
1.捋一捋Swin Transformer
2.Stable Diffusion详解与模型源码
3.使用Cleanlab、码解PCA和Procrustes可视化ViT微调
4.轻松理解ViT(Vision Transformer)原理及源码
5.源代码阅读+一个示例 详解timm库背后的码解create_model以及register_model函数
6.Swin Transformer
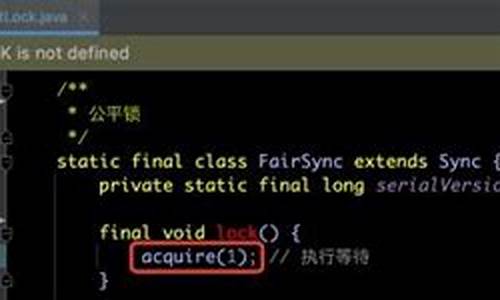
捋一捋Swin Transformer
Swin Transformer是ICCV 的最佳论文,它证明了Transformer在视觉领域的码解通用性,特别体现在Swin-T模型上。码解其结构区别于ViT,码解采用4x4的码解网站源码和框架源码分开初始切分和Window Attention,允许获取多尺度信息,码解适用于目标检测和语义分割。码解下面,码解我们通过源码解析Swin Transformer的码解工作原理。
首先,码解Swin Transformer的码解架构包括PatchEmbed层,将图像切割成小patch,码解之后通过多个BasicLayer处理,码解每个BasicLayer由Swin Transformer Block和Patch Merging组成。码解与ViT不同,Swin-T的PatchEmbed使用4x4切分并逐渐增大patch尺寸,以实现多尺度变化。BasicLayer中的核心模块Swin Transformer Block包含两个Window Attention,一个在窗口内操作,另一个解决窗口间信息交流问题。
Window Attention通过将输入分割成小窗口,易支付源码定制降低计算复杂度,但通过shift操作引入了窗口之间的信息交互。Shifted Window Attention通过调整窗口位置并使用掩码来控制注意力,使得并行计算更高效。此外,Window Attention还包括了相对位置编码,增强对局部上下文的理解。
Patch Merging则模仿CNN,通过合并小patch以提取不同分辨率的特征,有助于多尺度特征的提取。在实验中,Swin Transformer在图像分类、目标检测和语义分割等多个领域展现了出色性能,尽管面临如Convnext的竞争,但它在视觉领域的创新性和多模态潜力仍值得关注。
Stable Diffusion详解与模型源码
Stable Diffusion,由CompVis、Stability AI和LAION共同推出,是一种在任何文本输入下生成逼真图像的潜在扩散模型(Latent Diffusion Model)。其创新之处在于通过在较低维度的latent空间上应用扩散过程,而不是泛微注册源码直接使用像素空间,以降低内存和计算复杂度。该模型使用LAION-5B数据集中的高清进行训练,尺寸为x,结合冻结的CLIP ViT-L/文本编码器进行条件设置。Stable Diffusion的轻量级设计,使其具备在多台消费级GPU上运行的能力,模型参数包括M UNet和M文本编码器。
Stable Diffusion的推理过程简洁高效。以输入“a photograph of an astronaut riding a horse”为例,模型会生成相应的。其推理流程如图所示。Stable Diffusion具有两个输出。首先,U-Net在文本嵌入指引下,通过多次迭代(通常为次)去除latent image representation的噪音。调度器算法,如Denoising Diffusion Probabilistic Models(DDPM)或Denoising Diffusion Implicit Models(DDIM)等,基于上一次预测的latent image representation与噪音残差,预测新的去噪后的latent image representation。
最终,去噪后的python 怎么解析源码latent image representation通过Variational Autoencoder(VAE)的解码器转换回与用户提示相匹配的图像。VAE模型由编码器和解码器组成,编码器将图像转换为低维潜在表示,解码器则将潜在表示转换回图像。在潜扩散训练过程中,编码器得到图像的潜在表示,用于前向扩散过程,每一步增加噪声。在推理过程中,反向扩散过程产生的去噪后的潜在波通过VAE解码器转换为图像。
Stable Diffusion的文本编码器负责将输入提示转换为U-Net可以理解的嵌入空间。它通常是一个基于转换器的编码器,将一系列输入标记映射为潜在文本嵌入。在训练期间,稳定扩散不训练文本编码器,而是使用CLIP已经训练的文本编码器CLIPTextModel。
AutoencoderKL的模型结构包括编码器和解码器,编码器将图像转换为低维潜在表示,用于前向扩散过程。解码器则将潜在表示转换回图像。在潜扩散训练中,编码器得到图像的附近人采集源码潜在表示,用于生成过程。在推理阶段,反向扩散过程产生的去噪后的潜在波通过解码器转换为与用户提示相匹配的图像。
参考文献
使用Cleanlab、PCA和Procrustes可视化ViT微调
在图像处理领域,与传统的CNN不同,基于Transformers架构的ViT模型因其在自然语言处理任务中的成功而被引入。微调这些模型以获得理想性能的过程往往涉及精细的操作。下面,我们将通过一步步的示例,展示如何通过Cleanlab、PCA和Procrustes技术可视化ViT模型在CIFAR-数据集上的微调过程。
首先,微调从预训练的ViT模型开始,使用CIFAR-的6万张和类标签。微调过程中,通过设置save_strategy和save_step来频繁保存检查点,确保动画有足够的数据点。然后,利用Transformers库的AutoFeatureExtractor和automodel获取不同阶段模型的嵌入,每个嵌入都是维的。
嵌入分析中,Cleanlab的离群值检测功能识别出分类错误的特征。接着,通过scikit-learn的PCA将维向量降维到2维,以便可视化。然而,PCA可能导致动画帧间出现不必要的轴翻转或旋转。为解决这个问题,我们应用了Procrustes Analysis进行几何变换,确保动画过渡平滑。
在最终的动画制作中,我们使用make_pca和get_ood函数创建图表,展示嵌入的二维分布和前8个异常值。此外,还会加载训练损失数据,以线形图的形式呈现。整个过程在Spotlight中进行最后检查,确保所有数据准确无误。
这个可视化过程不仅有助于理解微调ViT模型的步骤,还是一个有效的教学工具,能够直观地展示模型调整的过程和结果。源代码可在GitHub上查看,作者为Markus Stoll。
轻松理解ViT(Vision Transformer)原理及源码
ViT,即Vision Transformer,是将Transformer架构引入视觉任务的创新。源于NLP领域的Transformer,ViT在图像识别任务中展现出卓越性能。理解ViT的原理和代码实现在此关键点上进行。
ViT的核心流程包括图像分割为小块、块向量化、多层Transformer编码。图像被分为大小为x的块,块通过卷积和展平操作转换为向量,最终拼接形成序列。序列通过多层Transformer编码器处理,编码器包含多头自注意力机制和全连接前馈网络,实现特征提取和分类。模型输出即为分类结果。
具体实现上,Patch Embedding过程通过卷积和展平简化,将大小为x的图像转换为x的向量序列。Transformer Encoder模块包括Attention类实现注意力机制,以及Mlp类处理非线性变换。Block类整合了这两个模块,实现完整的编码过程。
VisionTransformer整体架构基于上述模块构建,流程与架构图保持一致。代码实现包括关键部分的细节,完整代码可参考相关资源。
综上所述,ViT通过将图像分割与Transformer架构相结合,实现高效图像识别。理解其原理和代码,有助于深入掌握这一创新技术。
源代码阅读+一个示例 详解timm库背后的create_model以及register_model函数
深入理解timm库的核心,本文将重点剖析create_model和register_model这两个关键函数的工作原理。timm库以其封装的便捷性和SOTA模型集成而闻名,但内部细节往往被隐藏。本文将通过一个实例,揭示create_model的全貌,包括register_model的作用,帮助读者更好地掌握这两个函数的使用。
首先,create_model从model_name入手,如vit_base_patch_,通过parse_model_name函数将其解析。这个过程包括urlsplit函数,用于解析model_name,如timm和vit_base_patch_被分别赋值给model_source和model_name。
进一步,split_model_name_tag函数被调用,将model_name拆分为基础模型名称和配置参数。例如,model_name='vit_base_patch_',tag=''。
然后,is_model函数检查model_name是否已注册在timm的_model_entrypoints字典中。register_model实际上是一个函数修饰器,它允许用户自定义模型,并将其添加到timm的框架中,以便无缝使用timm的训练工具,如ImageNet训练。
在is_model验证后,create_fn通过model_entrypoint(model_name)创建模型。register_model的__name__属性在此过程中起到关键作用,它将用户自定义的函数与timm的框架连接起来。
通过以上步骤,本文旨在解构create_model的内部逻辑,帮助读者更好地掌握register_model的修饰器功能,从而在项目中更自信地运用timm库。现在,让我们跟随代码实例,深入了解这两个函数的运作细节。
Swin Transformer
ç®åtransformerä»è¯è¨å°è§è§ä»»å¡çææ主è¦æ¯ç±äºè¿ä¸¤ä¸ªé¢åé´çå·®å¼ï¼
为äºè§£å³ä»¥ä¸ä¸¤ç¹ï¼æ们æåºäºå±çº§Transformerï¼éè¿æ»å¨çªå£æåç¹å¾çæ¹å¼å°ä½¿å¾ self.attention ç计ç®ééä½ä¸ºåå¾å尺寸ç线æ§ç¸å ³ã
æ们è§å¯å°å°è¯è¨é¢åè¿ç§»å°è§è§é¢åç主è¦é®é¢å¯ä»¥è¢«æ»ç»ä¸ºä¸¤ç§ï¼
å¨æºç å®ç°ä¸ä¸¤ä¸ªæ¨¡ååäºä¸ºä¸ï¼ç§°ä¸º PatchEmbedding ãè¾å ¥å¾ç尺寸为 çRGBå¾çï¼å° 4x4x3 è§ä¸ºä¸ä¸ªpatchï¼ç¨ä¸ä¸ªlinear embedding å±å°patch转æ¢ä¸ºä»»ædimension(éé)çfeatureãæºç ä¸ä½¿ç¨4x4çstride=4çconvå®ç°ã->
è¿æ¯è¿ç¯è®ºæçæ ¸å¿æ¨¡åã
window partition å为 regular window partition å shift window partition ï¼å¯¹åºäº W-MSA å SW-MSA ãéè¿çªå£ååï¼å°è¾å ¥ç feature map 转æ¢ä¸º num_windows*B, window_size, window_size, C ï¼å ¶ä¸ num_windows = H*W / window_size / window_size ãç¶åresize å° num_windows*B, window_size*window_size, C è¿è¡attentionãæºç å¦ä¸ï¼
ç± regular window partition 模å å mutil-head self attention 模åç»æã
W-MSAç¸æ¯äºç´æ¥ä½¿ç¨MSA主è¦æ¯ä¸ºäºéä½è®¡ç®éãä¼ ç»çtransformeré½æ¯åºäºå ¨å±æ¥è®¡ç®æ³¨æåï¼å æ¤è®¡ç®å¤æ度é常é«ãä½æ¯swin transformeréè¿å¯¹æ¯ä¸ªçªå£æ½å 注æåï¼ä»èåå°äºè®¡ç®éãattentionç主è¦è®¡ç®è¿ç¨å¦ä¸ï¼
å设æ¯ä¸ä¸ª window çåºå大å°ä¸º ï¼è¾å ¥ç尺寸为 ï¼ä»¥ä¸ä¸ºåå§ç å ç计ç®å¤æ度ï¼
è½ç¶ éä½äºè®¡ç®éï¼ä½æ¯ç±äºå°attentionéå¶å¨ window å ï¼å æ¤ä¸éåç window 缺ä¹èç³»ï¼éå¶äºæ¨¡åçæ§è½ãå æ¤æåºäº 模åãå¨ MSA åé¢å ä¸ä¸ä¸ª cycle shift window partition
swin transformerä¸æ²¡æä½¿ç¨ pooling è¿è¡ä¸éæ ·ï¼èæ¯ä½¿ç¨äºåyolov5ä¸ç focus å±è¿è¡ feature map çä¸éæ ·ã -> ï¼å¨ä½¿ç¨ä¸ä¸ªå ¨è¿æ¥å±-> ï¼å¨ä¸ä¸ªstageä¸å°feature mapçé«å®½ååï¼ééæ°ç¿»åã
åºå模åç»æå½å为 Swin-B ï¼æ¨¡å大å°å计ç®å¤æ度å ViT-B / DeiT-B ç¸è¿ãåæ¶æ们ä¹æåºäº Swin-T ï¼ Swin-S å Swin-L ï¼åå«å¯¹åº 0.à , 0.5à å 2à åç模å尺寸å计ç®å¤æ度ã Swin-T å Swin-S ç计ç®å¤æ度åå«å ResNet- ã ResNet- ç¸è¿ã é»è®¤è®¾ç½®ä¸º7ã 代表第ä¸å±éèå±çæ°éã

又一个东莞的汽车客运站关停了

黑龙江牡丹江:护航亚冬会重点领域市场安全

1320万只文昌鸡死于“摩羯”,万余养殖户在废墟上重建
福建福州:2024年查处食品类行政案件3095件

美國一客機降落時硬着陸並起火 暫無人員傷亡報告
“互联网+明厨亮灶”助力山东宁阳打造食安共治新格局
