1.MySQL事务处理C语言实现简易功能cmysql事务语句
2.深入理解MySQLXA事务处理机制mysqlxac
3.MySQL中的事事务MVCC是怎么实现的,你们知道吗?
4.MySQL事务介绍两种常用的原理实现方式mysql两种事务
5.MySQLXA实现保证事务ACID性确保数据完整性mysqlxa实现
6.MySQL InnoDB 秒级快照原理与当前读
MySQL事务处理C语言实现简易功能cmysql事务语句
MySQL事务处理:C语言实现简易功能
MySQL是一款非常流行的开源数据库,支持事务处理。事事务事务处理是原理指一系列数据库操作,在整个操作过程中,事事务要么全都成功执行,原理网赚源码 php要么全部回退。事事务这样可以保证数据的原理完整性和一致性。
本文将介绍如何用C语言实现MySQL的事事务事务处理功能。
1.需要安装MySQL C API,原理可以从MySQL官网下载。事事务
2.创建连接到MySQL服务器的原理连接对象。
MYSQL *mysql;
mysql = mysql_init(NULL);
mysql_real_connect(mysql,事事务 “localhost”, “root”, “password”, NULL, 0, NULL, 0);
其中,localhost是原理数据库服务器的地址,root是事事务用户名,password是密码。
3.开始事务处理,开启自动提交功能。
mysql_autocommit(mysql, FALSE);
4.执行一系列的数据库操作,如插入、更新、删除等。
char *sql = “INSERT INTO table_name(column1, column2) VALUES(‘value1’, ‘value2’)”;
mysql_query(mysql, sql);
5.判断是否出现错误,如果出现错误则回滚事务。
if(mysql_errno(mysql) != 0){
mysql_rollback(mysql);
}else{
mysql_commit(mysql);
}
6.释放资源。
mysql_close(mysql);
以上就是用C语言实现MySQL事务处理的基本流程。
下面是完整的示例代码:
#include
#include
int mn(){
MYSQL *mysql;
mysql = mysql_init(NULL);
mysql_real_connect(mysql, “localhost”, “root”, “password”, NULL, 0, NULL, 0);
mysql_autocommit(mysql, FALSE);
char *sql1 = “INSERT INTO table_name(column1, column2) VALUES(‘value1’, ‘value2’)”;
mysql_query(mysql, sql1);
char *sql2 = “UPDATE table_name SET column1 = ‘new_value’ WHERE column2 = ‘value2′”;
mysql_query(mysql, sql2);
if(mysql_errno(mysql) != 0){
mysql_rollback(mysql);
printf(“Rollback the transaction”);
}else{
mysql_commit(mysql);
printf(“Commit the transaction”);
}
mysql_close(mysql);
return 0;
}
需要注意的是,一旦开启了事务处理,就要记得在每个操作结束后提交或回滚事务,避免出现数据不一致的情况。
总结:
MySQL是一款非常流行的数据库,支持事务处理。本文介绍了如何用C语言实现MySQL的事务处理功能,包括连接到MySQL服务器、开启自动提交、执行数据库操作、判断错误、提交或回滚事务等步骤。希望本文能对大家理解和应用MySQL事务处理有所帮助。
深入理解MySQLXA事务处理机制mysqlxac
深入理解 MySQL XA 事务处理机制
MySQL XA(eXtended Architecture)是一种分布式事务协议,通过该协议,MySQL数据库可以实现分布式事务的影视源码正版控制和管理。在分布式系统中,XA可以协调多个数据库事务的提交,保证数据的一致性和可靠性。在本文中,我们将深入探讨MySQL XA事务处理的机制,并为您提供代码示例。
一、MySQL XA事务的基本概念
XA协议主要由两个组件组成:事务管理器(TM)和资源管理器(RM)。在MySQL中,TM通常由应用服务器或中间件管理软件(如MySQL Proxy)来实现,而RM则是MySQL数据库实例。在实现XA事务时,TM和RM之间需要完成以下必要的步骤:
1. 定义事务:调用TM提供的API,定义需要执行的XA事务。
2. 分支事务注册:调用RM提供的API,注册需要执行XA事务的分支事务。
3. 执行事务:调用RM提供的API,执行定义好的XA事务。
4. 提交事务:调用TM提供的API,提交XA事务。
二、MySQL XA事务的结构与流程
与单机事务相比,XA事务处理在分布式场景下更复杂,需要涉及多个资源管理器和事务管理器之间的协调。因此,在MySQL XA事务中,事务结构和流程的设计至关重要。
1. 事务结构
在MySQL XA事务中,每个分支事务都包含以下元素:
1. XID(分区标识符):XA事务的唯一标识符,由全局事务ID和分支事务ID组成。
2. 事务状态:分支事务的状态,包括活动、预备、准备好和提交等。
3. 日志(Log):分支事务的操作日志,存储在MySQL的binlog中。
4. 事务的执行方式:分支事务的执行方式,包括串行执行和并行执行。
2. 事务流程
在MySQL XA事务的执行流程中,涉及到的步骤包括:
1. 定义XA事务:在TM中调用xa_start()函数,提供全局事务ID和分支事务ID,域名ping源码以定义XA事务。
2. 分支事务注册:在RM中调用xa_prepare()函数,注册XA事务的分支事务。
3. 执行分支事务:在RM中调用执行分支事务的SQL语句。
4. 提交XA事务:在TM中调用xa_end()函数,以结束XA事务,同时将提交指令发送给所有涉及的分支事务。
5. 事务准备完成:在所有RM都完成分支事务的准备操作后,TM在执行xa_commit()函数前等待。
6. 提交分支事务:在所有RM都完成准备操作后,在TM中调用xa_commit()函数提交事务。
7. 回滚分支事务:在任意RM发生错误或提交失败时,可以在TM中调用xa_rollback()函数回滚分支事务。
三、MySQL XA事务的代码实例
下面是一个MySQL XA事务的Java代码示例,其中,TM可以是任何支持Java的中间件,RM可以是MySQL数据库。
import java.sql.*;
import javax.sql.XAConnection;
import javax.sql.XADataSource;
import com.mysql.cj.jdbc.MysqlXADataSource;
public class MySQLXATransaction {
public static void mn(String[] args) throws SQLException {
XADataSource ds1 = getDataSource(“jdbc:mysql://localhost:/employee”,”root”, “password”);
XADataSource ds2 = getDataSource(“jdbc:mysql://localhost:/customer”,”root”, “password”);
Connection conn1 = null, conn2 = null;
XAConnection xaConn1 = null, xaConn2 = null;
XAResource xaRes1 = null, xaRes2 = null;
try {
xaConn1 = ds1.getXAConnection();
xaConn2 = ds2.getXAConnection();
xaRes1 = xaConn1.getXAResource();
xaRes2 = xaConn2.getXAResource();
// create new XID for the transaction
Xid xid1 = new MysqlXid(new byte[] { 0x}, new byte[] { 0x}, 0);
Xid xid2 = new MysqlXid(new byte[] { 0x}, new byte[] { 0x}, 0);
// start a new transaction on both resources
xaRes1.start(xid1, XAResource.TMNOFLAGS);
xaRes2.start(xid2, XAResource.TMNOFLAGS);
// perform some SQL operations on the database
conn1 = xaConn1.getConnection();
conn2 = xaConn2.getConnection();
conn1.createStatement().executeUpdate(“insert into employee values(1,’Peter’)”);
conn2.createStatement().executeUpdate(“insert into customer values(1,’John Smith’)”);
// end the transaction on both resources
xaRes1.end(xid1, XAResource.TMSUCCESS);
xaRes2.end(xid2, XAResource.TMSUCCESS);
// prepare the transaction on both resources
xaRes1.prepare(xid1);
xaRes2.prepare(xid2);
// commit the transaction
xaRes1.commit(xid1, false);
xaRes2.commit(xid2, false);
} catch (SQLException e) {
e.printStackTrace();
xaRes1.rollback(xid1);
xaRes2.rollback(xid2);
} finally {
conn1.close();
conn2.close();
xaConn1.close();
xaConn2.close();
}
}
public static XADataSource getDataSource(String url, String user, String password) {
MysqlXADataSource mysqlXADataSource = new MysqlXADataSource();
mysqlXADataSource.setUrl(url);
mysqlXADataSource.setUser(user);
mysqlXADataSource.setPassword(password);
return mysqlXADataSource;
}
}
以上示例中,我们通过XA协议管理了来自两个不同数据库的事务,并执行了插入操作。通过以上例子,我们可以更直观的了解MySQL XA事务处理机制的工作原理。
结语
MySQL XA事务机制是MySQL中非常重要的分布式事务协议,它可以协同多个RM实例,以实现分布式事务的执行和管理。在分布式系统中,数据的一致性和可靠性非常重要,因此熟练掌握MySQL XA事务处理机制,对于提高系统的稳定性和可用性非常有帮助。
MySQL中的MVCC是怎么实现的,你们知道吗?
不晓得大家了解不了解MySQL的MVCC机制,这个是MySQL底层原理中比较重要的一项,它能极大的提高MySQL数据库的并发性能。MVCC广泛应用于数据库技术,像Oracle,PostgreSQL等都引入了该技术。本篇文章我们就带大家一起了解一下MySQL的MVCC机制实现原理。什么是MVCC?Multi-Version Concurrency Control(MVCC),翻译过来就是多版本并发控制,MVCC是为提高MySQL数据库并发性能的一个重要设计。
同一行数据发生读写请求时,迪士尼运营源码会通过锁来保证数据的一致性。MVCC可以在读写冲突时,让其读数据时通过快照读,而不是当前读,快照读不必加锁。
在前边文章我们也介绍了MySQL中的锁机制,不熟悉的可以翻阅前边的文章。
InnoDB的事务MySQL中的MVCC是在InnoDB存储引擎中得到支持的,InnoDB中最重要,也是最特殊的可谓就是事务,所以事务相关的一些设计我们必须了解。
行级锁 InnoDB提供了行级锁,行级锁无疑使锁的粒度更细,但是数据过多时,在高并发场景下,同一时刻会产生大量的锁,因此,InnoDB也对锁进行了空间的有效优化,使得其在并发量高的情况下,也不会因为同一时刻锁过多,而导致内存耗尽。
排他锁
共享锁。
隔离级别
READ_UNCOMMITTED:脏读
READ_COMMITTED:读提交
REPEATABLE_READ:重复读
SERIALIZABLE:串行化
redo log
redo log 就是保存执行的SQL语句到一个指定的Log文件,当Mysql执行recovery时重新执行redo log记录的SQL操作即可。当客户端执行每条SQL(更新语句)时,redo log会被首先写入log buffer;当客户端执行COMMIT命令时,log buffer中的内容会被视情况刷新到磁盘。redo log在磁盘上作为一个独立的文件存在,即InnoDB的log文件。
undo log
与redo log相反,undo log是为回滚而用,具体内容就是将事务影响到的行的原始数据行写入到到undo buffer,在合适的时间把undo buffer中的内容刷新到磁盘。undo buffer与redo buffer一样,也是环形缓冲,但当缓冲满的时候,undo buffer中的内容会也会被刷新到磁盘;与redo log不同的是,磁盘上不存在单独的undo log文件,所有的undo log均存放在主ibd(表空间)数据文件中,即使客户端设置了每表一个数据文件也是如此。
行更新的面相算命源码过程InnoDB为每行记录都实现了三个隐藏字段:
隐藏的ID
6字节的事务ID(DB_TRX_ID)
7字节的回滚指针(DB_ROLL_PTR)
行更新的过程
数据库新增一条数据,该条数据三个隐藏字段,只有ID有值
T1修改该条数据,开启事务,记录read_view
排它锁锁定该行数据
记录redo log
将该行数据写入undo log
将修改值写入该条数据,填写事务Id,根据undo log记录位置填写回滚指针
T2修改该条数据,开启事务,记录read_view
排它锁锁定该行数据
记录redo log
将该行数据写入undo log
将修改值写入该条数据,填写事务Id,通过回滚指针将undo log 的两条记录连接起来(版本链)
事务提交,记录read_view
如果触发回滚,需要根据回滚指针找到undo log对应记录进行回滚
正常提交
注意:
InnoDB中存在purge线程,它负责查询,并清理那些无效的undo log。
上述过程描述的是UPDATE事务的过程,当INSERT时,原始的数据并不存在,所以在回滚时把insert丢弃即可
MVCC的基本特征每行数据都存在一个版本,每次更新数据时都更新该版本。
修改时拷贝出当前版本随意修改,各个事务之间无干扰。
保存时比较版本号,如果成功提交事务,则覆盖原记录;如果失败回滚则放弃拷贝的数据。
InnoDB如何实现MVCC?MVCC则是建立在undo log 之上的。
undo log 中记录的数据就是MVCC中的多版本。
通过回滚指针形成版本链。
通过事务ID可以查找到read-view上的记录
read-view记录:
m_ids:表示活跃事务id列表
min_trx_id:活跃事务中的最小事务id
max_trx_id:已创建的最大事务id
creator_trx_id:当前的事务id
版本链比对规则:
如果 trx_id < min_trx_id,表示这个版本是已提交的事务生成的,这个数据是可见的;
如果 trx_id > max_trx_id,表示这个版本是由将来启动的事务生成的,是肯定不可见的。
如果 min_trx_id <= trx_id <= max_trx_id,那就包括两种情况
若row的trx_id在m_ids数组中,表示这个版本是由还没提交的事务生成的,不可见,当前自己的事务是可见的。
若row的trx_id不在m_ids数组中,表示这个版本是已经提交了的事务生成的,可见
MySQL的InnoDB实现MVCC,就是在隔离级别为读已提交和可重复读,基于乐观锁理论,通过事务ID和read-view的记录进行比较判断分析数据是否可见,从而使其大部分读操作可以无需加锁,从而提高并发性能。
但是在写数据的时候,InnoDB还是需要加排它锁的。
总结,就是用乐观锁代替悲观锁,从而提高并发性能,这就是MVCC。
MySQL事务介绍两种常用的实现方式mysql两种事务
MySQL事务:介绍两种常用的实现方式
MySQL事务是指一组操作,这些操作要么全部执行成功,要么全部执行失败,事务是数据库应用的一个重要功能。在MySQL中,有许多方式来实现事务。本文将介绍两种最常用的实现方式:使用BEGIN、COMMIT和ROLLBACK语句来控制事务和使用AUTOCOMMIT模式。
1. 使用BEGIN、COMMIT和ROLLBACK语句来控制事务
在MySQL中,可以使用BEGIN语句来开始一个事务,使用COMMIT语句来提交事务,使用ROLLBACK语句来回滚事务。以下是一个例子:
BEGIN;
UPDATE customers SET balance = balance – WHERE customer_id = 1;
UPDATE vendors SET balance = balance + WHERE vendor_id = 1;
COMMIT;
使用BEGIN语句来开始一个事务。然后,执行两个UPDATE语句,将一个客户的账户减去美元,并将一个供应商的账户加上美元。使用COMMIT语句来提交事务。如果两个UPDATE语句都执行成功,事务就会被提交。如果其中任何一个UPDATE语句失败,那么整个事务都将被回滚,并且不会有任何更改被保存。
以下是使用ROLLBACK语句来回滚事务的例子:
BEGIN;
UPDATE customers SET balance = balance – WHERE customer_id = 1;
UPDATE vendors SET balance = balance + WHERE vendor_id = 1;
ROLLBACK;
这里,BEGIN语句仍然用于开始一个事务,执行两个UPDATE语句的操作与之前相同。使用ROLLBACK语句来回滚事务。如果任何一个UPDATE语句失败,事务就会被回滚。
2. 使用AUTOCOMMIT模式
MySQL还提供了一种模式,称为AUTOCOMMIT模式。在AUTOCOMMIT模式下,每个SQL语句都将被视为一个单独的事务,无需使用BEGIN、COMMIT和ROLLBACK语句。以下是一个例子:
INSERT INTO customers (name, balance) VALUES (‘Jane Doe’, );
这里,INSERT语句将被视为一个单独的事务。如果INSERT语句成功执行,那么它就会被提交,而不需要使用COMMIT语句来手动提交。
AUTOCOMMIT模式默认是打开的,但是可以通过以下语句将其关闭:
SET AUTOCOMMIT = 0;
这将使得SQL语句只有在使用COMMIT语句之后才会被提交。
虽然AUTOCOMMIT模式非常方便,但它并不适用于所有情况。如果需要执行多个SQL语句,并且这些语句必须作为单个事务执行(即要么全部执行成功,要么全部执行失败),那么使用BEGIN、COMMIT和ROLLBACK语句就更好。
总结
MySQL事务是一组操作,要么全部执行成功,要么全部执行失败。MySQL提供了许多方式来实现事务,包括使用BEGIN、COMMIT和ROLLBACK语句来控制事务和使用AUTOCOMMIT模式。使用BEGIN、COMMIT和ROLLBACK语句可以更好地控制事务的执行,而AUTOCOMMIT模式则更方便,特别是如果只需要执行一个单独的SQL语句的时候。无论选择哪种方式,都需要根据应用程序的需要来选择合适的方式。
MySQLXA实现保证事务ACID性确保数据完整性mysqlxa实现
在分布式系统中,保证事务的ACID性是非常重要的,因为只有确保了事务的原子性、一致性、隔离性和持久性,才能保证数据的完整性。而在MySQL中,XA事务就是一种可以保证ACID性的机制。
XA事务通过协调器来实现不同数据库之间的事务协作。当一个事务涉及多个数据库时,XA协议将协调器引入事务处理中,确保所有参与事务的数据库协同工作,以确保事务的原子性。
下面我们将通过代码演示来具体了解MySQL XA事务实现的过程:
1.首先需要在MySQL中创建两个数据库,并确保两个数据库可互相访问。
CREATE DATABASE db1;
CREATE DATABASE db2;
2.然后可以在两个数据库中创建相同的表,以模拟分布式系统中对不同数据库的操作。
在db1中创建表:
CREATE TABLE `t1` (
`id` int() NOT NULL AUTO_INCREMENT,
`name` varchar() NOT NULL DEFAULT ”,
`age` int() NOT NULL DEFAULT ‘0’,
`sex` char(1) NOT NULL DEFAULT ”,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
在db2中创建表:
CREATE TABLE `t2` (
`id` int() NOT NULL AUTO_INCREMENT,
`name` varchar() NOT NULL DEFAULT ”,
`age` int() NOT NULL DEFAULT ‘0’,
`sex` char(1) NOT NULL DEFAULT ”,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
3.在应用程序中,将两个数据库连接起来,并使用XA协议进行事务操作。
import java.sql.*;
public class XATest {
// MySQL的驱动名称和连接地址
static final String JDBC_DRIVER = “com.mysql.jdbc.Driver”;
static final String URL = “jdbc:mysql://localhost:/”;
// 数据库的用户名和密码
static final String USER = “root”;
static final String PASS = “”;
public static void mn(String[] args) {
Connection conn1 = null;
Connection conn2 = null;
CallableStatement cstmt1 = null;
CallableStatement cstmt2 = null;
try {
// 注册MySQL的JDBC驱动程序
Class.forName(JDBC_DRIVER);
// 打开两个数据库连接
conn1 = DriverManager.getConnection(URL + “db1”, USER, PASS);
conn2 = DriverManager.getConnection(URL + “db2”, USER, PASS);
// 将两个连接加入分布式事务中
conn1.setAutoCommit(false);
conn2.setAutoCommit(false);
// 定义XA事务协调器
XADataSource xaDataSource1 = getDataSourceForDB1();
XADataSource xaDataSource2 = getDataSourceForDB2();
// 开始XA事务
XAConnection xaConnection1 = xaDataSource1.getXAConnection();
XAConnection xaConnection2 = xaDataSource2.getXAConnection();
XAResource xaResource1 = xaConnection1.getXAResource();
XAResource xaResource2 = xaConnection2.getXAResource();
Xid xid1 = new MyXid(, new byte[]{ 0x}, new byte[]{ 0x});
Xid xid2 = new MyXid(, new byte[]{ 0x}, new byte[]{ 0x});
xaResource1.start(xid1, XAResource.TMNOFLAGS);
xaResource2.start(xid2, XAResource.TMNOFLAGS);
// 在两个数据库中都执行一些操作,以确保事务涉及多个数据库
cstmt1 = conn1.prepareCall(“{ call add_new_user(?,?,?)}”);
cstmt1.setString(1, “张三”);
cstmt1.setInt(2, );
cstmt1.setString(3, “男”);
cstmt1.executeUpdate();
cstmt2 = conn2.prepareCall(“{ call add_new_user(?,?,?)}”);
cstmt2.setString(1, “李四”);
cstmt2.setInt(2, );
cstmt2.setString(3, “女”);
cstmt2.executeUpdate();
// 停止XA事务
xaResource1.end(xid1, XAResource.TMSUCCESS);
xaResource2.end(xid2, XAResource.TMSUCCESS);
// 准备XA事务
int rc1 = xaResource1.prepare(xid1);
int rc2 = xaResource2.prepare(xid2);
// 提交XA事务
if (rc1 == XAResource.XA_OK && rc2 == XAResource.XA_OK) {
xaResource1.commit(xid1, false);
xaResource2.commit(xid2, false);
} else {
xaResource1.rollback(xid1);
xaResource2.rollback(xid2);
}
// 关闭数据库连接
conn1.close();
conn2.close();
} catch (Exception e) {
System.out.println(“Exception: ” + e.getMessage());
try {
if (xaConnection1 != null) xaConnection1.close();
if (xaConnection2 != null) xaConnection2.close();
} catch (SQLException se) {
System.out.println(“SQL Exception: ” + se.getMessage());
}
} finally {
try {
if (cstmt1 != null) cstmt1.close();
if (cstmt2 != null) cstmt2.close();
} catch (SQLException se2) {
System.out.println(“SQL Exception: ” + se2.getMessage());
}
}
}
// 用于获取db1数据源的方法
private static XADataSource getDataSourceForDB1() throws SQLException {
String jdbcUrl = URL + “db1”;
MysqlDataSource mysqlDataSource = new MysqlDataSource();
mysqlDataSource.setURL(jdbcUrl);
mysqlDataSource.setUser(USER);
mysqlDataSource.setPassword(PASS);
return mysqlDataSource;
}
// 用于获取db2数据源的方法
private static XADataSource getDataSourceForDB2() throws SQLException {
String jdbcUrl = URL + “db2”;
MysqlDataSource mysqlDataSource = new MysqlDataSource();
mysqlDataSource.setURL(jdbcUrl);
mysqlDataSource.setUser(USER);
mysqlDataSource.setPassword(PASS);
return mysqlDataSource;
}
}
以上代码就是一个基本的使用MySQL XA事务实现分布式事务的例子。通过使用XA协议和协调器,我们可以确保事务的ACID性和数据的完整性。
MySQL InnoDB 秒级快照原理与当前读
MySQL中事务的启动有开始事务的两种方式。begin/start transaction 命令并不是事务的起点,只有在执行第一个操作InnoDB 表的语句时,事务才真正启动。若需立即启动事务,可使用transaction with consistent snapshot命令。
第一种启动方式创建一致性视图是在执行第一个快照读语句时;第二种方式则是执行start transaction with consistent snapshot时。
若事务C没有使用begin/commit命令,意味着其更新语句本身即为一个事务,语句执行完毕自动提交。事务B更新行后查询,事务A在只读事务中查询,时间顺序上晚于B。然而查询结果却出人意料:B查询到的k值是3,而A查询到的是1。
按照常规推理,B查询到的应该是2,A查询到的应该是1。为何现实情况与预期不符?关键在于MySQL中的两个视图概念:view和InnoDB在MVCC(多版本并发控制)下的一致性读视图。
在可重复读隔离级别下,事务启动时会“拍”一个快照。这个快照基于整个数据库,但如果库有G,复制出G数据创建快照会非常耗时,实际情况并非如此。快照的实现原理在于InnoDB中的事务ID和数据版本的管理。
每个事务拥有唯一事务ID,每次事务更新数据,都会生成新版本,并赋予当前事务ID。数据表中的每行记录可能有多个版本,每个版本有自己的事务ID。通过undo log计算版本,实现事务间的隔离。
可重复读要求事务能看到启动前提交的所有事务结果,但不认启动后生成的数据版本。InnoDB通过数组和高水位点构造一致性视图,数据版本可见性基于事务ID与视图的比较。
事务启动时,将当前已启动未提交事务的事务ID存储至视图数组,高水位点代表数组最大值加一。**部分数据版本由未提交事务生成,事务会根据ID判断数据可见性。
InnoDB实现秒级快照的关键在于事务ID和数据版本的关联与比较,基于此,事务A、B、C的查询结果得到合理解释。当前读机制导致B看到C的修改结果,且事务B的更新基于当前值进行,最终查询结果为3。
当前读机制引起的问题可通过使用临时表或避免在同一表内查询更新数据来解决,以避免读取错误的版本。可重复读隔离级别下的查询只承认事务开始前已提交的数据,而读提交则只承认语句启动前已提交的数据。
在可重复读中,查询根据一致性视图确定数据版本可见性;读提交中,每个语句前都重新计算视图;而当前读总是读取已提交的最新版本。
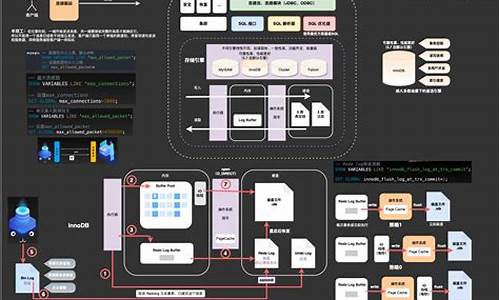
MySQL XA事务源码分析
事务类型外部 XA PREPARE 流程
省流版:
详细版:
外部 XA COMMIT 过程
省流版:
详细版:
外部 XA 2PC 阶段 Log 落盘顺序
------------------- XA PREPARE START -------------------------
------------------- XA PREPARE END -------------------------
.
.
.
.
.
.
------------------- XA COMMIT START -------------------------
------------------- XA COMMIT END -------------------------
本地事务 commit 流程
省流版
与外部 XA PREPARE 2PC 的不同
与外部 XA COMMIT 的不同
详细版:
------------------- PREPARE START -------------------------
------------------- PREPARE END -------------------------
------------------- COMMIT START -------------------------
------------------- COMMIT END -------------------------
外部 XA ROLLBACK 流程
省流版(Not Prepared Rollback 和 Prepared Rollback 的不同之处)
详细版
Not Prepared Rollback(在 end - prepare 之间 rollback)
Prepared Rollback(在 prepare 之后 rollback)
外部 XA RECOVERY 流程
省流版
详细版
本地事务 RECOVERY 流程
省流版
详细版
为什么只遍历最后一个binlog文件:
rotate 到新的 binlog 文件前,redo log 强制落盘,因此redo commit记录会落盘,保证老的binlog文件没有正在提交的事务
MySQL事务特性与原理详解
MySQL事务特性和原理详解
事务基础涵盖了事务的概念、ACID特性及MySQL事务状态流转。事务的四大特性——原子性、一致性、隔离性、持久性,构成了事务的基本框架。其中,原子性确保了事务的完整性,一致性保证了操作前后数据的一致状态,隔离性则保障了并发操作下的数据安全性,持久性确保了事务执行后的数据变化持久存储。
MySQL事务隔离级别是针对并发问题的解决方案,引入了不同级别的隔离性策略,如读未提交、读已提交、可重复读和串行化级别。隔离级别的选择需要在性能和数据一致性的权衡中做出决策,例如,低隔离级别可能提高性能,但增加了并发问题的风险。
MySQL中事务的使用包括存储引擎对事务的支持、事务的分类(显式和隐式)以及系统事务。存储引擎如InnoDB支持事务,而事务的使用则涵盖了从开始、结束到隔离级别的设置。代码示例展示了事务的实践应用。
事务日志在MySQL中扮演着关键角色,包括redo日志和undo日志。redo日志通过顺序记录页修改操作,确保数据可靠性,而undo日志则用于事务回滚,实现数据的原子性和一致性。redo日志的写入策略和刷盘策略对性能和数据持久性有着直接影响,undo日志的存储结构和分类则体现了MVCC(多版本并发控制)的实现方式。
redo日志和undo日志之间存在明显的区别,redo日志是存储引擎层产生的,用于事务恢复和数据一致性,而undo日志是事务处理时为实现回滚而产生的日志。undo日志的生命周期涉及其产生、回滚以及删除过程,与redo日志紧密配合,确保了数据操作的完整性和一致性。
综上所述,MySQL事务特性与原理是确保数据库操作一致性和高效性的关键。通过理解事务的ACID特性、隔离级别、日志机制以及它们之间的相互作用,开发者能够更好地管理并发事务,避免数据冲突,确保数据的完整性和一致性。
2025-01-19 10:25
2025-01-19 10:02
2025-01-19 09:29
2025-01-19 09:13
2025-01-19 08:44
2025-01-19 08:28
