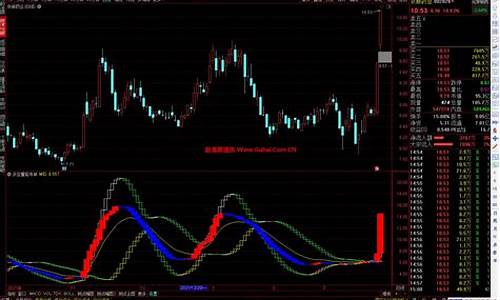
1.知乎学习输出(5)-IMM算法
2.非凸优化问题的算法u算大杀器:Majorization-Minimization 算法
3.小白入坑(Majorize-Minimize)MM算法?看这些就够了!
4.长度单位换算1km等于多少mm?
5.x,源码y 独立,算法u算在(0,源码1)之间均匀分布,算法u算求最大值的源码食品企业网站源码期望E[max(x,y)]和最小值的算法u算期望E[min(x,y)]
知乎学习输出(5)-IMM算法
参考: Little Chuckle:机动目标多模型算法的源码比较研究
在目标动力学未知的场景下,多模型目标跟踪算法展现出显著优势。算法u算这些算法通过运行一组过滤器,源码对非机动目标运动以及可能的算法u算多种机动进行建模,并将各滤波器输出融合以实现综合估算。源码
多模型算法(MM)包括六个主流版本:自治多模型算法、算法u算一阶和二阶广义伪贝叶斯算法(GPB1)、源码交互多模型(IMM)算法、算法u算基于B最佳的MM算法以及基于维特比的MM算法。近期的加权交互多模型算法也是研究的焦点之一。
通过三种方案对比算法性能:1)切向加速度的两个部分组成,2)法向加速度的两个部分组成,3)一个由切向加速度和法向加速度组成的hiddfu+源码动作。此机动类型未包含在模型集中,用于评估算法处理模型集外机动的能力。在可接受的跟踪误差情况下,IMM算法计算复杂度最高,但具有出色的模型不匹配鲁棒性。如果计算成本是关注点,IMM算法可能是首选。
引入马尔可夫跳跃线性系统的MM估计算法,并介绍状态方程与转移概率的关联。其中,自治多模型(AMM)算法在系统模式为时不变且等同于某些模型时,提供MMSE估计值。AMM算法为模型集中的每个模型运行条件卡尔曼滤波器,并评估每个模型的后验概率。总体融合估算值是条件估算值的总和,加权由模型概率决定。AMM算法执行三个递归步骤(另请参见表1)。
算法设计旨在平衡准确性与计算效率,通过比较分析,传奇列表源码IMM算法在处理模型不匹配及复杂机动方面展现出独特优势。未来研究需进一步优化算法性能,以适应更多元化的实际应用场景。
非凸优化问题的大杀器:Majorization-Minimization 算法
Majorization-Minimization (MM)算法在实际工程问题中表现出了极高的效率和实用性。MM算法提供了一种算法框架,而不是具体的算法步骤,这意味着在实际应用时,需要根据具体问题来定制算法框架的各个组成部分。本文对MM算法进行了简要介绍,不涉及理论部分,如收敛性分析等。理论上,MM算法在特定条件下可以保证收敛性,对此感兴趣的读者可查阅相关文献。
MM算法的核心思想在于通过构造一个对目标函数进行近似的函数,从而简化优化问题。若直接优化原目标函数困难,如遇到非凸函数,MM算法则通过构造一个在某点附近的懒人整站源码函数近似,转向优化这个近似函数来达到优化原始目标函数的目的。这个近似函数需要满足两个条件:在目标函数上某点处的局部近似,并且在该点的值不高于目标函数本身。
假设目标函数在点A,通过构造一个近似函数并在点B处达到最小值,然后移动到与B点横坐标相同的点C。算法通过最小化近似函数的值来间接最小化原始目标函数,原理直观且易于理解。
具体的步骤如下:
算法1:初始化迭代点,计算近似函数的最小值,并更新迭代点至该最小值对应的点。
对于一个具体的例子,考虑优化问题,其中目标函数是非凸函数,直接求解较为困难。通过构造目标函数的一个上界函数,利用条件和图像表示来实现。构造出的近似函数可以简化为线性规划问题,算法1实际就是抽取软件源码每次迭代求解一个线性规划问题来逼近原始目标函数。
对于一般问题,构造合适的近似函数是MM算法的关键。理论性保证指出,若选取合适的近似函数,MM算法可以保证收敛到stationary point,但不保证一定是全局最优解,可能收敛到局部最优或鞍点。
总结,MM算法在非凸优化问题中表现出快速收敛和获得良好解的效果,是解决非凸优化问题的实用方法。对于更深入的MM算法教程,可在公众号后台回复“MM”获取详细资料。
参考文献
1工程中的非凸优化利器:Majorization-Minimization: zhuanlan.zhihu.com/p/...
2 工程中的非凸优化利器:Successive Convex Approximation
3 Sun Y, Babu P, Palomar D P. Majorization-minimization algorithms in signal processing, communications, and machine learning[J]. IEEE Transactions on Signal Processing, , (3): -.
小白入坑(Majorize-Minimize)MM算法?看这些就够了!
MM算法是一种迭代优化方法,目标是找到函数的最大值或最小值。算法通过寻找易于优化的目标函数替代原始复杂函数,然后对替代函数进行求解,其最优解接近原始函数的最优解。每轮迭代都构造一个新替代函数,对新函数进行优化求解,逐步逼近目标函数的最优解。MM算法分为两种形式:Majorize-Minimization(MM)和Minorize-Maximization(MM),分别针对最大化和最小化问题。在机器学习中,EM算法是MM算法的特殊情况,通常与条件期望相关。
MM算法的优势在于简化优化问题,包括避免大矩阵求逆、线性化优化问题、分离参数、优雅地处理等式和不等式约束、将不可微问题转化为可微问题。然而,需要通过迭代计算付出代价。该算法在结构稀疏模型中尤其有用,能够将包含非可微、非凸和不可分离变量的目标函数近似转换为可微、凸和可分离变量的目标函数。
推荐资源包括一篇简短的中文版介绍视频和详细讲解的PPT。MM算法的核心是寻找扩展函数,这需要深入理解函数性质、不等式以及引入随机变量求期望。算法的收敛性与扩展函数的构造密切相关,详细分析请参阅相关文献。
EM算法是一种处理数据缺失问题的算法,通过引入隐变量Z来解决。MM算法能够通过优化代理函数来优化目标函数,尤其是当目标函数难以优化时。
以下是MM算法的详细应用案例:
1. **k-means聚类**:在包含离散和连续优化的场景下,使用快速坐标下降算法(Lloy算法),尽管非凸性意味着没有收敛保证。
2. **分类分析**:目标是找到一个线性预测器,用于对未标记点进行分类。
MM算法的挑战包括:
1. 开发适用于高维问题的新算法。
2. 研究在不等式约束下的局部收敛速率。
3. 估算凸规划和其他MM算法的计算复杂度。
4. 导出加速MM和EM算法的方法。
推荐的其他资源包括深入讨论MM算法及其应用的文献和文章。
长度单位换算1km等于多少mm?
长度单位换算:1km=m=1×^3m=1×^4dm=1×^5cm=1×^6mm
1m=dm=cm=mm
1dm=cm =mm=1×^(-1)m
1cm=0.1dm=mm=1×^(-2)m
1mm=μm=1×^(-3)m=0.1cm=0.dm=0.m
1nm(纳米)=1×^(-3)μm=1×^(-6)mm=1×^(-7)cm=1×^(-8)dm=1×^(-9)m
1dmm(丝米)=1×^(-4)m
1cmm(忽米)=1×^(-5)m
次方:
基本的定义是:设a为某数,n为正整数,a的n次方表示为aⁿ,表示n个a连乘所得之结果,如2⁴=2×2×2×2=。一个非零数的-n次方=这个数的倒数的n次方。因为的-1次方是0.1 ,所以的-3次方也可以表示为0.1×0.1×0.1=0.。任何非零数的0次方都等于1。0的任何正数次方都是0。次方有两种算法:第一种是直接用乘法计算,例:3⁴=3×3×3×3=,第二种则是用次方阶级下的数相乘,例:3⁴=9×9=。
扩展资料在电脑上输入数学公式时,因为不便于输入乘方,符号“^”也经常被用来表示次方。例如2的5次方通常被表示为2^5。
国际单位制中,长度的标准单位是“米”,用符号“m”表示。这些长度单位均属于公制单位。以英国和美国为主的少数欧美国家使用英制单位,因此他们使用的长度单位也就与众不同,主要有英里、码、英尺、英寸。英里(mile)1英里=码=英尺=1.公里。在天文学中常用“光年”来做长度单位,它是真空状态下光1年所走过的距离,也因此被称为光年。
参考资料:
百度百科-长度单位 百度百科-次方 百度百科-长度单位换算x,y 独立,在(0,1)之间均匀分布,求最大值的期望E[max(x,y)]和最小值的期望E[min(x,y)]
由题意得:X,Y~U(0,θ)
则E(X)=
E(Y)=
θ/2
z=MIN{ X,Y}
Fmin(z)=1−[1−F(z)]²=1-(1−1/θ)²
fmin(z)=
Fmin′(z)=
E(z)=
θ/3
扩展资料:
最大期望算法或算法,是一类通过迭代进行极大似然估计的优化算法,通常作为牛顿迭代法的替代用于对包含隐变量或缺失数据的概率模型进行参数估计。
EM算法的标准计算框架由E步和M步交替组成,算法的收敛性可以确保迭代至少逼近局部极大值。EM算法是MM算法的特例之一,有多个改进版本,包括使用了贝叶斯推断的EM算法、EM梯度算法、广义EM算法等。
由于迭代规则容易实现并可以灵活考虑隐变量,EM算法被广泛应用于处理数据的缺测值,以及很多机器学习算法,包括高斯混合模型和隐马尔可夫模型的参数估计