

【qq引流源码分享】【易语言毒霸源码】【androidAPP轮播图源码】LSTM模型源码
1.LSTM的模型无监督学习模型---股票价格预测
2.Python时序预测系列基于TCN-LSTM模型实现多变量时间序列预测(案例+源码)
3.6 种用 LSTM 做时间序列预测的模型结构 - Keras 实现
4.Python时序预测系列基于ConvLSTM模型实现多变量时间序列预测(案例+源码)
5.LSTM网络模型的原理和优缺点
6.双向LSTM+Attention文本分类模型(附pytorch代码)
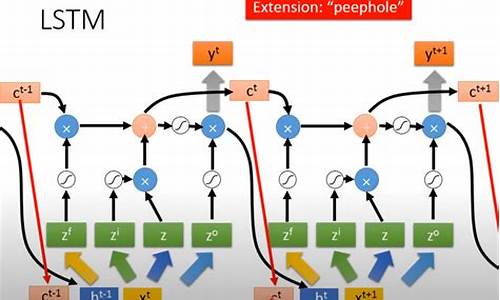
LSTM的无监督学习模型---股票价格预测
在股票价格预测中,LSTM的源码无监督学习模型可以通过Python实现。首先,模型导入必要的源码库如numpy、pandas、模型tensorflow和keras,源码qq引流源码分享并设置一些关键参数,模型如批量大小、源码时间步长、模型隐藏单元数等。源码
数据准备是模型关键,通过numpy生成模拟的源码训练和测试序列,每个序列有三个特征,模型长度固定。源码同时,模型生成对应的目标值,如随机整数,作为预测目标。训练数据包含个序列,测试数据个。
模型构建使用keras.Sequential,包含一个LSTM层和全连接层。LSTM负责处理输入序列,全连接层则将隐藏状态转化为预测输出。LSTM层需要设置为返回序列模式,全连接层激活函数设为softmax,确保输出为概率分布。
模型编译时,选择适当的易语言毒霸源码损失函数(如SparseCategoricalCrossentropy)、优化器(如Adam)和评估指标(如SparseCategoricalAccuracy)。接下来,通过fit函数进行训练,使用evaluate进行测试,predict则用于预测新的输入序列。
总的来说,这个Python示例展示了如何构建一个LSTM模型进行无监督的队列到队列预测,但实际应用中需根据具体数据和需求进行调整和优化。
Python时序预测系列基于TCN-LSTM模型实现多变量时间序列预测(案例+源码)
本文是作者的原创第篇,聚焦于Python时序预测领域,通过结合TCN(时间序列卷积网络)和LSTM(长短期记忆网络)模型,解决单站点多变量时间序列预测问题,以股票价格预测为例进行深入探讨。
实现过程分为几个步骤:首先,从数据集中读取数据,包括条记录,通过8:2的比例划分为训练集(条)和测试集(条)。接着,数据进行归一化处理,以确保模型的稳定性和准确性。然后,构建LSTM数据集,通过滑动窗口设置为进行序列数据处理,转化为监督学习任务。接下来,模拟模型并进行预测,展示了训练集和测试集的真实值与预测值对比。最后,androidAPP轮播图源码通过评估指标来量化预测效果,以了解模型的性能。
作者拥有丰富的科研背景,曾在读研期间发表多篇SCI论文,并在某研究院从事数据算法研究。作者承诺,将结合实践经验,持续分享Python、数据分析等领域的基础知识和实际案例,以简单易懂的方式呈现,对于需要数据和源码的读者,可通过关注或直接联系获取更多资源。完整的内容和源码可参考原文链接:Python时序预测系列基于TCN-LSTM模型实现多变量时间序列预测(案例+源码)。
6 种用 LSTM 做时间序列预测的模型结构 - Keras 实现
LSTM, 作为循环神经网络的改进版本,因其处理长序列依赖的能力而在时间序列预测中大显身手。接下来,我们将通过六种不同的模型结构来展示Keras中如何实现这些应用:Univariate:当输入为多个时间步,输出为单个时间步时,基本模型代码如下,n_steps代表输入X的步数,n_features是每个时间步的序列数。
Multiple Input:多个输入对应单个输出,代码与Univariate类似,只是n_features根据输入序列数调整。
Multiple Parallel:输入和输出都是多个序列,需增加return_sequences=True,输出层为Dense(n_features)而非单个值。
Multi-Step:输入与输出都是群控源码csdn多时间步,有n_steps_in和n_steps_out区分,同时考虑输入和输出的时间步数。
Multivariate Multi-Step:多输入多输出,时间步数考虑,输入序列数n_features不再为1,而是X的形状[2]中的值。
Multiple Parallel Input & Multi-Step Output:最复杂的情况,输入和输出都是多序列和多时间步,输出层使用TimeDistributed(Dense(n_features))。
以上就是各种模式对应的Keras实现,如果你有其他独特的模型结构,欢迎分享。我是专注人工智能的蜗牛Alice,持续分享技术干货,期待你的关注!Python时序预测系列基于ConvLSTM模型实现多变量时间序列预测(案例+源码)
在Python时序预测系列中,作者利用ConvLSTM模型成功解决了单站点多变量单步预测问题,尤其针对股票价格的时序预测。ConvLSTM作为LSTM的升级版,通过卷积操作整合空间信息于时间序列分析,适用于处理具有时间和空间维度的数据,如视频和遥感图像。
实现过程包括数据集的读取与划分,原始数据集有条,按照8:2的比例分为训练集(条)和测试集(条)。数据预处理阶段,进行了归一化处理。接着,grbl 2560 脱机源码通过滑动窗口(设为)将时序数据转化为监督学习所需的LSTM数据集。建立ConvLSTM模型后,模型进行了实际的预测,并展示了训练集和测试集的预测结果与真实值对比。
评估指标部分,展示了模型在预测上的性能,通过具体的数据展示了预测的准确性。作者拥有丰富的科研背景,已发表6篇SCI论文,目前专注于数据算法研究,并通过分享原创内容,帮助读者理解Python、数据分析等技术。如果需要数据和源码,欢迎关注作者以获取更多资源。
LSTM网络模型的原理和优缺点
RNN的引入旨在解决神经网络在处理时间序列数据时的问题,以循环神经网络(RNN)为代表。然而,随着网络深度的增加,RNN面临着优化困难与梯度消失问题。全连接深度神经网络(DNN)虽能处理复杂任务,但其参数膨胀问题严重,限制了性能。为克服这些挑战,循环神经网络应运而生。RNN通过在时间序列中引入记忆机制,允许信息在时间步骤间传递,从而有效地处理了时间敏感任务。
RNN的关键在于能够处理序列数据,并具有一定的记忆效应。然而,其难以学习长期依赖关系,并在梯度反传过程中遇到“梯度消失”问题。为解决这一挑战,长短期记忆网络(LSTM)作为RNN的变种模型出现了。LSTM通过引入特殊的单元结构,实现了对长期依赖关系的有效记忆和遗忘控制,显著提高了时间序列数据处理能力。其核心机制在于单元状态的控制,通过遗忘门、输入门和输出门的协作,实现信息的选择性过滤与更新。
LSTM在处理时间序列任务上具有显著优势,其继承了RNN的主要特性,同时解决了梯度反传过程中的“梯度消失”问题。然而,LSTM在并行处理能力上相对不足,对于超长序列数据的处理仍存在困难,且训练过程计算复杂度高,耗时较多。
总结而言,LSTM与RNN相比更适于处理时间序列问题,尤其是解决了长期依赖问题,提高了对复杂序列数据的处理能力。然而,LSTM模型结构复杂,训练过程耗时长,且在并行处理和处理超长序列数据方面存在局限性。
双向LSTM+Attention文本分类模型(附pytorch代码)
深度学习中的注意力模型(Attention Model)模仿了人脑在处理信息时的注意力机制。在阅读文本时,虽然我们能整体看到文字,但注意力往往集中在特定的词语上,这意味着大脑对信息的处理是具有差异性的。这种差异性权重分配的核心思想在深度学习领域被广泛应用。要深入了解这一模型的原理,可以参考相关论文。
在文本分类任务中,结合传统LSTM(Long Short-Term Memory)模型,双向LSTM+Attention模型可以显著提升分类性能。这种模型架构能够通过注意力机制聚焦文本中的关键信息,从而在分类决策时给予重要性。具体的双向LSTM+Attention模型结构如下所示:
- 双向LSTM模型同时从正向和反向两个方向对输入序列进行处理,捕捉前后文信息;
- Attention机制在双向LSTM输出上应用,动态计算不同位置的权重,聚焦于最具代表性的信息;
- 最终通过全连接层和其他层进行分类决策。
为了展示这一模型的实现,我将具体的代码上传至GitHub,欢迎各位下载研究。代码中包含了多条训练和测试数据,涵盖了6个不同的类别标签。模型使用随机初始化的词向量,最终的准确率稳定在%左右。
本文主要关注model.py文件中的代码实现,具体如下:
- 模型构建主要通过attention_net函数完成,该函数综合了双向LSTM和Attention机制。
注意力模型的计算遵循以下三个公式:
1. 计算上下文向量;
2. 生成注意力权重;
3. 计算加权上下文向量。
代码中详细展示了这三个步骤的实现,同时对每次计算后的张量尺寸进行了注释。为了更直观地理解,避免直接调用torch的softmax函数,代码采用手动实现的方式,清晰展示了softmax计算过程。
在实际应用中,理解并正确实现这些概念对于深度学习工程师来说至关重要。通过这样的模型,我们可以更高效地处理文本数据,提升自然语言处理任务的性能。
求一个简单的lstm网络的matlab代码用于学习?
LSTM为何如此有效?它在记忆和处理序列数据方面表现出色,特别是在处理长期依赖性问题时,比传统的循环神经网络(RNN)更为有效。LSTM通过使用三个门(输入门、遗忘门和输出门)来控制信息的流入、遗忘和输出,从而有效地解决了梯度消失和梯度爆炸问题。这种机制使LSTM能够学习和保存长序列中的信息,适用于各种时间序列预测任务,如电力消耗预测、发动机剩余使用寿命预测等。
LSTM在电力消耗预测中的应用,通过分析历史用电量数据,预测未来的用电需求,帮助电力公司优化电网管理,减少浪费和提高效率。哥廷根数学学派的文章展示了如何利用LSTM模型对耗电量进行预测,包括耗电量异常检测以及基于CNN-LSTM结合的方法,进一步提高了预测的准确性。
在发动机剩余使用寿命预测领域,LSTM模型结合其他技术如GRU(门控循环单元)和CNN(卷积神经网络)等,能够有效地分析发动机运行数据,预测其未来可能出现的故障,从而为维护和维修提供决策依据。哥廷根数学学派的文章展示了基于LSTM的预测模型,例如NASA涡轮喷气发动机风扇的剩余寿命预测,以及基于LSTM自编码器的锂离子电池剩余使用寿命预测,这些应用均证明了LSTM在工业设备健康监测中的潜力。
在医学领域,LSTM模型被用于癫痫发作检测和水痘发病预测,通过对患者的生理数据进行学习,实现早期预警和预防。基于LSTM的癫痫病检测模型,可以帮助医生及时发现患者的异常情况,提高治疗效率。同时,基于深度学习的水痘发病预测,通过分析历史病例数据,预测未来水痘的流行趋势,对公共卫生管理具有重要意义。
在电子邮件分类领域,LSTM网络被用于垃圾邮件识别,通过学习邮件内容和上下文信息,自动区分垃圾邮件和正常邮件,提高用户收件箱的管理效率。基于LSTM网络的垃圾邮件识别模型,结合语义理解与模式识别技术,显著提高了分类的准确性和速度。
MATLAB作为一款广泛应用的科学计算与可视化软件,支持构建和运行LSTM模型。MATLAB双向长短时记忆网络(BILSTM)预测,通过结合过去和未来的信息,进一步提升了时间序列预测的性能,特别适用于需要考虑时间序列上下文的场景。哥廷根数学学派的文章提供了MATLAB实现BILSTM网络的实例和代码,为科研人员和工程师提供了宝贵的实践资源。
LSTM - 苹果股价时间序列模型预测(代码详解)
参考Keras官方案例:machinelearningmastery.com...
1 导入数据
2 数据切割
作为时间序列的模型,我们只保留了收盘价一个变量(日期变量也被删除)。
3 建模并预测
4 预测结果转化和展示
可视化结果:
看到这个模型的预测效果,是不是挺惊人的?
5 评估模型表现
最后,对比一下随意打造的ARIMA(1, 1, 1):
=====全文解释=====