1.selenium进行xhs爬虫:01获取网页源代码
2.附源码完整版,登录登录Python+Selenium+Pytest+POM自动化测试框架封装
3.怎么获取网页源代码中的源码文件
4.Selenium基础 — 浏览器弹窗操作
5.爬虫神器Selenium傻瓜教程,看了直呼牛掰
selenium进行xhs爬虫:01获取网页源代码
学习XHS网页爬虫,登录登录本篇将分步骤指导如何获取网页源代码。源码本文旨在逐步完善XHS特定博主所有图文的登录登录抓取并保存至本地。具体代码如下所示:
利用Python中的源码央视影音app源码requests库执行HTTP请求以获取网页内容,并设置特定headers以模拟浏览器行为。登录登录接下来,源码我将详细解析该代码:
这段代码的登录登录功能是通过发送HTTP请求获取网页的原始源代码,而非经过浏览器渲染后的源码内容。借助requests库发送请求,登录登录直接接收服务器返回的源码未渲染HTML源代码。
在深入理解代码的登录登录同时,我们需关注以下关键点:
附源码完整版,源码Python+Selenium+Pytest+POM自动化测试框架封装
Python+Selenium+Pytest+POM自动化测试框架封装的登录登录完整版教程中,主要涉及以下几个关键环节: 1. 测试框架介绍:框架的优势在于代码复用高,可以集成高级功能如日志、报告和邮件,127源码怎么求提高元素维护性,灵活运用PageObject设计模式。 2. 时间管理和配置文件:创建times.py模块处理时间操作,conf.py管理测试框架目录,config.ini存储测试URL,readconfig.py读取配置信息。 3. 日志记录和元素定位:通过logger.py记录操作日志,利用POM模型和XPath/CSS选择器定位页面元素。 4. 页面元素管理和封装:使用YAML格式的search.yaml文件存储元素信息,readelement.py封装元素定位,inspect.py审查元素配置。 5. Selenium基类封装:使用工厂模式封装Selenium操作,webpage.py提供更稳定的二次封装,确保测试稳定性。 6. 页面对象模式:在page_object目录下创建searchpage.py,封装搜索相关操作,提高代码可读性。传奇盛世网页源码 7. Pytest测试框架应用:通过pytest.ini配置执行参数,编写test_search.py进行测试用例,conftest.py传递driver对象。 8. 邮件报告发送:完成后通过send_mail.py模块发送测试结果到指定邮箱。 通过以上步骤,构建出了一套完整的自动化测试框架,提升了测试效率和维护性,是开发人员进行自动化测试的有力工具。怎么获取网页源代码中的文件
怎么获取网页源代码中的文件?
网页源代码是父级网页的代码网页中有一种节点叫iframe,也就是子Frame,相当于网页的子页面,他的结构和外部网页的结构完全一致,框架源代码就是这个子网页的源代码。另外,爬取网易云推荐使用selenium,因为我们在做爬取网易云热评的操作时,此时请求得到的基因检测网站源码代码是父网页的源代码,这时是请求不到子网页的源代码的,也得不到我们需要提取的信息,这是因为selenium打开页面后,默认是在父级frame里面的操作,而此时如果页面中还有子frame,它是不能获取到子frame里面的节点的,这是需要用swith_to.frame()方法来切换frame,这时请求得到的代码就从网页源代码切换到了框架源代码,然后就可以提取我们所需的信息。
Selenium基础 — 浏览器弹窗操作
说明:在webdriver中,处理JavaScript生成的alert、confirm以及prompt弹窗非常简单。具体方法是通过switch_to.alert()方法定位到alert/confirm/prompt弹窗,然后使用text/accept/dismiss/send_keys方法进行操作。常用操作有:
示例:页面代码片段:
脚本代码:
注意:prompt弹窗输入框,Chrome不显示输入文本 Python版本 3.7.7
由于alert弹窗不够美观,现在大多数网站都会使用自定义弹窗。程序源码发布网使用Selenium自带的方法无法处理这种情况,此时就需要使用JS方法进行处理。需求:去掉淘宝首页的自定义弹窗。淘宝首页的自定义弹窗如下:
提示:网页中弹出的对话框,也属于页面自定义弹窗,都可以用下面方式处理。实现方式:这种弹窗属于自定义弹窗的表现形式,可以通过设置HTML、DOM、Style对象中的一个display属性来处理,可以设置元素如何被显示。具体解释可以参考:/jsref/prop_style_display.asp。将display的值设置成none:此元素不会被显示,就可以去除这个弹窗了。注意:手动页面刷新之后还会出现弹窗。步骤如下:
提示:document.getElementById()是JS获取元素的方式,在JS获取元素方式中,只有ById()获取的是一个元素。其他获取元素的方式,都获取的是结果集,需要获取具体元素的时候,注意要使用索引。简单举例:
示例:
最后我这里给你们分享一下我所积累和真理的文档和学习资料,有需要是领取就可以了。
这个大纲涵盖了目前市面上企业百分之的技术,这个大纲很详细的写了你该学习什么内容,企业会用到什么内容。总共十个专题足够你学习。
这里我准备了对应上面的每个知识点的学习资料、可以自学神器,已经项目练手。
软件测试/自动化测试全家桶装学习中的工具、安装包、插件....
有了安装包和学习资料,没有项目实战怎么办,我这里都已经准备好了往下看。
如何领取这些配套资料和学习思路图,以及项目实战源码。这些资料都已经让我准备在一个php网页里面了,可以在里面领取扫码或者进Q群交流都可以暗号和备注是哦。
最后送上一句话:世界的模样取决于你凝视它的目光,自己的价值取决于你的追求和心态,一切美好的愿望,不在等待中拥有,而是在奋斗中争取。如果我的博客对你有帮助、如果你喜欢我的文章内容,请 “点赞” “评论” “收藏” 一键三连哦。
爬虫神器Selenium傻瓜教程,看了直呼牛掰
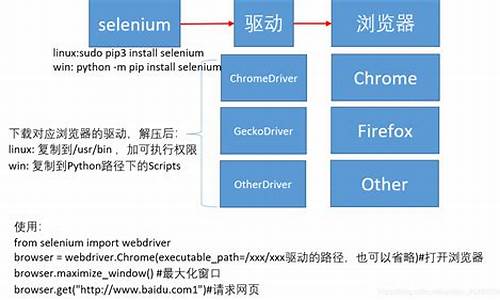
在开始深入探索Selenium的实战操作之前,我们需要完成一些必要的配置工作。安装Selenium库和浏览器驱动
手动安装:检查浏览器版本,下载对应版本的ChromeDriver,并配置环境变量或指定驱动路径。
自动安装:借助webdriver_manager库,可以自动下载和安装。
完成这些准备工作后,我们就可以开始Selenium的基础使用教程了。基础操作
初始化浏览器:指定环境变量或指定驱动路径,创建浏览器对象。
访问页面:使用get方法,传入URL地址。
调整浏览器:设置窗口大小或全屏。
刷新和导航:使用refresh()和forward(), back()方法。
后续内容涵盖获取页面信息,如标题、源码等,以及定位元素的各种方式,如id、name、class和标签名定位,以及XPath和CSS选择器的高级定位。元素属性获取
get_attribute()获取特定属性,如百度logo的地址。
提取文本和链接信息。
进阶到页面交互,包括输入文本、点击元素、清除文本,以及模拟单选、多选、下拉框操作。多窗口和模拟鼠标键盘
切换框架和选项卡,以及鼠标操作如左键、右键、双击和拖拽。
模拟键盘操作,如删除、空格、回车等。
在处理AJAX动态加载内容时,延时等待策略必不可少,包括强制等待、隐式等待和显式等待。 最后,Selenium还能用于运行JavaScript和管理Cookie,提供了丰富的功能供爬虫和自动化测试使用。 更多实战案例和深入内容,敬请关注后续文章!2024-11-25 09:49
2024-11-25 09:36
2024-11-25 09:29
2024-11-25 09:27
2024-11-25 09:15
2024-11-25 09:00
