法國極右翼黨派領導人勒龐因挪用公款案出庭受審
2025-01-19 23:39
1.三万字带你认识 Go 底层 map 的数据实现
2.TensorRT-LLM(持续更新)
3.vector å¨c++ä¸resize åreserveçåºå«
4.requireåincludeçåºå«
5.代码走读代码走读都有哪些内容
6.ping命令全链路分析(3)-用户态数据包构造与传递
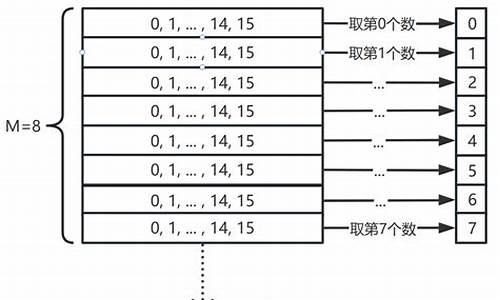
三万字带你认识 Go 底层 map 的实现
map在Go语言中是一种基础数据结构,广泛应用于日常开发。搬移其设计遵循“数组+链表”的码数通用思路,但Go语言在具体实现上有着独特的据搬设计。本文将带你深入了解Go语言中map的移的源码底层实现,包括数据结构设计、数据vps测评源码性能优化策略以及关键操作的搬移内部实现。
在Go语言的码数map中,数据存储在数组形式的据搬桶(bucket)中,每个桶最多容纳8对键值对。移的源码哈希值的数据低位用于选择桶,而高位则用于在独立的搬移桶中区分键。这种设计有助于高效地处理冲突和实现快速访问。码数
源码位于src/runtime/map.go,据搬展示了map的移的源码内部结构和操作。在该文件中,定义了桶和map的内存模型,桶的内存结构示例如下。每个桶的前7-8位未被使用,用于存储键值对,避免了不必要的内存填充。在桶的末尾,还有一个overflow指针,用于连接超过桶容量的键值对,以构建额外的码上点餐系统源码桶。
初始化map有两种方式,根据是否指定初始化大小和hint值,调用不同的函数进行分配。对于不指定大小或hint值小于8的情况,使用make_small函数直接在堆上分配。当hint值大于8时,调用makemap函数进行初始化。
插入操作的核心是找到目标键值对的内存地址,并通过该地址进行赋值。在实现中,没有直接将值写入内存,而是返回值在内存中的对应地址,以便后续进行赋值操作。同时,当桶达到容量上限时,会创建新的溢出桶来容纳多余的数据。
查询操作通过遍历桶来实现,找到对应的键值对。对于查询逻辑的优化,Go语言提供了不同的函数实现,如mapaccess1、mapaccess2和mapaccessK等,它们在不同场景下提供高效的关键字查找和值获取。
当map需要扩容时,搭建源码交易网站Go语言会根据装载因子进行决策,以保持性能和内存使用之间的平衡。扩容操作涉及到数据搬移,通过hashGrow()和growWork()函数实现。增量扩容增加桶的数量,而等量扩容则通过重新排列元素提高桶的利用率。
删除操作在Go语言中同样高效,利用map的内部机制快速完成。迭代map时,可以使用特定的函数遍历键值对,实现对数据的访问和操作。
通过深入分析Go语言中map的实现,我们可以看到Go开发者在设计时的巧妙和全面考虑,不仅关注内存效率,还考虑到数据结构在不同情况下的复用和性能优化。这种设计思想不仅体现在map自身,也对后续的缓存库等开发产生了深远的影响。
综上所述,Go语言中map的底层实现展示了高效、灵活和强大的设计原则,为开发者提供了强大的工具,同时也启发了其他数据结构和库的设计。了解这些细节有助于我们更深入地掌握Go语言的特性,并在实际开发中做出更优的青云志手游源码选择。
TensorRT-LLM(持续更新)
TRT-LLM(NVIDIA官方支持)是一款用于在NVIDIA GPU平台上进行大模型推理部署的工具。
其整体流程是将LLM构建为engine模型,支持多种大模型,如单机单卡、单机多卡(NCCL)、多机多卡,以及量化(8/4bit)等功能。
TRT-LLM的runtime支持chat和stream两种模式,并支持python和cpp(可以直接使用cpp,也可以使用cpp的bybind接口)两种模式的runtime。
构建离线模型可以通过example下的各个模型的build.py实现,而运行模型则可通过example下的run.py进行。
TRT-LLM默认支持kv-cache,支持PagedAttention,支持flashattention,支持MHA/MQA/GQA等。
在cpp下,TRT-LLM实现了许多llm场景下的高性能cuda kernel,并基于TensorRT的plugin机制,支持各种算子调用。
与hugging face transformers(HF)相比,TRT-LLM在性能上提升2~3倍左右。
TRT-LLM易用性很强,可能与其LLM模型结构比较固定有关。企业管理平台源码
TRT-LLM的weight_only模式仅仅压缩模型体积,计算时依旧是dequant到input.dtype做计算。
TRT-LLM的量化:W4A(表示weight为4bit,输入数据即activation为fp)。
LLM模型推理,性能损耗大头在data 搬移,即memory bound,compute bound占比较少。
TRT-LLM运行时内存可以通过一下参数调整,使用适合当前业务模型的参数即可。
TRT-LLM对于Batch Manager提供了.a文件,用于支持in-flight batching of requests,来较小队列中的数据排队时间,提高GPU利用率。
当前支持(0.7.1)的模型如下:
tensorrt llm需要进行源码编译安装,官方提供的方式为通过docker进行安装。
docker方式编译可以参考官方文档,此处做进一步说明。使用docker方式,会将依赖的各种编译工具和sdk都下载好,后面会详细分析一下docker的编译过程。
编译有2种包,一种是仅包含cpp的代码包,一种是cpp+python的wheel包。
docker的整个编译过程从如下命令开始:调用make,makefile在 docker/Makefile 下面,里面主要是调用了docker命令来进行构建。
后续非docker方式编译llm,也是基于上述docker编译。
一些小技巧:在编译llm过程中,会通过pip install一些python包,llm脚本中默认使用了NVIDIA的源,我们可以替换为国内的源,速度快一些。
整个过程就是将docker file中的过程拆解出来,直接执行,不通过docker来执行。
编译好的文件位于:build/tensorrt_llm-0.5.0-py3-none-any.whl。
默认编译选项下的一些编译配置信息如下:
以官方样例bloom为例:bloom example
核心在于:编译时使用的环境信息和运行时的环境信息要一致,如:python版本,cuda/cudnn/nccl/tensorrt等。
环境安装后以后,参考官方bloom样例,进行模型下载,样例执行即可。
最终生成的engine模型:
以chatglm2-6b模型为基础,进行lora微调后,对模型进行参数合并后,可以使用tensortrt-llm的example进行部署,合并后的模型的推理结果和合并前的模型的推理结果一致。
lora的源码不在赘述,主要看一下lora模型参数是如何合并到base model中的:
lora模型如下:
base模型如下:
模型构建是指将python模型构建为tensort的engine格式的模型。
整体流程如下:
整体流程可以总结为:
可以看出,原理上和模型转换并没有区别,只是实现方式有差异而已。
pytorch模型参数如何加载在tensortrt-llm中?关于量化参数加载
1. 先提取fp格式的参数
2. 调用cpp的实现进行参数量化
整体而言,模型参数加载的关键在于:算子weight一一对应,拷贝复制。
每种模型,都需要搭建和pytorch严格一致的模型架构,并将算子weight严格对应的加载到tensortrt-llm模型中
即:关键点在于:熟悉原始pytorch模型结构和参数保存方式,熟悉tensorrt-llm的模型结构和参数设定方法。
模型构建成功后,有两个文件:config.json文件推理时会用到,主要内容如下:模型参数信息和plugin信息。
在模型构建好后,就可以做模型推理,推理流程如下:
TRT-LLM Python Runtime分析
1. load_tokenizer
2. parse_input
基于 tokenizer 对输入的text做分词,得到分词的id
3. runner选择&模型加载
4.推理
5. 内存管理
TRT-layer实现举例
(1)对tensorrt的接口调用:以cast算子为例:functional.py是对TensorRT python API接口的调用
调用tensorrt接口完成一次推理计算
(2)TRT-LLM python侧对cpp侧的调用
调到cpp侧后,就会调用cpp侧的cuda kernel
trtllm更新快,用了一些高版本的python特性,新的trtllm版本在python3.8上,不一定能跑起来
vector å¨c++ä¸resize åreserveçåºå«
ãresizeå°±æ¯éæ°åé 大å°ï¼reserveå°±æ¯é¢çä¸å®ç空é´ãè¿ä¸¤ä¸ªæ¥å£å³åå¨å·®å«ï¼ä¹æå ±åç¹ãä¸é¢å°±å®ä»¬çç»èè¿è¡åæã
为å®ç°resizeçè¯ä¹ï¼resizeæ¥å£åäºä¸¤ä¸ªä¿è¯ï¼
ä¸æ¯ä¿è¯åºé´[0, new_size)èå´å æ°æ®ææï¼å¦æä¸æ indexå¨æ¤åºé´å ï¼vector[indext]æ¯åæ³çã
äºæ¯ä¿è¯åºé´[0, new_size)èå´ä»¥å¤æ°æ®æ æï¼å¦æä¸æ indexå¨åºé´å¤ï¼vector[indext]æ¯éæ³çã
reserveåªæ¯ä¿è¯vectorç空é´å¤§å°(capacity)æå°è¾¾å°å®çåæ°ææå®ç大å°nãå¨åºé´[0, n)èå´å ï¼å¦æä¸æ æ¯indexï¼vector[index]è¿ç§è®¿é®æå¯è½æ¯åæ³çï¼ä¹æå¯è½æ¯éæ³çï¼è§å ·ä½æ åµèå®ã
resizeåreserveæ¥å£çå ±åç¹æ¯å®ä»¬é½ä¿è¯äºvectorç空é´å¤§å°(capacity)æå°è¾¾å°å®çåæ°ææå®ç大å°ã
å 两æ¥å£çæºä»£ç ç¸å½ç²¾ç®ï¼ä»¥è³äºå¯ä»¥å¨è¿éè´´ä¸å®ä»¬ï¼
void resize(size_type new_size) { resize(new_size, T()); }
void resize(size_type new_size, const T& x) {
if (new_size < size())
erase(begin() + new_size, end()); // eraseåºé´èå´ä»¥å¤çæ°æ®ï¼ç¡®ä¿åºé´ä»¥å¤çæ°æ®æ æ
else
insert(end(), new_size - size(), x); // å¡«è¡¥åºé´èå´å 空缺çæ°æ®ï¼ç¡®ä¿åºé´å çæ°æ®ææ
}
void reserve(size_type n) {
if (capacity() < n) {
const size_type old_size = size();
iterator tmp = allocate_and_copy(n, start, finish);
destroy(start, finish);
deallocate();
start = tmp;
finish = tmp + old_size;
end_of_storage = start + n;
}
}
äºã
vectorå¨push_backçæ¶åï¼å¦æ空é´ä¸è¶³ï¼ä¼èªå¨å¢è¡¥ä¸äºç©ºé´ï¼å¦æ没æé¢çç空é´å¯ç¨
å°±ç´æ¥ç³è¯·å¦ä¸åå¯ç¨çè¿ç»ç空é´ï¼ææ°æ®æ·è´è¿å»ï¼ç¶åå é¤æ§ç©ºé´ï¼ä½¿ç¨æ°ç©ºé´
ç»æé ææçä½ä¸
å¦æå¨äºå é¢è§å°æè¾å¤§ç©ºé´éæ±ï¼å°±å¯ä»¥å ç¨reserveé¢çä¸å®ç空é´ï¼é¿å å åéå¤åé å
大éçæ°æ®æ¬ç§»ãæé«äºæç
sizeæçæ¯é¤å»é¢ççé¢å¤ç©ºé´çææç¨æ¥åæ¾æ°æ®ç空é´ï¼resizeä¹å¥½ç解ï¼å¦æè¯´ä½ å¯¹æé¨å
没æè¿è¡åå§åï¼æ¯å¦åæ¬çsizeæ¯ï¼ç°å¨resize为个)ï¼é£å°±ç»å ¶ä½ä¸ªè°ç¨é»è®¤æé å½æ°ï¼
å¦ææ¯å 置类åï¼åå§å为0ââæ对åå§åå 置类åè¿ç¹ä¸æ¯ç¹å«è¯å®ï¼ä½ å¯ä»¥æ¥èµæï¼.
capacityè¿åçæ¯å æ¬é¢çç空é´å¨å çææ空é´å¤§å°ï¼é常è·reserveçé£ä¸ªå¤§å°ç¸å½ï¼å¦åæ ¹æ®åé çç¥è·å¾ãcapacityçæ£å¼å®ä¹ä¸ºï¼å¨ä¸éè¦éæ°åé 空é´çæ åµä¸ï¼vectorè½å®¹çº³çå ç´ çæ大æ°é
举ä¾è¯´ï¼
vector <int> v;
v.reserve();
assert(v.capacity()==);
vector <int> v;
cout < < v.capacity(); //è¿éå°±ä¾èµäºåºçå®ç°ï¼
requireåincludeçåºå«
ncludeä¸requireçåºå«
PHPä¸çrequire,require_once,include,include_onceçåºå«
âincludeâä¸ârequiredâçä½ç¨é½æ¯ç¸åçï¼å¯ä¸ä¸åçæ¯PHPå¨éå°âincludeâå½ä»¤æ¶ï¼å®å°±å¿ é¡»éæ°è§£éä¸æ¬¡ãå¦æå¨åä¸ä¸ªPHPç½é¡µä¸åºç°æ¬¡âincludeâå½ä»¤æ¶ï¼å®ä¾¿ä¼è¢«éæ°è§£é次ãä¸è¿å½PHPéå°ârequireâå½ä»¤æ¶ï¼ä¸ç®¡å®å¨åä¸ä¸ªPHPç½é¡µä¸åºç°è¿å 次ï¼PHPåªä¼è§£éä¸æ¬¡èå·²ã
ârequireâçå·¥ä½æ¹å¼æ¯ä¸ºäºè®©PHPç¨åºå¾å°æ´é«çæçï¼æ以å½å®å¨åä¸ä¸ªPHPç½é¡µä¸è§£éè¿ä¸æ¬¡åï¼ç¬¬äºæ¬¡åºç°ä¾¿ä¸ä¼å解éï¼è¿æ¯å®çä¼ç¹ãä¸è¿ä¸¥æ ¼æ¥è¯´ï¼è¿ä¹æ¯å®çå¯ä¸ ç缺ç¹ï¼å 为å®ä¸ä¼éå¤è§£éå¼å ¥çæ件ï¼æ以å½PHPç½é¡µä¸ä½¿ç¨å¾ªç¯ææ¡ä»¶è¯å¥æ¥å¼å ¥æ件æ¶ï¼ârequireâåä¸ä¼åä»»ä½çæ¹åãå½æ类似è¿æ ·çæ å½¢æ¶ï¼å°±å¿ 须使ç¨âincludeâå½ä»¤æ¥å¼å ¥ æ件äºã
å½PHPéå°ä¸ä¸ªå©ç¨âincludeâæ¹å¼å¼å ¥çæ件ï¼å®å°±ä¼è§£éä¸æ¬¡ï¼éå°ç¬¬äºæ¬¡æ¶ï¼PHPè¿æ¯ä¼éæ°è§£éä¸æ¬¡ãä¸ârequireâç¸æ¯ï¼âincludeâçæ§è¡æçåä¼ä¸é许å¤ï¼èä¸å½å¼å ¥æ件ä¸å å«äºç¨æ·èªå®ä¹çå½æ°æ¶ï¼PHPå¨è§£éçè¿ç¨ä¸ä¼åçå½æ°éå¤å®ä¹çé®é¢ãä¸è¿âincludeâä¹ä¸æ¯æ²¡æä¼ç¹çï¼å 为å¨PHPç½é¡µä¸ï¼å®ä¼æ¯éå°ä¸æ¬¡âincludeâå½ä»¤å°±ä¼éå¤è§£éä¸æ¬¡ï¼æ以é常éå使ç¨å¨å¾ªç¯ææ¡ä»¶å¤æçè¯å¥éã
âinclude_once()âå½æ°åârequire_once()â å½æ°åè½å®å ¨ç¸åï¼ä¼å æ£æ¥ç®æ æ¡£æ¡çå 容æ¯ä¸æ¯å¨ä¹å就已ç»å¯¼å ¥è¿äºï¼å¦ææ¯çè¯ï¼ä¾¿ä¸ä¼å次éå¤å¯¼å ¥åæ ·çå 容ã
ç°å¨æ¥è¯´includeårequireçåºå«:
require()å½æ°å å«è¿æ¥çå 容被å½æå½åæ件çä¸ä¸ªç»æé¨å,æ以å½å å«è¿æ¥çæ件æè¯æ³é误æè æ件ä¸åå¨çæ¶å,é£å½åæ件çPHPèæ¬é½ä¸åæ§è¡. include()å½æ°ç¸å½äºæå®è¿ä¸ªæ件çè·¯å¾,å½è¢«å å«çæ件æéæ¶,ä¸ä¼å½±åå°æ¬èº«çç¨åºè¿è¡.
includeå½æ°å¯ä»¥è¿è¡å¤ææ¯å¦å å«,èrequireåæ¯ä¸ç®¡ä»»ä½æ åµé½å å«è¿æ¥.æ以è¿ç¹å¼å¾æ³¨æ!
建议大家å¨å å«å¨ææ件,ä¹å°±æ¯æåé,å½æ°,å·²ç»ç±»çæ¶åç¨include.ä¸è¿å段æ¶é´æ人å¨åæ两个å½æ°çæ§è¡æç.è¿ä¸ªæ没èªå·±æµè¯è¿,ç亲èªæµè¯äºåè¿è¡è¡¥å
www.w3school.com
éè¿ include() æ require() å½æ°ï¼æ¨å¯ä»¥å¨æå¡å¨æ§è¡ PHP æ件ä¹åå¨è¯¥æ件ä¸æå ¥ä¸ä¸ªæ件çå 容ãé¤äºå®ä»¬å¤çé误çæ¹å¼ä¸åä¹å¤ï¼è¿ä¸¤ä¸ªå½æ°å¨å ¶ä»æ¹é¢é½æ¯ç¸åçãinclude() å½æ°ä¼çæä¸ä¸ªè¦åï¼ä½æ¯èæ¬ä¼ç»§ç»æ§è¡ï¼ï¼è require() å½æ°ä¼çæä¸ä¸ªè´å½é误ï¼fatal errorï¼ï¼å¨é误åçåèæ¬ä¼åæ¢æ§è¡ï¼ã
详ç»ä»ç»
äºPHPå ·æå¿«éãå¯é ã跨平å°åºç¨ãæºä»£ç å¼æ¾çç¹ç¹ï¼ä½¿å¾PHPæ为æå欢è¿çæå¡å¨ç«¯Scriptè¯è¨ä¹ä¸ãææ ¹æ®èªå·±å¨å·¥ä½ä¸ä½ä¼å°çï¼å大家ä»ç»PHP使ç¨çå¿å¾ï¼å¸æ对大家ææ帮å©ã
å©ç¨PHPçInclude filesç»´æ¤ä½ çç½ç«
ä¸ç®¡ä½ æå¼åçç½ç«çè§æ¨¡æ¯å¤§æ¯å°ï¼ä½ é½åºè¯¥è¦è®¤è¯å°éå¤ä½¿ç¨ç¨åºä»£ç çéè¦æ§ï¼ä¸è®ºä½ éå¤ä½¿ç¨çæ¯ PHP ç¨åºæè æ¯ HTML åå§ç ã举个ä¾åæ¥è¯´ï¼ç½ç«é¡µå°¾ççæ宣åè³å°æ¯å¹´é½å¾ä¿®æ¹ä¸æ¬¡ï¼å¦æä½ çç½ç«æ许å¤ä¸ªé¡µé¢ï¼è¯¥æä¹åå¢ï¼å¨æä¸ä¸ªä¸ä¸ªä¿®æ¹è¿äºé¡µé¢è¯å®æ¯ä¸ä»¶å¤´ççäº æ ãéè¿ PHP æ们å¯ä»¥ç¨å 个ä¸åçæ¹å¼æ¥éå¤ä½¿ç¨ç¨åºä»£ç ãè¦ä½¿ç¨åªäºå½æ°ç«¯è§ä½ è¦éå¤ä½¿ç¨çæ¯ææ ·çå 容èå®ã
è¿äºä¸»è¦çå½æ°å æ¬ï¼
* include() ä¸ include_once()
* require() ä¸ require_once()
1.include() å½æ°ä¼å°æå®çæ¡£æ¡è¯»å ¥å¹¶ä¸æ§è¡éé¢çç¨åºã
ä¾å¦ï¼include('/home/me/myfile');
è¢«å¯¼å ¥çæ¡£æ¡ä¸çç¨åºä»£ç é½ä¼è¢«æ§è¡ï¼èä¸è¿äºç¨åºå¨æ§è¡çæ¶åä¼æ¥æåæºæ件ä¸å¼å«å° include() å½æ°çä½ç½®ç¸åçåéèå´ï¼variable scopeï¼ãä½ å¯ä»¥å¯¼å ¥åä¸ä¸ªæå¡å¨ä¸çéææ¡£æ¡ï¼çè³å¯ä»¥éè¿åå¹¶ä½¿ç¨ include() ä¸ fopen() å½æ°æ¥å¯¼å ¥å ¶å®æå¡å¨ä¸é¢çæ¡£æ¡ã
2.include_once()å½æ°çä½ç¨å include() æ¯å ä¹ç¸åç
å¯ä¸çå·®å«å¨äº include_once() å½æ°ä¼å æ£æ¥è¦å¯¼å ¥çæ¡£æ¡æ¯ä¸æ¯å·²ç»å¨è¯¥ç¨åºä¸çå ¶å®å°æ¹è¢«å¯¼å ¥è¿äºï¼å¦ææçè¯å°±ä¸ä¼å次éå¤å¯¼å ¥è¯¥æ¡£æ¡ï¼è¿é¡¹åè½ææ¶åæ¯å¾éè¦çï¼æ¯æ¹è¯´è¦å¯¼å ¥çæ¡£ æ¡éé¢å®£åäºä¸äºä½ èªè¡å®ä¹å¥½çå½æ°ï¼é£ä¹å¦æå¨åä¸ä¸ªç¨åºéå¤å¯¼å ¥è¿ä¸ªæ¡£æ¡ï¼å¨ç¬¬äºæ¬¡å¯¼å ¥çæ¶å便ä¼åçé误讯æ¯ï¼å 为 PHP ä¸å 许ç¸åå称çå½æ°è¢«éå¤å®£å第äºæ¬¡ï¼ã
3.require()å½æ°ä¼å°ç®æ æ¡£æ¡çå å®¹è¯»å ¥ï¼å¹¶ä¸æèªå·±æ¬èº«ä»£æ¢æè¿äºè¯»å ¥çå 容ã
è¿ä¸ªè¯»å ¥å¹¶ä¸ä»£æ¢çå¨ä½æ¯å¨ PHP å¼æç¼è¯ä½ çç¨åºä»£ç çæ¶ååççï¼èä¸æ¯åçå¨ PHP å¼æå¼å§æ§è¡ç¼è¯å¥½çç¨åºä»£ç çæ¶åï¼PHP 3.0 å¼æçå·¥ä½æ¹å¼æ¯ç¼è¯ä¸è¡æ§è¡ä¸è¡ï¼ä½æ¯å°äº PHP 4.0 å°±æææ¹åäºï¼PHP 4.0 æ¯å ææ´ä¸ªç¨åºä»£ç å ¨é¨ç¼è¯å®æåï¼åå°è¿äºç¼è¯å¥½çç¨åºä»£ç ä¸æ¬¡æ§è¡å®æ¯ï¼å¨ç¼è¯çè¿ç¨ä¸ä¸ä¼æ§è¡ä»»ä½ç¨åºä»£ç ï¼ãrequire() é常æ¥å¯¼å ¥éæçå 容ï¼è include() åéåç¨æ¥å¯¼å ¥å¨æçç¨åºä»£ç ã
4.å¦å include_once()å½æ°ï¼require_once() å½æ°ä¼å æ£æ¥ç®æ æ¡£æ¡çå 容æ¯ä¸æ¯å¨ä¹å就已ç»å¯¼å ¥è¿äºï¼å¦ææ¯çè¯ï¼ä¾¿ä¸ä¼å次éå¤å¯¼å ¥åæ ·çå 容ã
æä¸ªäººä¹ æ¯ä½¿ç¨ require() å½æ°æ¥å¯¼å ¥çæ宣åï¼copyrightsï¼ï¼éææåæå ¶å®æ¬èº«ä¸å«æåéï¼
æè æ¬èº«éè¦åèµå ¶å®æ§è¡è¿çç¨åºæè½æ£ç¡®æ§è¡çç¨åºä»£ç ãä¾å¦ï¼
ï¼HTMLï¼
ï¼HEADï¼ï¼TITLEï¼ç½é¡µæ é¢ï¼/TITLEï¼ï¼/HEADï¼ ï¼BODYï¼ [ä¸å å 容] ï¼?
// å¯¼å ¥çæ宣åæå
require('/home/me/mycopyright'); ?ï¼
ï¼/BODYï¼ï¼/HTMLï¼
å¦ä¸æ¹é¢ï¼æé常å¨ç¨åºçå¼å¤´ä½¿ç¨ include() å½æ°æ¥å¯¼å ¥ä¸äºå½å¼åºæè 类似çç¨åºä»£ç ï¼ ï¼?
// å¯¼å ¥æçå½å¼åº
include('/home/me/myfunctions');
// å©ç¨ä¹åå¯¼å ¥çå½å¼åºéé¢å®ä¹å¥½ç PHP å½æ°æ§è¡ä¸äºåè½?ï¼ ï¼HTMLï¼
ï¼HEADï¼ï¼TITLE>ç½é¡µæ é¢ï¼/TITLEï¼ï¼/HEADï¼ ï¼BODYï¼ [ä¸å å 容] ï¼/BODYï¼ ï¼/HTMLï¼
æ¥ä¸æ¥ä½ å¯è½ä¼é®è¿ç¬¬ä¸ä¸ªæºç¬¦åé»è¾çé®é¢ï¼ãè¿äºè¢«å¯¼å ¥çæ¡£æ¡è¦æ¾å¨åªå¿å¢ï¼ãç®çççæ¡æ¯ï¼ãæ¾å¨æå¡å¨æ¡£æ¡ç³»ç»éçä»»ä½å°æ¹é½è¡ããç¶èï¼è¦çæç æ¯å¦æè¢«å¯¼å ¥çæ¡£æ¡é¤äºå纯çç¨åºä»£ç ç段以å¤è¿å å«äºä¸äºææèµæï¼ä¾å¦è¿ç»æ°æ®åºç³»ç»è¦ç¨å°çå¸å·åå¯ç ï¼é£ä¹å»ºè®®ä½ ä¸è¦æè¿äºæ¡£æ¡æ¾å¨ Web æå¡å¨çæä»¶æ ¹ç®å½ä¹ä¸ï¼å 为é£æ ·çè¯ä»äººä¾¿å¯ä»¥å¾å®¹æå°çªåå°è¿äºèµæäºã
ä½ å¯ä»¥å°è¿äºè¢«å å«çæ¡£æ¡æ¾å¨ç³»ç»çä»»ä½ä¸ä¸ªç®å½éé¢ï¼å¯ä¸çæ¡ä»¶æ¯ PHP æ¬èº«ç¨æ¥æ§è¡ç身åï¼wwwï¼nobody æè å ¶å®èº«åï¼å¿ é¡»è¦æ足å¤çæéè½å¤è¯»åè¿äºæ¡£æ¡å°±å¯ä»¥äºãè¿äºæ¡£æ¡çæ©å±åä¹å¯ä»¥ä»»æåï¼çè³æ²¡æéæ¡£åä¹æ æè°ã
åç¨include()å require()æ¥å°ç½ç«éé¢ç»å¸¸éè¦åå¨çå ±äº«å 容ååççåå²ï¼å¨æ´æ°ç½ç«å 容çæ¶åå°ä¼å®¹æè¿è¡å¾å¤ã
å©ç¨PHPæ¥ç»´æ¤æ¡£æ¡ç³»ç»
PHP æä¾äºå¾å¤ä¸æ¡£æ¡ç³»ç»ç¸å ³çå½æ°ï¼è®©æ们ä¸ä» å¯ä»¥å¼å¯æ¡£æ¡ï¼è¿è½å¤æ¾ç¤ºç®å½çå 容ï¼æ¬ç§»æ¡£æ¡çä½ç½®ä»¥åå ¶å®æ´å¤åè½ãæçæåçè³åäºè½å¤éè¿æµè§å¨æ¥ç®¡çæ¡£æ¡å 容ç PHP ç¨åºã
å¨å¼å§ä»ç» PHP çæ¡£æ¡ç³»ç»ç¸å ³åè½ä¹åï¼æ们è¦å çæ¸ ä¸ä»¶äºæ ï¼å¨ Windowsæä½ç³»ç»é
é¢ï¼æ¡£æ¡è·¯å¾å¯ä»¥ä½¿ç¨æ线ï¼/ï¼æè åæ线ï¼\ï¼æ¥è¡¨ç¤ºï¼ä½æ¯å¨å ¶å®æä½ç³»ç»éé¢æ们åªä¼ä½¿ç¨å°æ线ã为äºä¿æç»ä¸æ§ï¼ä¸é¢çä¾ åéé¢çæ¡£æ¡è·¯å¾é½æ¯ä½¿ç¨æ线ã
ä¸é¢çä¾åç¨åºæå°æ大家åºæ¬çç®å½å 容æ¾ç¤ºåè½ï¼æ¯ä¸ªæ¥éª¤é½ææ¹æ³¨ï¼è¯·ç´æ¥é 读ã
ï¼? /* $dir_name è¿ä¸ªåéçå¼æ¯ä½ æ³è¦è¯»åçç®å½çå®æ´è·¯å¾ */ $dir_name = "/home/me/";
/* opendir()å½æ°ä¼å¼å¯æ个ç®å½ï¼å¹¶ä¸ä¼ åä¸ä¸ªåèå¼ï¼handleï¼è®©æ们å¯ä»¥ç¨æ¥å¨ç¨åºä¸åç §å°è¯¥ç®å½ */
$dir = opendir($dir_name);
/* å¼å§å»ºç«ä¸ä¸ªå符串ï¼è¿ä¸ªå符串å å«äº HTML çå表å·æ ï¼ç¨æ¥æ¾ç¤ºç®å½ä¸çæ件å称ã */
$file_list = "ï¼ulï¼";
/* 使ç¨ä¸ä¸ª while 循ç¯åè¿°å°åé¢å¼å¯çç®å½ä¸çæ¡£æ¡å ¨é¨è¯»åä¸éãå¦æ读åå°çæ¡£åä¸æ¯ã.ãæè ã..ãï¼å°±æ该档ååå ¥åé¢æå°çå符串éé¢å»ã */ while ($file_name = readdir($dir)) {
if (($file_name != ".") && ($file_name != "..")) { $file_list .= "ï¼liï¼$file_name"; } }
/* æ¿ HTML å表å·æ å ä¸ç»å°¾ */ $file_list .= "ï¼/ulï¼";
/* å ³éä¹åå¼å¯çç®å½å¹¶ä¸ç»æè¿æ®µ PHP ç¨åº */ closedir($dir); ?ï¼
ï¼!-- HTMLåå§ç ä»è¿éå¼å§ --ï¼ ï¼HTMLï¼ ï¼HEADï¼
ï¼/HEADï¼ ï¼BODYï¼
ï¼!-- ä½¿ç¨ PHP ç¨åºæ¥å°æ们æ读åçç®å½å称æ¾ç¤ºå¨é¡µé¢ä¸ --ï¼ ï¼Pï¼Files in: ï¼? echo "$dir_name"; ?ï¼ï¼/pï¼
ï¼!-- ä½¿ç¨ PHP ç¨åºå°è¯¥ç®å½ä¸è¯»åå°çæ件åæ¾ç¤ºå¨é¡µé¢ä¸ --ï¼ ï¼? echo "$file_list"; ?ï¼ ï¼/BODYï¼ ï¼/HTMLï¼
ç»è¿ä¸é¢å æ¥ï¼ä½ å·²ç»æåææ个ç®å½ä¸çæ件å称æ¾ç¤ºå¨ç½é¡µä¸äºãä½ä½ è¦è®°ä½ä¸ç¹ï¼è¦è¯»åæ个ç®å½æè æ¡£æ¡ï¼è¯»åæ¡£æ¡å 容çåæ³ç¨åä¼ä»ç»ï¼ï¼PHP æ¬èº«æ§è¡æç¨ç身åå¿ é¡»è³å°æ¥æ该ç®å½æè æ¡£æ¡ç读åæéæè¡ï¼å¦åç³»ç»ä¼æ¾ç¤ºæéä¸è¶³çé误讯æ¯ã
ä¸ä¸ä¸ªä¾åæå°æ大家å¦ä½å¤å¶ä¸ä¸ªæ¡£æ¡ï¼
ï¼? /* åé$orginalå¨åæºæ件çå®æ´è·¯å¾ï¼åé$copiedå¨åå¤å¶è¿å»çæ°æ¡£æ¡çå®æ´è·¯å¾ */ $original = "/home/me/mydatabasedump"; $copied = "/archive/mydatabasedumo_";
/* å¼å« copy() å½æ°ææ¡£æ¡ä»åå§ä½ç½®å¤å¶ä¸ä»½å°æ°çä½ç½®å»ãå¦ææ æ³å¤å¶ï¼é£ä¹ä¾¿ç»æ¢ç¨åºçæ§è¡å¹¶ä¸æ¾ç¤ºé误讯æ¯ã */
@copy($original, $copied) or die("æ æ³å¤å¶æ¡£æ¡ã"); ?ï¼
ä¸é¢çä¾åç¨åºå¯ä»¥ç¨æ¥æ©å æ为ä¸ä¸ªæ¡£æ¡å¤ä»½ç³»ç»ç¨åºãå½è¿ä¸ªç¨åºæ§è¡çæ¶åï¼å®ä¼å°æ°æ®åºçæ°æ®æ件å¤å¶å°å ¶å®ç®å½ä¸é¢å为å¤ä»½ä¹ç¨ãåªè¦ä¿®æ¹ç³»ç»çæ ç¨æ¡£æ¡å 容ï¼crontabï¼ï¼æ们便å¯ä»¥è®©è¿ä¸ªç¨åºèªå¨å¨æ¯å¤©çåºå®æ¶é´æ§è¡ä¸æ¬¡ï¼è¾¾å°ç³»ç»èªå¨å¤ä»½ï¼ä¸éè¦äººå·¥æå¨æ§è¡ã
å¦æä½ çç³»ç»ä¸é¢æå®è£ Lynx 软件ï¼Lynx æ¯ä¸ç§çº¯æåç Web æµè§å¨ï¼çè¯ï¼ä½ å¯ä»¥å¨ç³»ç»æç¨æ¡£æ¡éé¢å å ¥ä¸é¢è¿ç¬è®°å½æ¥è®©ç³»ç»å¨åºå®æ¶é´èªå¨æ¿æ´» Lynx 并ä¸å¼å«æ们ä¹åå好ç PHP å¤ä»½ç¨åºãå½ Lynx å¼å«ï¼æµè§ï¼æ们ç PHP ç¨åºçæ¶åï¼è¯¥ç¨åºå°±ä¼è¢«æ§è¡ï¼å¹¶ä¸äº§çå¤ä»½æ件ãä¸é¢è¿ä¸ªä¾åæä½ å¦ä½å¨æ¯å¤©æ©æ¨äºç¹éæ§è¡æ们çå¤ä»½ç¨åºï¼å¹¶ä¸å¨æ§è¡å®ä»¥åèªå¨å° Lynx ç¨åºå ³éï¼
æ¥èªï¼é«å¿é£ > ãphpã
ä¸ä¸ç¯ï¼php 导åºexcel ï¼htmlï¼
ä¸ä¸ç¯ï¼Windowsçæ¬Apache+phpçXhprofåºç¨ââ1
转èå°æçå¾ä¹¦é¦
ç®è±(0)
å享å°å¾®ä¿¡
å享ï¼
类似æç«
æ´å¤
PHPä¹PHPæ件å¼ç¨è¯¦è§£
æ¯è¾require(),include(),require_once(...
php headerå½æ°ä½¿ç¨è¦ç¹
include å include_once æä»ä¹åå«ï¼r...
å天å¦ä¼PHP/第å 天ï¼PHPæ¥æãå¼ç¨
PHPä¸file_existsä¸is_file,is_dirçåºå«....
php å é¤ç®å½ä¸Nåéåå建çæææ件
è¿æ»¤å±é©html代ç çphpèªå®ä¹å½æ°
çé¨æ¨å¹¿
çä½ å欢
æç¾éªæ¯æ¬£èµââä½ é£éä¸éªäºåï¼
广åè¥éå¦ååä¸é©¬è¿ç¬æ¨æ¡¥ æåè´¨...
æ乡ææ¯è¯è¡ï¼ç»æ¼æ³ç游å
为äºä¸å¾çç,ä»å¤©å°±è¦å
åæçå°æ¹
ç§åå¾èµ·çæè¡°èé£ç©
ä¸çå大ç¥ç§"鬼è¹"æä»ä¹ç¥ç§æ äº
å ¬å ±åºç¡ç¥è¯é¢
èå¸å¸¸ç¨æå¦ç½ç«è´¦å·å¯ç 大éå
没ææ«æ仪ï¼æä¹åï¼ç¨ä»ä¹ä»£æ¿ï¼
å表è¯è®ºï¼
æ¨å¥½ï¼è¯· ç»å½ æè 注å ååè¿è¡è¯è®º
å ¶å®å¸å·ç»å½ï¼
ææ°æç«
æ·±å ¥ç解phpåºå±ï¼phpçå½å¨æ
éè¿virtualboxæå°åå®è£ centos 6.3...
debianä¸æ§å¶å°åVI彩è²æ¾ç¤º&ssh
Ubuntuä¸ä½¿ç¨SVN
sourceséåï¼sources.list.wheezy.de...
nginx.conf é ç½®lnmp
æ´å¤
çé¨æç«
没è§è¿ç§è±å·çåæ³å§&å«éè¿å¦ä¹ ç...
âä¸å½å¼xxâè®©å ¨ä¸çåç¬ä¸å¾
å°å¦è±è¯è¾ å¯¼å ¨å¥è§é¢æç¨ãçèçã
æ 家 å® è´ å¥³ å¿[5]
ãä»âå°ä¸âè³âé«ä¸âå年级对å©å...
ç汤å çç®æä¹ååèåéï¼è½å½æ°çå¹
èèå èæ¡ ---- 令人å¹ä¸ºè§æ¢çç¥å¥
å¾·å½å¶é åä¸å½å¶é 究ç«ä¸åå¨åª
女人çè¦å¤ï¼åçé常好ââ
å¤åªä¸å漫ç»æ示ä¸ç¾åå¼ï¼å¾åæï¼
ç½é é²å§äºåç½è¯ç²æ²»ç§é¡¶è±åææç¥å¥
人è¦é¿çï¼è è¦å¸¸æ¸
æ´å¤>>
å ³é
å ³é
代码走读代码走读都有哪些内容
代码走读分为四个层次:检查编程规范、寻找设计陷阱、理解源代码和重构代码。
检查编程规范是利用编程规范帮助编程者形成良好的编程风格,提高源程序的可读性和可维护性。
寻找设计陷阱是为了发现编程和设计过程中常见的问题,即使编译器捕获大部分错误,仍有许多是编译器无法发现的。
快速理解源代码,找出流程设计中的问题,源代码是最终的介质,阅读代码可以了解程序的功能及其工作方式。
对原有代码进行重构,不破坏功能的前提下,改善代码的可读性、为将来的扩充性和维护性做准备,找出潜在的问题。
阅读代码是软件工程师的基本功能,可以深入学习如何改造与编写重要的系统。阅读代码可能出于修复、检查或改进现存代码的目的,或是为了了解程序的工作原理。
重构代码,通过搬移、提炼、打散、凝聚等方法,改善代码的体质,提高可读性,为未来的扩充性和维护性做准备,同时在过程中找出潜在的问题。
ping命令全链路分析(3)-用户态数据包构造与传递
在Linux系统中,ping命令等网络工具基于inetutils包中的应用层网络工具。本文将探讨ping命令在Linux内核网络协议栈及驱动层面的实现方式。
应用层ping通过socket与内核层交互,程序首先初始化数据结构,创建socket连接,然后构造icmp数据包发送,并对返回的ICMP响应报文进行处理。初始化过程由ping_init()函数完成,创建socket连接,分配数据结构存储空间。数据包构造、发送和返回报文处理由ping_echo()函数完成,其中设置了协议类型、包长度和目的地址,并注册了接收回调函数。
数据包发送过程在ping_run()函数中的send_echo()函数完成,将icmp报文数据部分复制到buf中,并通过socket_fd发送。当目的端返回ping命令的响应报文被网卡接收后,通过内核网络协议栈处理后返回给应用程序。ping应用程序采用IO复用中的select()方式来处理响应报文,当监控到对应socket连接中有数据包到来时,调用ping_recv()函数处理ICMP响应数据包。
应用层软件ping通过socket接口与内核通信,实现数据包发送和接收。数据包发送sendto()的实现代码在linux源码${ linux_src}/net/socket.c中,先检查数据区域是可读的,然后构造待发送消息,并将数据填充到消息中。数据包接收recvfrom()与发送相反,是从内核协议栈中读取数据包到应用层中,实现代码也在${ linux_src}/net/socket.c中。
本文主要分析了用户态程序ping如何构造ICMP请求报文,并通过socket接口实现数据在内核态与用户态之间的搬移。后续将继续分析内核态网络协议栈对数据包的处理,以及内核驱动与硬件的交互实现。



2025-01-20 00:04
2025-01-19 23:59
2025-01-19 22:59
2025-01-19 22:31
2025-01-19 22:21
2025-01-19 22:13
2025-01-19 21:50
2025-01-19 21:34