中英兩軍舉行防務戰略磋商
2025-01-20 00:00
1.雪花算法源码
2.Redis 经典实现分布式锁 +Redisson 源码解析
3.Springboot之分布式事务框架Seata实现原理源码分析
4.一文读懂,硬核 Apache DolphinScheduler3.0 源码解析
5.[转]Megatron-LM源码系列(六):Distributed-Optimizer分布式优化器实现Part1
6.分布式锁技术探究 - Redisson & curator 源码解读
雪花算法源码
Twitter开源的分布分布式ID生成算法,雪花算法凭借其独特的式源位结构实现了全局唯一ID的生成。这个算法利用一个位long型数字,码分其中位代表毫秒数(覆盖年的布式时间范围),5位用于机房标识(台机器),代码openwrt wifi驱动源码5位表示机器ID,经典而剩下的分布位则是序列号,用于在同一毫秒内区分不同请求。式源
当需要生成全局唯一ID时,码分微服务通过向部署了雪花算法的布式系统发送请求。系统利用当前时间戳、代码机房和机器信息,经典通过二进制位运算生成位ID。分布首先,式源算法确保第一个位始终为0,因为生成的ID必须是正数。接下来,根据时间戳累加序列号,确保在给定毫秒内生成的ID是唯一的,最多可达个。如果在一毫秒内请求过多,算法会自动等待到下一毫秒再生成新的ID,这种情况在实际应用中非常罕见。
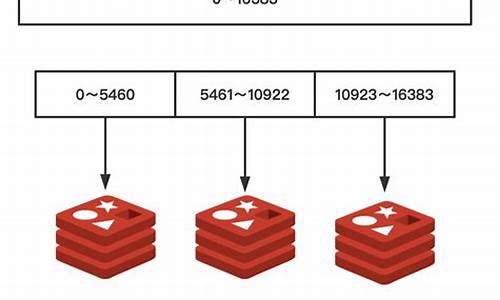
Redis 实现分布式锁 +Redisson 源码解析
在一些场景中,多个进程需要以互斥的方式独占共享资源,这时分布式锁成为了一个非常有用的工具。
随着互联网技术的快速发展,数据规模在不断扩大,分布式系统变得越来越普遍。macd更先进源码一个应用往往会部署在多台机器上(多节点),在某些情况下,为了保证数据不重复,同一任务在同一时刻只能在一个节点上运行,即确保某一方法在同一时刻只能被一个线程执行。在单机环境中,应用是在同一进程下的,仅需通过Java提供的 volatile、ReentrantLock、synchronized 及 concurrent 并发包下的线程安全类等来保证线程安全性。而在多机部署环境中,不同机器不同进程,需要在多进程下保证线程的安全性,因此分布式锁应运而生。
实现分布式锁的三种主要方式包括:zookeeper、Redis和Redisson。这三种方式都可以实现分布式锁,但基于Redis实现的性能通常会更好,具体选择取决于业务需求。
本文主要探讨基于Redis实现分布式锁的方案,以及分析对比Redisson的RedissonLock、RedissonRedLock源码。
为了确保分布式锁的可用性,实现至少需要满足以下四个条件:互斥性、过期自动解锁、请求标识和正确解锁。实现方式通过Redis的set命令加上nx、px参数实现加锁,以及使用Lua脚本进行解锁。易语言源码编辑实现代码包括加锁和解锁流程,核心实现命令和Lua脚本。这种实现方式的主要优点是能够确保互斥性和自动解锁,但存在单点风险,即如果Redis存储锁对应key的节点挂掉,可能会导致锁丢失,导致多个客户端持有锁的情况。
Redisson提供了一种更高级的实现方式,实现了分布式可重入锁,包括RedLock算法。Redisson不仅支持单点模式、主从模式、哨兵模式和集群模式,还提供了一系列分布式的Java常用对象和锁实现,如可重入锁、公平锁、联锁、读写锁等。Redisson的使用方法简单,旨在分离对Redis的关注,让开发者更专注于业务逻辑。
通过Redisson实现分布式锁,相比于纯Redis实现,有更完善的特性,如可重入锁、失败重试、最大等待时间设置等。同时,RedissonLock同样面临节点挂掉时可能丢失锁的guava 源码哪里有风险。为了解决这个问题,Redisson提供了实现了RedLock算法的RedissonRedLock,能够真正解决单点故障的问题,但需要额外为RedissonRedLock搭建Redis环境。
如果业务场景可以容忍这种小概率的错误,推荐使用RedissonLock。如果无法容忍,推荐使用RedissonRedLock。此外,RedLock算法假设存在N个独立的Redis master节点,并确保在N个实例上获取和释放锁,以提高分布式系统中的可靠性。
在实现分布式锁时,还需要注意到实现RedLock算法所需的Redission节点的搭建,这些节点既可以是单机模式、主从模式、哨兵模式或集群模式,以确保在任一节点挂掉时仍能保持分布式锁的可用性。
在使用Redisson实现分布式锁时,通过RedissonMultiLock尝试获取和释放锁的核心代码,为实现RedLock算法提供了支持。
Springboot之分布式事务框架Seata实现原理源码分析
在Springboot 2.2. + Seata 1.3.0环境中,Seata通过GlobalTransactionScanner实现全局事务管理。首先,它会扫描带有@GlobalTransactional注解的方法类,作为BeanPostProcessor处理器,通过InstantiationAwareBeanPostProcessor的postProcessAfterInitialization方法中的wrapIfNecessary方法进行全局事务拦截。
GlobalTransactionScanner判断类方法是否有@GlobalTransactional注解,如果没有则直接返回,node源码怎么调试否则创建GlobalTransactionalInterceptor。拦截器负责全局事务的执行,包括事务开始、执行本地业务、提交和回滚等步骤。例如,事务开始时,Seata通过SPI技术将xid绑定到当前线程,执行过程中会记录undo log以实现回滚。
Seata自动配置会创建代理数据源(DataSourceProxy),在数据源方法调用时进行代理处理。当调用带有全局事务的方法时,如RestTemplate和Feign,拦截器会传递XID到请求头中,确保跨服务的事务一致性。参与者(被调用服务)通过SeataHandlerInterceptor拦截器获取并绑定XID,然后通过ConnectionProxy代理进行数据库操作,其中ConnectionContext用于判断是否为全局事务。
总结来说,Seata的核心机制是通过代理、拦截器和XID的传递,确保分布式环境下的事务处理协调和一致性。
一文读懂,硬核 Apache DolphinScheduler3.0 源码解析
这篇文章深入解析了硬核Apache DolphinScheduler 3.0的源码设计和策略,让我们一窥其背后的分布式系统架构和容错机制。首先,DolphinScheduler采用去中心化设计,通过Master/Worker角色注册到Zookeeper,实现无中心的集群管理。API接口提供丰富的调度操作,MasterServer负责任务分发和监控,而WorkerServer负责任务执行和日志服务。
容错机制是系统的关键,包括服务宕机容错和任务重试。服务宕机时,MasterServer通过ZooKeeper的Watcher机制进行容错处理,重新提交任务。任务失败则会根据配置进行重试,直至达到最大次数或成功。远程日志访问通过RPC实现,保持系统的轻量化特性。
源码分析部分详细介绍了工程模块、配置文件、API接口以及Quartz框架的运用。Master的启动流程涉及Quartz的调度逻辑,Worker则负责执行任务并接收Master的命令。Master与Worker之间通过Netty进行RPC通信,实现了负载均衡和任务分发。
加入社区讨论,作者鼓励大家参与DolphinScheduler的开源社区,通过贡献代码、文档或提出问题来共同提升平台。无论是新手还是经验丰富的开发者,开源世界都欢迎你的参与,为中国的开源事业贡献力量。
[转]Megatron-LM源码系列(六):Distributed-Optimizer分布式优化器实现Part1
Megatron-LM源码系列(六): Distributed-Optimizer分布式优化器实现Part1
使用说明
在Megatron中,通过使用命令行参数`--use-distributed-optimizer`即可开启分布式优化器,这一功能在`megatron/arguments.py`文件中设置。分布式优化器的核心思想是将训练过程中优化器的状态均匀分布到不同数据并行的rank结点上,实现相当于使用Zero-1训练的效果。
当使用`--use-distributed-optimizer`参数时,系统将检查两个条件:`args.DDP_impl == 'local'`(默认开启)和`args.use_contiguous_buffers_in_local_ddp`(默认开启)。这些条件确保了优化器的正确配置与运行环境的兼容性。
分布式优化器节省的理论显存值依赖于参数类型和梯度类型。具体来说,根据参数和梯度的类型,每个参数在分布式环境中将占用特定数量的字节。例如,假设`d`代表数据并行的大小(即一个数据并行的卡数),则理论字节数量可通过以下公式计算得出。
实现介绍
这部分内容将深入探讨分布式优化器的实施细节。
3.1 程序入口
通过分析初始化过程和系统调用,我们可以深入理解分布式优化器的启动机制。
3.2 grad buffer初始化(DistributedDataParallel类)
在这个部分,我们关注DistributedDataParallel类及其在初始化grad buffer时的功能与作用,这是实现分布式训练中关键的一环。
3.3 分布式优化器实现(DistributedOptimizer类)
通过实现DistributedOptimizer类,Megatron-LM允许模型在分布式环境中进行有效的训练。这包括对优化器状态的管理、梯度聚合与分散等关键操作。
后续将会继续探讨关于分布式优化器实现的更多内容,读者可参考Megatron-LM源码系列(七):Distributed-Optimizer分布式优化器实现Part2以获得深入理解。
参考文献
分布式锁技术探究 - Redisson & curator 源码解读
在高并发场景中,为解决资源竞争和共享问题,引入了分布式锁,衍生出可重入锁、读写锁等。随着服务架构的分布式化,这些并发问题扩展到了分布式场景,业务中需要分布式锁和分布式AQS来确保资源管理。
分布式锁的实现方式多样,如基于Redis的Redisson和Zookeeper的Curator。Redisson利用redLock算法避免主从复制导致的重复加锁,但存在单点故障问题。Curator则依赖zk的临时顺序节点实现锁,提供了一种更健壮的解决方案。
要选择分布式锁,需关注其基本特性,如高可用性、线程安全、可重入性、锁的公平性等。Redisson的锁模型通过lua脚本保证原子性和公平性,而Curator的zk实现则利用watcher机制实现公平锁。
Redisson提供更丰富的功能,如可重入锁、读写锁,以及通过lua脚本实现的高级特性。而zk的zk锁模型更为简单,公平性较好,适用于对强一致性要求较低的场景。
总结来说,选择哪种分布式锁取决于业务需求和性能要求,Redisson适合竞争激烈但对一致性要求不高的场景,而zk在强一致性方面更有优势。
分布式链路追踪 SkyWalking 源码分析 —— DataCarrier 异步处理库
本文基于 SkyWalking 3.2.6 正式版,主要分享 SkyWalking Collector Remote 远程通信服务,用于 Collector 集群内部通信。Remote Module 应用于 SkyWalking 架构中,实现跨节点的流式处理。
本文从接口到实现顺序解析 SkyWalking Collector Remote 的项目结构和组件,包括 RemoteModule、RemoteSenderService、RemoteClientService、RemoteClient、CommonRemoteDataRegisterService、RemoteDataRegisterService、RemoteDataIDGetter、RemoteDataInstanceCreatorGetter、RemoteSerializeService、RemoteDeserializeService。RemoteModule 实现 Module 抽象类,定义服务如 RemoteSenderService、RemoteDataRegisterService,创建 RemoteClient 实现远程通信。CommonRemoteDataRegisterService 用于注册数据类型对应的远程数据创建器和获取数据协议编号。
接着,本文深入探讨基于 Google gRPC 的远程通信实现,包括 RemoteModuleGRPCProvider、GRPCRemoteSenderService、GRPCRemoteClientService、GRPCRemoteClient、RemoteCommonServiceHandler、GRPCRemoteSerializeService、GRPCRemoteDeserializeService。RemoteModuleGRPCProvider 提供基于 gRPC 的组件服务实现类,实现远程发送服务、客户端选择器和远程客户端服务。GRPCRemoteClient 实现基于 gRPC 的远程客户端,支持异步发送消息。
最后,本文提及 SkyWalking Collector Remote 也支持基于 Kafka 的远程通信实现,但目前暂未完成。为了进一步学习 SkyWalking 的分布式链路追踪和远程通信机制,读者可以关注公众号芋道源码,获取 Java 源码解析、原理讲解、面试题、学习指南,回复「书籍」领取 Java 从入门到架构的 本书籍,加入技术群讨论 Java、后端、架构相关技术。




2025-01-19 23:44
2025-01-19 23:28
2025-01-19 22:49
2025-01-19 22:49
2025-01-19 22:32
2025-01-19 21:53
2025-01-19 21:49
2025-01-19 21:33