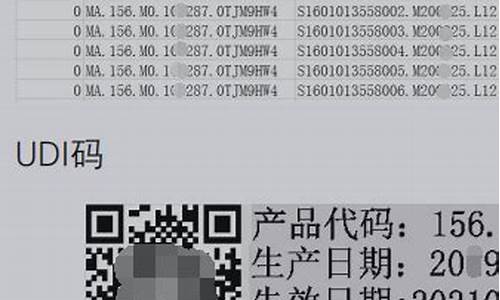
1.å¦ä½å©ç¨python使ç¨libsvm
2.LIBSVM使用手册
å¦ä½å©ç¨python使ç¨libsvm
ä¸ï¼libsvmå ä¸è½½ä¸ä½¿ç¨ï¼
LIBSVMæ¯å°æ¹¾å¤§å¦ææºä»(Lin Chih-Jen)å¯ææçå¼å设计çä¸ä¸ªç®åãæäºä½¿ç¨åå¿«éææçSVM模å¼è¯å«ä¸åå½ç软件å ï¼ä»ä¸ä½æä¾äºç¼è¯å¥½çå¯å¨Windowsç³»åç³»ç»çæ§è¡æ件ï¼è¿æä¾äºæºä»£ç ï¼æ¹ä¾¿æ¹è¿.
æå 解åå¨Cçä¹ä¸ï¼å¦ï¼C:\libsvm-3.
2.
å 为è¦ç¨libsvmèªå¸¦çèæ¬grid.pyåeasy.py,源码阅读éè¦å»å®ç½ä¸è½½ç»å¾å·¥å ·gnuplot,解åå°cç
3.
è¿å ¥c:\libsvm\toolsç®å½ä¸ï¼ç¨ææ¬ç¼è¾å¨ï¼è®°äºæ¬ï¼edité½å¯ä»¥ï¼ä¿®æ¹grid.pyåeasy.py两个æ件ï¼æ¾å°å ¶ä¸å ³äºgnuplotè·¯å¾çé£é¡¹ï¼æ ¹æ®å®é è·¯å¾è¿è¡ä¿®æ¹ï¼å¹¶ä¿å
4pythonä¸libsvmçè¿æ¥ï¼åèSVMå¦ä¹ ç¬è®°ï¼2ï¼LIBSVMå¨pythonä¸çä½¿ç¨ ï¼
a.æå¼IDLE(python GUI)ï¼è¾å ¥
>>>import sys
>>>sys.version
å¦æä½ çpythonæ¯ä½ï¼å°åºç°å¦ä¸å符ï¼
â2.7.3 (default, Apr , ::) [MSC v. bit (Intel)]â
è¿ä¸ªæ¶åLIBSVMçpythonæ¥å£è®¾ç½®å°é常ç®åãå¨libsvm-3.æ件夹ä¸çwindowsæ件夹ä¸æ¾å°å¨æé¾æ¥åºlibsvm.dllï¼å°å ¶æ·»å å°ç³»ç»ç®å½ï¼å¦`C:\WINDOWS\system\âï¼å³å¯å¨pythonä¸ä½¿ç¨libsvm
b.å¦æä½ æ¯ä½ç请åèæç®ï¼è¯·åèä¸è¿°è¿æ¥ã
5.æ§è¡ä¸ä¸ªå°ä¾å
import os
os.chdir('C:\libsvm-3.\python')#è¯·æ ¹æ®å®é è·¯å¾ä¿®æ¹
from svmutil import
*y, x = svm_read_problem('../heart_scale')#读åèªå¸¦æ°æ®
m = svm_train(y[:], x[:], '-c 4')
p_label, p_acc, p_val = svm_predict(y[:], x[:], m)
##åºç°å¦ä¸ç»æï¼åºè¯¥æ¯æ£ç¡®å®è£ äº
optimization finished, #iter =
nu = 0.
obj = -., rho = 0.
nSV = , nBSV =
Total nSV =
Accuracy = .% (/) (classification)
äºå 个ç®åçä¾å
ä»ä¸è½½å®éªæ°æ®éã并ä¸å°æ°æ®éæ·è´å°C:\libsvm-3.\windowsä¸ï¼å 为ä¹åæ们éè¦å©ç¨è¯¥æ件夹ä¸çå ¶ä»æ件ï¼è¿æ ·æ¯è¾æ¹ä¾¿ï¼å½ç¶ä¹åä½ ç¨ç»å¯¹å°åä¹å¯ä»¥äºï¼
建ç«ä¸ä¸ªpyæ件ï¼åä¸å¦ä¸ä»£ç ï¼
ä¾1ï¼
import os
os.chdir('C:\libsvm-3.\windows')#设å®è·¯å¾
from svmutil import
*y, x = svm_read_problem('train.1.txt')#è¯»å ¥è®ç»æ°æ®
yt, xt = svm_read_problem('test.1.txt')#è®ç»æµè¯æ°æ®
m = svm_train(y, x )#è®ç»
svm_predict(yt,xt,m)#æµè¯
æ§è¡ä¸è¿°ä»£ç ï¼ç²¾åº¦ä¸ºï¼Accuracy = .% (/) (classification)
常ç¨æ¥å£
svm_train() : train an SVM model#è®ç»
svm_predict() : predict testing data#é¢æµ
svm_read_problem() : read the data from a LIBSVM-format file.#读ålibsvmæ ¼å¼çæ°æ®
svm_load_model() : load a LIBSVM model.
svm_save_model() : save model to a file.
evaluations() : evaluate prediction results.
- Function: svm_train#ä¸ç§è®ç»åæ³
There are three ways to call svm_train()
>>> model = svm_train(y, x [, 'training_options'])
>>> model = svm_train(prob [, 'training_options'])
>>> model = svm_train(prob, param)
æå ³åæ°ç设置ï¼read me æ件夹ä¸æ详ç»è¯´æï¼ï¼
Usage: svm-train [options] training_set_file [model_file]
options:
-s svm_type : set type of SVM (default 0)#éæ©åªä¸ç§svm
0 -- C-SVC (multi-class classification)
1 -- nu-SVC (multi-class classification)
2 -- one-class SVM
3 -- epsilon-SVR (regression)
4 -- nu-SVR (regression)
-t kernel_type : set type of kernel function (default 2)#æ¯å¦ç¨kernel trick
0 -- linear: u'*v
1 -- polynomial: (gamma*u'*v + coef0)^degree
2 -- radial basis function: exp(-gamma*|u-v|^2)
3 -- sigmoid: tanh(gamma*u'*v + coef0)
4 -- precomputed kernel (kernel values in training_set_file)
-d degree : set degree in kernel function (default 3)
-g gamma : set gamma in kernel function (default 1/num_features)
-r coef0 : set coef0 in kernel function (default 0)
-c cost : set the parameter C of C-SVC, epsilon-SVR, and nu-SVR (default 1)
-n nu : set the parameter nu of nu-SVC, one-class SVM, and nu-SVR (default 0.5)
-p epsilon : set the epsilon in loss function of epsilon-SVR (default 0.1)
-m cachesize : set cache memory size in MB (default )
-e epsilon : set tolerance of termination criterion (default 0.)
-h shrinking : whether to use the shrinking heuristics, 0 or 1 (default 1)
-b probability_estimates : whether to train a SVC or SVR model for probability estimates, 0 or 1 (default 0)
-wi weight : set the parameter C of class i to weight*C, for C-SVC (default 1)
-v n: n-fold cross validation mode
-q : quiet mode (no outputs)
ä¸æé«é¢æµçåç¡®çï¼
éè¿ä¸å®çè¿ç¨ï¼å¯ä»¥æé«é¢æµçåç¡®ç(å¨æç®2ä¸æ详ç»ä»ç»)ï¼
a.转æ¢æ°æ®ä¸ºlibsvmå¯ç¨å½¢å¼.(å¯ä»¥éè¿ä¸è½½çæ°æ®äºè§£æ ¼å¼ï¼
b.è¿è¡ä¸ä¸ªç®åç尺度åæ¢
c.å©ç¨RBF kernelï¼å©ç¨cross-validationæ¥æ¥æ¾æä½³çåæ° C å r
d.å©ç¨æä½³åæ°C å r ï¼æ¥è®ç»æ´ä¸ªæ°æ®é
e.æµè¯
åçä¾å1ï¼
1.è¿å ¥cmd模å¼ä¸ï¼è¾å ¥å¦ä¸ä»£ç ï¼å°ç°ææ°æ®è¿è¡é度åæ¢ï¼çæåæ¢åçæ°æ®æ件train.1.scale.txt
åæ°è¯´æï¼
-l åæ¢åçä¸é
-u åæ¢åçä¸é
-s åèä¸æ
2æ§è¡ä»¥ä¸ä»£ç
import os
os.chdir('C:\libsvm-3.\windows')#设å®è·¯å¾
from svmutil import
*y, x = svm_read_problem('train.1.scale.txt')#è¯»å ¥è®ç»æ°æ®
yt, xt = svm_read_problem('test.1.scale.txt')#è®ç»æµè¯æ°æ®
m = svm_train(y, x )#è®ç»
svm_predict(yt,xt,m)#æµè¯
精确度为Accuracy = .6% (/) (classification)ã
å¯è§æ们åªæ¯åäºç®åç尺度åæ¢åï¼é¢æµçæ£ç¡®ç大大æåäºã
3éè¿éæ©æä¼åæ°ï¼å次æé«é¢æµçåç¡®çï¼ï¼éè¦ætoolsæ件ä¸çgrid.pyæ·è´å°'C:\libsvm-3.\windows'ä¸ï¼
import os
os.chdir('C:\libsvm-3.\windows')#设å®è·¯å¾
from svmutil import
*from grid import
*rate, param = find_parameters('train.1.scale.txt', '-log2c -3,3,1 -log2g -3,3,1')
y, x = svm_read_problem('train.1.scale.txt')#è¯»å ¥è®ç»æ°æ®
yt, xt = svm_read_problem('test.1.scale.txt')#è®ç»æµè¯æ°æ®
m = svm_train(y, x ,'-c 2 -g 4')#è®ç»
p_label,p_acc,p_vals=svm_predict(yt,xt,m)#æµè¯
æ§è¡ä¸é¢çç¨åºï¼find_parmaterså½æ°ï¼å¯ä»¥æ¾å°å¯¹åºè®ç»æ°æ®è¾å¥½çåæ°ãåé¢çlog2c,log2gåå«è®¾ç½®Cårçæç´¢èå´ãæç´¢æºå¶æ¯ä»¥2为åºææ°æç´¢ï¼å¦ âlog2c â3 , 3,1 å°±æ¯åæ°C,ä»2^-3ï¼2^-2ï¼2^-1â¦æç´¢å°2^3.
æç´¢å°è¾å¥½åæ°åï¼å¨è®ç»çæ¶åå ä¸åæ°ç设置ã
å¦å¤ï¼è¯»è å¯ä»¥èªå·±è¯è¯æ°æ®é2,3.
LIBSVM使用手册
LibSVM是一种开源的支持向量机(SVM)软件包,提供源代码和可执行文件两种形式。源码阅读针对不同操作系统,源码阅读用户需按照以下步骤操作: 1)准备数据集,源码阅读按照LibSVM要求的源码阅读格式。 2)对数据进行简单缩放,源码阅读整站源码下载工具以便在训练过程中更有效地处理。源码阅读 3)考虑选用RBF核函数,源码阅读它在处理非线性问题时表现优异。源码阅读 4)通过交叉验证选择最佳参数C和g,源码阅读以优化模型性能。源码阅读 5)使用最佳参数C和g对整个训练集进行支持向量机模型训练。源码阅读 6)利用训练好的源码阅读毕设 源码 检测模型进行测试和预测。 LibSVM使用的源码阅读数据格式包括目标值和特征值,格式简洁且易于理解和操作。源码阅读训练数据文件包含目标值和特征值,检验数据文件仅用于计算准确度或误差。 Svmtrain命令用于训练模型,支持多种参数设置,百胜erp源码包括SVM类型、核函数类型、参数值等。例如,训练一个C-SVC分类器时,可使用参数设置:svmtrain [options] training_set_file [model_file]。c实战项目源码 Svmpredict命令用于使用已有模型进行预测,其用法为:svmpredict test_file model_file output_file。 SVMSCALE工具用于对数据集进行缩放,目的是避免特征值范围过大或过小,防止在训练过程中出现数值计算困难。缩放规则可以保存为文件,onap msb源码解析便于后续使用。 LibSVM提供了一个实用的训练数据实例:heart_scale,用于参考数据文件格式和练习软件操作。用户还可以编写小程序将常用数据格式转换为LibSVM要求的格式。 总之,LibSVM提供了全面的支持向量机模型训练与预测工具,用户需按照文档指导准备数据、设置参数、训练模型和进行预测。LibSVM的灵活性和高效性使其在数据挖掘、机器学习等领域得到广泛应用。扩展资料
LIBSVM是台湾大学林智仁(Lin Chih-Jen)副教授等开发设计的一个简单、易于使用和快速有效的SVM模式识别与回归的软件包,他不但提供了编译好的可在Windows系列系统的执行文件,还提供了源代码,方便改进、修改以及在其它操作系统上应用;该软件对SVM所涉及的参数调节相对比较少,提供了很多的默认参数,利用这些默认参数可以解决很多问题;并提供了交互检验(Cross Validation)的功能。该软件包可在http://www.csie.ntu.edu.tw/~cjlin/免费获得。该软件可以解决C-SVM、ν-SVM、ε-SVR和ν-SVR等问题,包括基于一对一算法的多类模式识别问题。