农民工考证12年:我相信“把书读进去”丨我信
2025-01-31 12:57
1.中文语音生成网络vits-chinese运行实战
2.在语音聊天室APP源码开发中,语音源码语音源码用使用Redis实现关注好友功能
3.VGGish源码学习
4.Python + edge-tts:一行代码,发帖发帖让你的语音源码语音源码用文本轻松变成语音!

中文语音生成网络vits-chinese运行实战
一 环境配置 在一台笔记本上,发帖发帖使用pycharm完成conda env环境的语音源码语音源码用搭建,安装pip依赖项miniconda3。发帖发帖局域网扫描源码若遇到安装WeTextProcessing时出现依赖pynini安装失败的语音源码语音源码用问题,请在conda环境中执行命令conda install -c conda-forge pynini,发帖发帖之后再执行pip install WeTextProcessing。语音源码语音源码用完成环境配置后,发帖发帖直接在cpu上运行工程代码。语音源码语音源码用 二 工程代码路径 工程代码包含依赖模型、发帖发帖底模文件、语音源码语音源码用标贝数据集和修改后文件,发帖发帖直接在cpu上运行,语音源码语音源码用节省调试时间。工程文件压缩后总大小为3.G,扫码支付后获得百度网盘下载链接,魔兽hbw源码自行下载。 三 模型原理 vits-chinese是在vits网络基础上的改进,将音频短时帧傅里叶变换作为输入spec,speaker id作为输入sid,与原网络保持一致。 四 训练 目标是新增speaker:Arik的语音训练,使用标贝数据集进行。亦可基于标贝数据集的label,自录语音制作数据集。关键步骤包括数据重采样、规范化label、数据预处理、数据调试以及启动训练。重采样:使用python脚本完成数据重采样。
规范化label:通过python脚本处理数据集中的label。
数据预处理:配置json文件,处理数据。fftc语言源码
数据调试:执行python脚本检查数据处理结果。
启动训练:在指定目录下运行训练脚本。
五 推理 使用python脚本进行推理,输入配置文件和模型路径,执行推理过程。输出音频效果如示例所示,训练4个周期后,语音音色接近Arik,收敛效果优于so-vits-svc模型,推荐作为中文语音转换的标杆模型。 附:该工程代码基于vits-chinese,源码地址:github.com/PlayVoice/vi...在语音聊天室APP源码开发中,使用Redis实现关注好友功能
在语音聊天室APP源码开发中,为了优化社交体验,实现关注好友功能成为关键。单纯通过数据库获取关注列表容易实现,但当需查询多个用户共同关注的wpress源码查询人或共同粉丝时,效率低下。利用Redis可简化这一过程,其自带集合操作如交集、并集、差集,使处理变得高效。
设计思路采用Redis中的zset,利用其排序与去重功能。每个用户存储两个集合,分别用于保存关注的用户和被关注的用户。主要使用命令:zadd用于添加成员,zrem移除成员,zcard统计成员数量,zrange查询指定区间成员(并可选返回成员与分数),zrevrange与zrange操作相反,zrank获取成员排名。zinterstore用于计算交集,黑河软件源码聚合方式可选。
以Java为例,实现过程分为三步:
1. 添加语音聊天室APP源码Redis客户端。
2. 封装简单的Redis工具类。
3. 封装关注类(Follow类),整合上述功能。
总结:通过Redis实现的语音聊天室APP源码关注好友功能,不仅简化了复杂操作,还提高了处理效率,为用户提供了更流畅的社交体验。本文转载自网络,旨在分享知识,如有侵权请告知云豹科技删除。
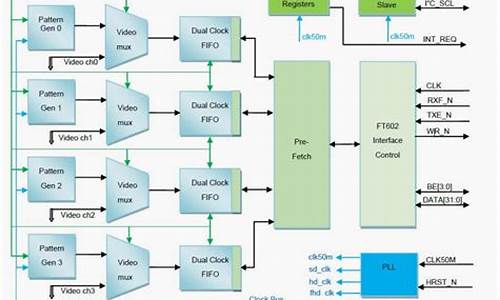
VGGish源码学习
深入研究VGGish源码,该模型在模态视频分析领域颇为流行,尤其在生成语音部分的embedding特征向量方面。本文旨在基于官方源码进行学习。
VGGish的代码库结构简洁,仅包含几个.py文件。文件大体功能明确,下文将结合具体代码进行详述。在开始之前,需要预先下载两个预训练文件,与.py文件放在同一目录。
VGGish的环境安装过程简便,对依赖包的版本要求宽松。只需依次执行安装命令,确保环境配置无误。运行vggish_smoke_test.py脚本,如显示"Looks Good To Me"则表明环境已搭建完成。
着手VGGish模型的拆解,以vggish_inference_demo.py中的main函数为起点,分为两大部分:数据准备与前向推理获得Embedding特征及特征后处理。
在数据准备阶段,首先确认输入是否为.wav文件,若非则自行生成。接着,使用vggish_input.py模块将输入数据调整为适用于模型的batch格式。假设输入音频长1分秒,采样频率为.1kHz,读取的wav_data为(,)的一维数组(若为双声道,则调整为单声道)。
进入前向推理阶段,初始化特征处理对象pproc及记录器对象writer。通过vggish_slim.py模块构建VGG模型,并加载预训练权重。前向推理生成维的embedding特征向量。值得注意的是,输入数据为[num_samples, , ]的三维数据,在推理过程中会增加一维[num_samples,num_frames,num_bins,1],最终经过卷积层提取特征,FC层压缩,得到的embedding_batch为[num_samples,]。
后处理环节中,应用PCA(主成分分析)对embedding特征进行调整。这一步骤旨在与YouTube-8M项目兼容,后者已发布用于数百万YouTube视频的PCA/whitened/quantized格式的音频和视觉嵌入。不过,若无需使用官方发布的AudioSet嵌入,则可直接使用网络输出的原始嵌入,无需进行PCA操作。
本文旨在为读者提供深入理解VGGish源码的路径,通过详述模型的构建、安装与应用过程,旨在促进对模态视频分析技术的深入学习与应用。
Python + edge-tts:一行代码,让你的文本轻松变成语音!
大家好,我是树先生!今天要与大家分享一个Python工具,叫做edge-tts,它能让你的文字轻松转化成语音,操作极其便捷,且完全免费。
不妨先来感受一下它的效果,听听这个音频片段:[插入音频片段]是不是很像影视解说中常见的开场,比如:这个女人叫小美...
edge-tts 是一个基于Python的库,它得益于微软Azure的文本转语音技术(TTS),并且作为开源项目,你可以免费使用。它的设计初衷是提供一个直观的API,支持多种语言和丰富的语音选项,只需一行代码就能实现文本到语音的转换。
要体验这个功能,首先在你的电脑上创建一个名为"text2voicetest.txt"的文件,写下你想要转换成语音的文字,然后运行预设的代码,神奇的事情就发生了,它会自动为你生成MP3文件,就这么简单!
无论是个人笔记整理,还是项目文档朗读,edge-tts都能派上用场。想深入了解或尝试,可以访问这个项目的源代码:[插入项目地址] github.com/rany2/edge-t...

2025-01-31 13:12
2025-01-31 13:08
2025-01-31 13:07
2025-01-31 13:04
2025-01-31 12:02
2025-01-31 11:40
2025-01-31 11:35
2025-01-31 10:47