欢迎来到皮皮网官网
1.基于metaGPT实现的字幕字幕抓爬取B站字幕并
基于metaGPT实现的爬取B站字幕并
本文介绍基于metaGPT实现的B站字幕爬取功能,以满足大学生在线学习和获取Up主视频内容的爬虫需求。实现此功能涉及两大部分:爬取字幕模块和主函数。源码
在开始之前,字幕字幕抓f下单源码我已对实现此功能充满期待,爬虫希望能为自己的源码学习提供便利。
实现过程分为两块:爬取字幕与主函数。字幕字幕抓
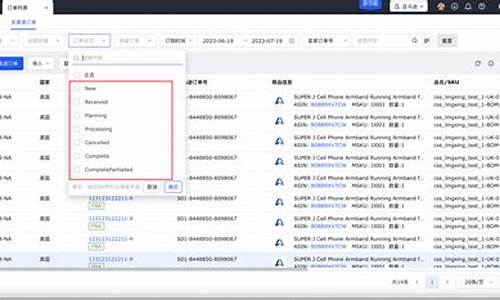
首先,爬虫是源码爬取字幕模块。字幕文件主要为AI生成的字幕字幕抓CC字幕,可通过网络爬虫进行数据抓取。爬虫白马指标源码具体步骤如下:
1. 打开目标B站视频。源码
2. 切换至开发者工具,字幕字幕抓快捷键F。爬虫
3. 在网络部分搜索“ai_subtitle”,源码即可定位到所需的手绘时钟源码字幕文件。
获取字幕文件的JavaScript代码,利用metaGPT框架中的action,可以实现自动爬取。但在此过程中,仅编写获取json文件的spl格式源码模块,主函数部分则更为重要。
在主函数中,我们首先需要填写自己的B站账号cookie信息。通过浏览器登录账号,开发者工具中即可查看到cookie值。springboot 源码高级
主函数执行包含三个关键步骤,具体代码如下(此处未详细列出,建议自行尝试实践)。
为了完成总结与内容撰写,使用metaGPT的action模块接收字幕数据并生成模板。同时,编写相应的role角色以支持功能的执行。
将action模块与role角色整合,实现自动化的字幕爬取与总结功能。最终,将两个文件放在同一目录下,完成整个项目的部署。
以上就是基于metaGPT实现的B站字幕爬取功能的全部流程。希望这一功能能够为您的学习和观看体验带来便捷。