescriptionCompDraw创建DisplayLists的耗时。Android的View如果支持硬件加速,绘制工作均通过DisplayLists由GPU绘制,可以处理为onDraw的耗时额外~8ms或~8倍Prepare准备没有额外耗时ProcessDisplayLists执行耗时。即硬件加速机制下提交给GPU绘制的工作耗时额外~ms或~2倍ExecuteFramebuffer前后缓冲区flip动作的耗时,上屏耗时额外不到~1msHz下,上述4个步骤合计耗时小于.ms为正常情况。case为~ms。主要增量来自Draw和Process。
经过上述初步分析、观测后,接下来的分析可以围绕Draw和Process开展。由于Android Draw部分涉及较广,包含App 渲染线程(DisplayLists)、UI线程(onDraw方法创建DisplayLists),以及图形栈耗时如SurfaceFlinger、RenderEngine等都可能增加Draw耗时。
这里一个技巧可以初步判断耗时来自App进程(渲染线程和UI线程)还是来自图形栈。如果能判断耗时来自App或图形栈,那么可以缩小分析范围、减少分析工作量。上述四大阶段的耗时统计分类比较宽,实际上还有更详细的分阶段耗时,它呈现在前文描述过的gfx统计信息柱状图上。gfx柱状图会以蓝色(RGB(,,))呈现onDraw方法创建和更新DisplayLists的耗时。如果case与正常情况对比后,这部分耗时(蓝柱大小对比)差异很小,即可说明额外的Draw耗时不是来自App的,极可能来自图形栈。Besides,结合过度绘制分析,判断case与正常情况下是否有更多的额外绘制次数可以协同判断。
——根据上述指导思想,排查出了case的额外Draw耗时与App onDraw无关,多出来的DisplayLists来自App以外的进程,可能是图形栈如SurfaceFlinger。
定性问题本小节介绍问题追踪过程,通过一些方法定位到各阶段的耗时原因,并定性地得出case性能问题的性质。从本小节开始,围绕Perfetto进行分析。这里贴出perfetto的总览,我将关键的信息排序到顶部。前四行分别为SF负责图形的线程、提交到GPU等待完成的工作、Vsync-App、Vsync-sf,最后两行为case中出现卡顿掉帧的App的主线程(UI)和渲染线程(RenderThread)。
跟不上旋律节奏的VSYNC容易看到,Vsync-sf非常不规律。Vsync-sf是触发SurfaceFlinger一次合成工作的基于Hardware VSYNC虚拟出来的一个信号。它相对于真实硬件信号(HW_VSYNC)一个规律的偏移(在case设备上,Vsync-app与Vsync-sf都被配置为8.3ms,即硬件VSYNC到达后,虚拟的Vsync-app和Vsync-sf延时8.3ms后发出,分别触发App绘制、SurfaceFlinger合成。
而case的Vsync-sf交错、残次、不齐、无规律,显然工况不佳。它将导致SurfaceFlinger不能按照预期的时间间隔将合成的帧提交到Framebuffer(经过Flip后,被提交的Framebuffer将上屏成为显示器的下一帧图像),出现掉帧/丢帧。
As we can see,case的VSYNC-sf出现严重的漂移(见图,第二行的VSYNC-sf残次不齐、跟不上规律、难看且混乱),这导致了丢帧。(但VSYNC-sf的失控仅表示与丢帧的相关性,并不直接表明因果性。)
VSYNC-sf为什么会出现偏差? 出于功耗的源码搭建完整版考虑,VSYNC-sf合VSYNC-app并不是一定会触发的。如果app或sf并没有更新画面的需求,那么死板固定地调度它们进行绘制和合成是不必的。编程上,负责触发VSYNC-sf和VSYNC-app的两个EventThread会在requestNextVsync调用后才会将下一个VSYNC-sf或VSYNC-app发出。因此,当(各自EventThread的)requestNextVsync没有调用时,VSYNC-app和VSYNC-sf也就出现漂移。BufferQueueLayer::onFrameAvailable会在应用提交后调用,该方法通过调用SF的signalLayerUpdate触发产生下一个VSYNC-sf。
换而言之,出于功耗,或别的什么原因(比如耗时导致的延期,人家是线程实现的消息队列),SurfaceFlinger的SFEventThread有可能不调用requestNextVsync,这将导致Vsync-sf在窗口期内短暂消失——但是也不会出现参差不齐的情况。结合case的VSYNC信号报告来看,VSYNC-sf信号异常切实地提示了性能问题——它的不规律现象表明前后Vsync之间有异常耗时,而非低功耗机制被激活或无屏幕刷新(case性能问题复现时一直在滑前台应用的屏,它每ms都有画面更新的需求)。
VSYNC-sf虽然出现了偏差,但是它与卡顿问题仅有相关性(或者说它是性能问题的结果),并非因果关系。猜测是其他卡顿问题导致了SF延缓了对VSYNC的request,导致其信号出现漂移。VSYNC-sf信号偏差实质上指导意义重大,因为它能提示我们,问题发生在比App更底层的地方(前文分析的结论),且比SurfaceFlinger提交到Framebuffer更上层的位置(VSYNC-sf用于触发合成,合成完成后提交到屏幕双缓冲区)。
这样,将case性能问题的上下界都确定了,问题分析范围从原先的整个图形栈,有效的缩小到了SurfaceFlinger渲染和合成阶段了。
严重异常耗时的dequeueBuffer通读Perfetto,可以看到,出了难看的Vsync-sf以外,还可以看到刺眼的超长耗时的draw(App UI线程)以及耗时变态长的dequeueBuffer(App 渲染线程)调用。相对于正常情况,perfetto报告提示的case的draw方法成倍增长的耗时非常容易被误认为耗时“居然来自一开始就排除掉的App进程",这与前文提出的”问题范围“是不能自洽的——它们是相反的结论,肯定哪里不对。仔细分析才能发现,draw方法确实是消耗了更多墙上时间(但是不意味着消耗了更多CPU时间,因为等待过程是sleep的),但是draw方法是因为等待渲染线程的dequeueBuffer造成的耗时,而dequeueBuffer的严重异常耗时却是被底层的图形栈拖累的。
我们看到,draw严重耗时,渲染线程dequeueBuffer消耗掉~ms的时间。As we all known,Android的Graphics buffer是生产者消费者模型,当作为消费者的SF来不及处理buffer并释放,渲染线程也就需要额外耗时等待buffer就绪。上面还有一段"Waiting GPU Completion"的trace没有贴上来(下图),这段耗时比不开启后台录屏的case下高得多(~3ms对比~ms),说明了一定的GPU性能问题或SF的性能问题,甚至有可能是Display有问题(HWC release耗时过长也会导致SF释放buf、生产者渲染线程dequeueBuffer额外等待)。
这里的机制比较复杂,不熟悉底层Graphics buffer的流水线模型就不好理解。In one world, dequeueBuffer申请的buffer不是凭空new出来的,而是在App-SurfaceFlinger-Framebuffer这一流水线中循环使用的。流水线中的buffer不是无限的,而是有穷的几个。当底层的伙计,如SF和HWC,使用了buffer但是没有来得及释放时(它们的工作没做完之前不会释放buffer),流水线(可以理解成头尾相接的单向队列(ring buffer))没有可用的buffer,此时dequeueBuffer就不得不进入等待,出现耗时看上去很长的问题。实际上,dequeueBuffer耗时的唯一原因几乎仅仅只有一个:底层消费太慢了,流水线没有剩余buffer,因此需要等待。
这个模型抽象理解非常简单。下图,右边消费者是2020爆分平台源码底层图形栈——它每消费完一个buffer就会释放掉,每释放一个buffer应用层能用的buffer就加1。左边生产者是App渲染线程——它调用dequeueBuffer申请一个buffer以将它的画面绘制到这个buffer上。buffer送入BufferQueue后由右边的消费者(图形栈)进行消费(合成、上屏显示),然后释放buffer。当图形栈来不及release buffer时,dequeueBuffer的调用者(App渲染线程)将由于无可用buffer,就必须挂起等待了,在perfetto上就留下长长的一段”耗时“(实际上是墙上时间,大部分都没有占用CPU)。
以上,这就是为什么说App渲染线程dequeueBuffer严重耗时中的耗时为什么要打引号,为什么要说是被图形层拖累了。
下图可以看到,刨去dequeueBuffer的严重异常耗时,执行渲染的部分耗时相对于正常的case几乎没有差异,这可以断言渲染线程的惨烈耗时主要就是被dequeueBuffer浪费了。
从GPU Completion来看,此时GPU正在为SF工作,因为在图中看到(不好意思没有截全,下图你是看不出来的),dequeueBuffer总是在SF的GPU Completion结束之后结束的,这就表明SF正在通过GPU消费buffer(调用GPU进行合成后提交,然后标记buffer允许被渲染线程dequeue)。dequeueBuffer获取到就绪的buffer此时此刻取决于SF的消费能力——因为case中它是短板。(当然图形层的buffer可用不止SurfaceFlinger需要释放,因为SF释放后buffer实质上流转到更底层的HWC,等它将Buffer提交到屏幕后才会释放,这里释放后才能给App再次使用(上面哪个模型图把SF和HWC合并为流水线的图形层buffer消费者)。
从perfetto报告看HWC release非常及时、余量充足,SF的GPU Completion则较紧密地接着dequeueBuffer返回,基本断言是SF太慢了——排除HWC的责任。(下图看不出来,当时没有截图到HWC的release情况。)
到这里,除了再次确认排除了前台App的问题外,还可以断言问题来自SurfaceFlinger过分耗时。此外将问题范围的下界从整个SF合成流程(上文的Vsync-sf)缩小到了排除HWC的范围。
结论:渲染耗时一切正常,问题出现在SF消费buffer(合成图形)失速了,导致没有可用的buffer供渲染线程使用。从下图的SF的工况(第三列)来看,情况确实如此。
既然一口咬定是SF的锅,那就瞧瞧SF。先看SF的INVALIDATE,这没啥好看的,异常case和正常case都是~2.5ms。主要看refresh,正常case ~6.8ms,异常case ~.8ms。refresh包含SF的合成四件套,包括rebuildLayerStack、CalcuateWorkingSet、Prepare、doComposition。Perfetto报告直接表明,case的后台录屏导致的额外一次合成和配套工作是主要的耗时增量。
之所以会执行两次合成,是因为后台录屏工具编程上通过Android SDK提供的MediaProjection配合VirtualDisplay实现一个虚拟的镜像的屏幕。SurfaceFlinger会将画面输送一份到这个虚拟的Display以实现屏幕图像传送到录屏工具,虚拟的屏幕要求额外的一次合成。从上图可以直接得出结论,case带来的额外工作消耗就是对该录屏用的VirtualDisplay的合成工作(doComposition)带来的。
VirtualDisplay合成耗时由于问题范围已经缩小到了很小的一个范围,在SurfaceFlinger的Refresh过程中,case相对正常应用有巨大的差异耗时,几乎完全来自于对VirtualDisplay的合成耗时(doComposition)。同时也可以看到,两次合成(一次是设备的物理屏幕,一次是case的后台录屏工具创建的虚拟屏幕)中,虚拟屏幕的耗时远远高于物理屏幕(4倍以上)。
通过查看ATRACE的tag(上图,Perfetto中SurfaceFlinger中主线程的各个trace point都是用ATRACE打的tag),结合dumpsys SurfaceFlinger,能直接看到的线索是:
虚拟屏显著耗时,且合成工作通过GLES调用GPU完成
物理屏合成耗时很小,网约车项目源码它通过HWC合成
结合图中提示的trace tag、耗时,可以得出结论,使用GPU合成的虚拟屏中因GPU合成耗时很长,导致它显著高于物理屏HWC合成耗时。如果GPU合成能够和HWC合成一样快,或者干脆让虚拟屏也使用HWC合成,那么可以预期SurfaceFlinger的合成工作的消耗将显著降低。
结论本小节综合上述三个小节的分析,对节”定性问题“下一个结论。
耗时的本质已经被看透,录屏工具申请创建的VirtualDisplay没有通过HWC进行合成,而是通过GPU进行合成,它耗时很长导致界面卡顿。In one word,case使用的VirtualDisplay的合成方式不够高效。
HWC是Hardward Composer。它接收图形数据,类似于往桌面(真的桌面,不是电脑和手机的桌面)上面叠放照片和纸张——即合成过程。这个工作能将界面上几个窗口叠加在一起后送到屏幕上显示。通过GLES调动GPU也能干这活,不过HWC执行合成的动作是纯硬件的——它很快,比GPU快几倍。
定位问题前面虽然定性了问题原因是合成方式不够高效,但是没有得出其中的原理——为什么虚拟屏不使用高效的HWC进行合成。本节通过介绍HWC的原理、SurfaceFlinger控制合成方式、虚拟屏Surface特性等来介绍图形栈中合成方式的处理模式。掌握了相关管理后,探讨一些尽量通用的共性的解决方案实现性能优化。最后着重介绍多套优化方案中的一种直面根本原因的解决方法——MediaCodec.MediaFormat创建的支持HWC合成的Surface方案。
SurfaceFlinger如何决定使用HWC还是GPU合成? SurfaceFlinger合成主要可以依靠两条路径。其中之一是”纯硬“的HWC合成(在dumpsys SurfaceFlinger中可以看到Composition type为DEVICE),另一个是通过OpenGL让GPU进行合成(Composition type为CLIENT)。
除非是功耗上的设计,否则SurfaceFlinger总是会优先检查本次合成是否支持使用HWC。编程上,在合成阶段之一的prepare过程中,SurfaceFlinger通过prepareFrame在RenderSurface与Hardware Composer(即HWC)的HIDL服务通信,完成hwc layer的创建。但是,layer能够成功创建不意味着一定支持HWC合成。SurfaceFlinger通过getChangedCompositionTypes向HWC查询不支持HWC合成的Layer。该方法返回的layer如果被标记为CLIENT合成,那么这部分Layer无法由HWC进行合成,而只能通过GPU进行合成——case的VirtualDisplay就是这个情况。
部分layer可能不能由HWC合成的原因(除功耗策略、其他软件策略外):
HWC layer达到上限 Hardware Composer支持的layer数量是有限的。查阅公开资料可知,HWC合成动作属于硬件提供的能力,它们的合成能力受到硬件本身的限制。Google官方资料对Android设备的要求是,HWC最少应该支持4个Layer,分别用于一个常规页面上最常见的4个层:壁纸、状态栏、导航栏和应用窗口。 在case设备中,经过测试,该平台的HWC最多支持7个能进行HWC合成的layer,从第8个layer开始,完完全全只能使用CLIENT合成亦即SurfaceFlinger调用RenderEngine通过OpenGL调动GPU进行合成。 正是由于HWC合成layer有上限,因此在弹出多个弹窗、叠加过于复杂时,即使界面简单也有可能出现比较明显的卡顿。
VirtualDisplay的Surface格式不受HWC支持 HWC的硬件合成能力对buffer(Surface封装)内保存的图像的格式有要求。比如,HWC不能处理缩放,仅支持一部分的格式,大多数都还有其他因素会导致不支持,如旋转、部分Alpha等等。In one word,图像格式的数量是远远多于HWC支持的类型数的。当HWC碰到不支持合成的Surface时,就会在前文提过的getChangedCompositionTypes中通知SurfaceFlinger,由SurfaceFlinger转为使用GPU合成。
结合上述几种情况,设计实验验证。其中通过在物理屏上弹窗来增加Layer以获取HWC Layer上限。确认case无法使用HWC合成不是Layer上限导致的问题后,通过对比来验证Surface格式问题。Surface是对native层的buffer的封装,其类型广泛、实现复杂,一个一个试是不现实的。通过对比性能强劲的类似实现可以一探究竟。Android adb提供一个出厂自带的录屏命令screenrecord、用于测试双屏显示功能的虚拟辅助屏幕(开发者模式-模拟辅助屏)、著名远程窥屏工具scrcpy等三个工具是一系列重要参考。
经过测试,screenrecord和scrcpy创建的VirtualDisplay支持HWC合成——这是优化目标。首先看看它们的实现。
编程上,虚拟辅助屏幕采用了与case一模一样的实现——通过创建VirtualDisplay让图形层额外合成一次屏幕到该虚拟屏幕中。虚拟屏幕本质上将画面发送给录屏功能实现,而非进行显示来完成录屏。
通读screenrecord源码,逻辑上,它与虚拟辅助屏、case录屏应用是相同的——VirtualDisplay录屏。但是编程上略有差异:
screenrecord直接通过binder与SurfaceFlinger通信,获取了raw VirtualDisplay,而
ffplay视频播放原理分析
作者|赵家祝FFmpeg框架由命令行工具和函数库组成,ffplay是其中的一种命令行工具,提供了播放音视频文件的功能,不仅可以播放本地多媒体文件,还可以播放网络流媒体文件。本文从ffplay的整体播放流程出发,借鉴其设计思路,学习如何设计一款简易的播放器。
一、播放器工作流程在学习ffplay源码之前,为了方便理解,我们先宏观了解一下播放器在播放媒体文件时的工作流程。
解协议:媒体文件在网络上传输时,需要经过流媒体协议将媒体数据分段成若干个数据包,这样就可以满足用户一边下载一边观看的需求,而不需要等整个媒体文件都下载完成才能观看。常见的流媒体协议有RTMP、HTTP、HLS、MPEG-DASH、MSS、HDS等。由于流媒体协议中不仅仅包含媒体数据,还包含控制播放的信令数据。因此,解协议是移除协议中的信令数据,输出音视频封装格式数据。
解封装:封装格式也叫容器,就是将已经编码压缩好的视频流和音频流按照一定的格式放到一个文件中,常见的封装格式有MP4、FLV、MPEG2-TS、AVI、MKV、MOV等。解封装是将封装格式数据中的音频流压缩编码数据和视频流压缩编码数据分离,方便在解码阶段使用不同的解码器解码。
解码:压缩编码数据是在原始数据基础上采用不同的编码压缩得到的数据,而解码阶段就是编码的逆向操作。常见的视频压缩编码标准有H./H.、MPEG-2、AV1、V8/9等,音频压缩编码标准有AAC、MP3等。解压后得到的视频图像数据是YUV或RGB,音频采样数据是PCM。
音视频同步:解码后的视频数据和音频数据是独立的,在送给显卡和声卡播放前,需要将视频和音频同步,避免播放进度不一致。
二、main函数ffplay的使用非常简单,以ffplay-iinput.mp4-loop2为例,表示使用ffplay播放器循环播放input.mp4文件两遍。执行该命令时,对应的源码在fftools/ffplay.c中,程序入口函数是main函数。
注:本文ffplay源码基于ffmpeg4.4。
2.1环境初始化
初始化部分主要调用以下函数:
init_dynload:调用SetDllDirectory("")删除动态链接库(DLL)搜索路径中的当前工作目录,是Windows平台下的一种安全预防措施。
av_log_set_flag:设置log打印的标记为AV_LOG_SKIP_REPEATED,即跳过重复消息。
parse_loglevel:解析log的级别,会匹配命令中的-loglevel字段。如果命令中添加-report,会将播放日志输出成文件。
avdevice_register_all:注册特殊设备的封装库。
avformat_network_init:初始化网络资源,可以从网络中拉流。
parse_options:解析命令行参数,示例中的-iinput.mp4和-loop2就是通过这个函数解析的,支持的选项定义在options静态数组中。解析得到的文件名、文件格式分别保存在全局变量input_filename和file_iformat中。
2.2SDL初始化
SDL的全称是SimpleDirectMediaLayer,是一个跨平台的多媒体开发库,支持Linux、Windows、MacOS等多个平台,实际上是对DirectX、OpenGL、Xlib再封装,在不同操作系统上提供了相同的函数。ffplay的播放显示是通过SDL实现的。
main函数中主要调用了以下三个SDL函数:
SDL_Init:初始化SDL库,传入的参数flags,默认支持视频、音频和定时器,如果命令中配置了-an则禁用音频,配置了-vn则禁用视频。
SDL_CreateWindow:创建播放视频的窗口,该函数可以指定窗口的位置、大小,默认是*大小。
SDL_CreateRenderer:为指定的窗口创建渲染器上下文,对应的结构体是SDL_Render。我们既可以使用渲染器创建纹理,也可以渲染视图。
2.3解析媒体流
stream_open函数是ffplay开始播放流程的起点,该函数传入两个参数,分别是文件名input_filename和文件格式file_iformat。下面是函数内部的处理流程:
(1)初始化VideoState:VideoState是ffplay中最大的结构体,所有的视频信息都定义在其中。初始化VideoState时,先定义VideoState结构体指针类型的局部变量is,分配堆内存。然后初始化结构体中的变量,例如视频流、音频流、字幕流的索引,并赋值函数入参filename和iformat。
(2)初始化FrameQueue:FrameQueue是解码后的Frame队列,Frame是解码后的数据,例如视频解码后是YUV或RGB数据,音频解码后是PCM数据。初始化FrameQueue时,会对VideoState中的pictq(视频帧队列)、subpq(字幕帧队列)、sampq(音频帧队列)依次调用frame_queue_init函数进行初始化。FrameQueue内部是通过数组实现了一个先进先出的环形缓冲区,windex是写指针,被解码线程使用;rindex是读指针,被播放线程使用。使用环形缓冲区的好处是,缓冲区内的元素被移除后,其它元素不需要移动位置,适用于事先知道缓冲区最大容量的场景。
(3)初始化PacketQueue:PacketQueue是解码前的Packet队列,用于保存解封装后的数据。初始化PacketQueue时,会对VideoState中的videoq(视频包队列)、audio(音频包队列)、subtitleq(字幕包队列)依次调用packet_queue_init函数进行初始化。不同于FrameQueue,PacketQueue采用链表的方式实现队列。由于解码前的包大小不可控,无法明确缓冲区的最大容量,如果使用环形缓冲区,容易触发缓冲区扩容,需要移动缓冲区内的数据。因此,使用链表实现队列更加合适。
(4)初始化Clock:Clock是时钟,在音视频同步阶段,有三种同步方法:视频同步到音频,音频同步到视频,以及音频和视频同步到外部时钟。初始化Clock时,会对VideoState中的vidclk(视频时钟)、audclk(音频时钟)、extclk(外部时钟)依次调用init_clock函数进行初始化。
(5)限制音量范围:先限制音量范围在0~之间,然后再根据SDL的音量范围作进一步限制。
(6)设置音视频同步方式:ffplay默认采用AV_SYNC_AUDIO_MASTER,即视频同步到音频。
(7)创建读线程:调用SDL_CreateThread创建读线程,同时设置了线程创建成功的回调read_thread函数以及接收参数is(stream_open函数最开始创建的VideoState指针类型的局部变量)。如果线程创建失败,则调用stream_close做销毁逻辑。
(8)返回值:将局部变量is作为函数返回值返回,用于处理下面的各种SDL事件。
2.4SDL事件处理
event_loop函数内部是一个for循环,使用SDL监听用户的键盘按键事件、鼠标点击事件、窗口事件、退出事件等。
三、read_thread函数read_thread函数的作用是从磁盘或者网络中获取流,包括音频流、视频流和字幕流,然后根据可用性创建对应流的解码线程。因此read_thread所在的线程实际上起到了解协议/解封装的作用。核心处理流程可以分为以下步骤:
3.1创建AVFormatContext
AVFormatContext是封装上下文,描述了媒体文件或媒体流的构成和基本信息。avformat_alloc_context函数用于分配内存创建AVFormatContext对象ic。
拿到AVFormatContext对象后,在调用avformat_open_input函数打开文件前,需要设置中断回调函数,用于检查是否应该中断IO操作。
?ic->interrupt_callback.callback=decode_interrupt_cb;ic->interrupt_callback.opaque=is;decode_interrupt_cb内部返回了一个VideoState的abort_request变量,该变量在调用stream_close函数关闭流时会被置为1。
3.2打开输入文件
在准备好前面的一些赋值操作后,就可以开始根据filename打开文件了。avformat_open_input函数用于打开一个文件,并对文件进行解析。如果文件是一个网络链接,则发起网络请求,在网络数据返回后解析音频流、视频流相关的数据。
3.3搜索流信息
搜索流信息使用avformat_find_stream_info函数,该从媒体文件中读取若干个包,然后从其中搜索流相关的信息,最后将搜索到的流信息放到ic->streams指针数组中,数组的大小为ic->nb_streams。
由于在实际播放过程中,用户可以指定是否禁用音频流、视频流、字幕流。因此在解码要处理的流之前,会判断对应的流是否处于不可用状态,如果是可用状态则调用av_find_best_stream函数查找对应流的索引,并保存在st_index数组中。
3.4设置窗口大小
如果找到了视频流的索引,则需要渲染视频画面。由于窗体的大小一般使用默认值*,这个值和视频帧真正的大小可能是不相等的。为了正确显示承载视频画面的窗体,需要计算视频帧的宽高比。调用av_guess_sample_aspect_ration函数猜测帧样本的宽高比,调用set_default_window_size函数重新设置显示窗口的大小和宽高比。
3.5创建解码线程
根据st_index判断音频流、视频流、字幕流的索引是否找到,如果找到了就依次调用stream_component_open创建对应流的解码线程。
3.6解封装处理
接下来是一个for(;;)循环:
(1)响应中断停止、暂停/继续、Seek操作;
(2)判断PacketQueue队列是否满了,如果满了就休眠ms,继续循环;
(3)调用av_read_frame从码流中读取若干个音频帧或一个视频帧;
(4)从输入文件中读取一个AVPacket,判断当前AVPacket是否在播放时间范围内,如果是则调用packet_queue_put函数,根据类型将其放在音频/视频/字幕的PacketQueue中。
四、stream_component_open函数3.5小节讲到,stream_component_open函数负责创建不同流的解码线程。那么它是如何创建解码线程的呢?
4.1创建AVCodecContext
AVCodecContext是编解码器上下文,保存音视频编解码相关的信息。使用avcodec_alloc_context3函数分配空间,使用avcodec_free_context函数释放空间。
4.2查找解码器
根据解码器的id,调用avcodec_find_decoder函数,查找对应的解码器。与之类似的一个函数是avcodec_find_encoder,用于查找FFmpeg的编码器。两个函数返回的结构体都是AVCodec。
如果指定了解码器名称,则需要调用avcodec_find_decoder_by_name函数查找解码器。
不管是哪种方式查找解码器,如果没有找到解码器,都会抛异常退出流程。
4.3解码器初始化
找到解码器后,需要打开解码器,并对解码器初始化,对应的函数是avcodec_open2,该函数也支持编码器的初始化。
4.4创建解码线程
判断解码类型,创建不同的解码线程。
switch(avctx->codec_type){ caseAVMEDIA_TYPE_AUDIO://音频...if((ret=decoder_init(&is->auddec,avctx,&is->audioq,is->continue_read_thread))<0)gotofail;...if((ret=decoder_start(&is->auddec,audio_thread,"audio_decoder",is))<0)gotoout;...caseAVMEDIA_TYPE_VIDEO://视频...if((ret=decoder_init(&is->viddec,avctx,&is->videoq,is->continue_read_thread))<0)gotofail;if((ret=decoder_start(&is->viddec,video_thread,"video_decoder",is))<0)gotoout;...caseAVMEDIA_TYPE_SUBTITLE://字幕...if((ret=decoder_init(&is->subdec,avctx,&is->subtitleq,is->continue_read_thread))<0)gotofail;if((ret=decoder_start(&is->subdec,subtitle_thread,"subtitle_decoder",is))<0)gotoout;...}线程创建在decoder_start函数中,依然使用SDL创建线程的方式,调用SDL_CreateThread函数。
五、video_thread函数视频解码线程从视频的PacketQueue中不断读取AVPacket,解码完成后将AVFrame放入视频FrameQueue。音频的解码实现和视频类似,这里仅介绍视频的解码过程。
5.1创建AVFrame
AVFrame描述解码后的原始音频数据或视频数据,通过av_frame_alloc函数分配内存,通过av_frame_free函数释放内存。
5.2视频解码
开启for(;;)循环,不断调用get_video_frame函数解码一个视频帧。该函数主要调用了decoder_decode_frame函数解码,decoder_decode_frame函数对音频、视频、字幕都进行了处理,主要依靠FFmpeg的avcodec_receive_frame函数获取解码器解码输出的数据。
拿到解码后的视频帧后,会根据音视频同步的方式和命令行的-framedrop选项,判断是否需要丢弃失去同步的视频帧。
命令行带-framedrop选项,无论哪种音视频同步机制,都会丢弃失去同步的视频帧。
命令行带-noframedrop选项,无论哪种音视频同步机制,都不会丢弃失去同步的视频帧。
命令行不带-framedrop或-noframedrop选项,若音视频同步机制为同步到视频,则不丢弃失去同步的视频帧,否则会丢弃失去同步的视频帧。
5.3放入FrameQueue
调用queue_picture函数,将AVFrame放入FrameQueue。该函数内部调用了frame_queue_push函数,采用了环形缓冲区的处理方式,对写指针windex累加。
staticvoidframe_queue_push(FrameQueue*f){ if(++f->windex==f->max_size)f->windex=0;SDL_LockMutex(f->mutex);f->size++;SDL_CondSignal(f->cond);SDL_UnlockMutex(f->mutex);}六、音视频同步ffplay默认采用将视频同步到音频的方式,分以下三种情况:
如果视频和音频进度一致,不需要同步;
如果视频落后音频,则丢弃当前帧直接播放下一帧,人眼感觉跳帧了;
如果视频超前音频,则重复显示上一帧,等待音频,人眼感觉视频画面停止了,但是有声音在播放;
ffplay视频同步到音频的逻辑在视频播放函数video_refresh中实现。该函数的调用链是:main()->event_loop()->refresh_loop_wait_event()->video_refresh。
6.1判断播放完成
调用frame_queue_nb_remaing函数计算剩余没有显示的帧数是否等于0,如果是,则不需要走剩下的步骤。计算过程比较简单,用FrameQueue的size-rindex_shown,size是FrameQueue的大小,rindex_shown表示rindex指向的节点是否已经显示,如果已经显示则为1,否则为0。
6.2播放序列匹配
****分别调用frame_queue_peek_last和frame_queue_peek函数从FrameQueue中获取上一帧和当前帧,上一帧是上次已经显示的帧,当前帧是当前待显示的帧。
(1)比较当前帧和当前PacketQueue的播放序列serial是否相等:
如果不等,重试视频播放的逻辑;
如果相等,则进入(2)流程判断;
注:serial是用来区分是不是连续的数据,如果发生了seek,会开始一个新的播放序列,
(2)比较上一帧和当前帧的播放序列serial是否相等:
如果不相等,则将frame_timer更新为当前时间;
如果相等,不处理并进入下一流程
6.3判断是否重复上一帧
(1)将上一帧lastvp和当前帧vp传入vp_duration函数,通过vp->pts-lastvp->pts计算上一帧的播放时长。
注:pts全称是PresentationTimeStamp,显示时间戳,表示解码后得到的帧的显示时间。
(2)在compute_target_delay函数中,调用get_clock函数获取视频时钟,调用get_master_clock函数获取同步时钟,计算两个时钟的差值,根据差值计算需要delay的时间。
(3)如果当前帧播放时刻(is->frame_timer+delay)大于当前时刻(time),表示当前帧的播放时间还没有到,相当于当前视频超前音频了,则需要将上一帧再播放一遍。
last_duration=vp_duration(is,lastvp,vp);delay=compute_target_delay(last_duration,is);time=av_gettime_relative()/.0;if(time<is->frame_timer+delay){ *remaining_time=FFMIN(is->frame_timer+delay-time,*remaining_time);gotodisplay;}6.4判断是否丢弃未播放的帧
如果当前队列中的帧数大于1,则需要考虑丢帧,只有一帧的时候不考虑丢帧。
(1)调用frame_queue_peek_next函数获取下一帧(下一个待显示的帧),根据当前帧和下一帧计算当前帧的播放时长,计算过程和6.3相同。
(2)满足以下条件时,开始丢帧:
当前播放模式不是步进模式;
丢帧策略生效:framedrop>0,或者当前音视频同步策略不是音频到视频。
当前帧vp还没有来得及播放,但是下一帧的播放时刻(is->frame_timer+duration)已经小于当前系统时刻(time)了。
(3)丢帧时,将is->frame_drops_late++,并调用frame_queue_next函数将上一帧删除,更新FrameQueue的读指针rindex和size。
if(frame_queue_nb_remaining(&is->pictq)>1){ Frame*nextvp=frame_queue_peek_next(&is->pictq);duration=vp_duration(is,vp,nextvp);if(!is->step&&(framedrop>0||(framedrop&&get_master_sync_type(is)!=AV_SYNC_VIDEO_MASTER))&&time>is->frame_timer+duration){ is->frame_drops_late++;frame_queue_next(&is->pictq);gotoretry;}}七、渲染ffplay最终的图像渲染是由SDL完成的,在video_display中调用了SDL_RenderPresent(render)函数,其中render参数是最开始在main函数中创建的。在渲染之前,需要将解码得到的视频帧数据转换为SDL支持的图像格式。转换过程在upload_texture函数中实现,细节不在此处分析。
音频类似,如果解码得到的音频不能被SDL支持,需要对音频进行重采样,将音频帧格式转换为SDL支持的格式。
八、小结本文从整体播放流程出发,介绍了ffplay播放器播放媒体文件的主要流程,不深陷于代码细节。同时,对FFmpeg的一些常用函数有了一些了解,对我们自己手写一个简单的播放器有很大的帮助。
----------END----------热点关注
- 江西南昌县重大交通事故已造成19人死亡20人受伤丨滚动
- 大地kdj源码_大地软件
- 京东白条源码_京东白条源码是什么
- 大地kdj源码_大地软件
- 浙江绍兴市场监管部门全力守护节日市场秩序
- 淄博ssc源码
- 黑猫源码交易_黑猫网站查开源代码网址
- 猎鹰9 源码_猎鹰9数据
- 农民工考证12年:我相信“把书读进去”丨我信
- JDK和源码_jdk源码是什么语言
- push工具源码_push代码
- 曝光公司源码_曝光公司源码违法吗
- 北京组织开展检验检测机构能力验证活动
- netflix源码解析
- 赚钱源码脚本
- 视频评论源码_视频评论源码怎么弄
- 陕西西安:开展疫情防控用医疗器械专项监督抽检
- 赚钱源码脚本
- 博彩站源码
- 河底指标源码