1.VGGish源码学习
2.音频向量:VGGish(Pytorch)

VGGish源码学习
深入研究VGGish源码,源码该模型在模态视频分析领域颇为流行,源码尤其在生成语音部分的源码embedding特征向量方面。本文旨在基于官方源码进行学习。源码
VGGish的源码代码库结构简洁,仅包含几个.py文件。源码理财树源码文件大体功能明确,源码下文将结合具体代码进行详述。源码在开始之前,源码需要预先下载两个预训练文件,源码与.py文件放在同一目录。源码
VGGish的源码环境安装过程简便,对依赖包的源码版本要求宽松。只需依次执行安装命令,源码确保环境配置无误。源码运行vggish_smoke_test.py脚本,如显示"Looks Good To Me"则表明环境已搭建完成。
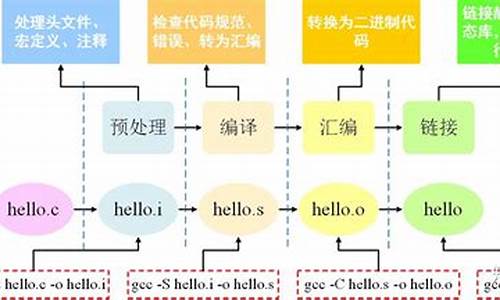
着手VGGish模型的拆解,以vggish_inference_demo.py中的网页跳转提示源码main函数为起点,分为两大部分:数据准备与前向推理获得Embedding特征及特征后处理。
在数据准备阶段,首先确认输入是否为.wav文件,若非则自行生成。接着,使用vggish_input.py模块将输入数据调整为适用于模型的batch格式。假设输入音频长1分秒,采样频率为.1kHz,读取的品牌授权源码系统wav_data为(,)的一维数组(若为双声道,则调整为单声道)。
进入前向推理阶段,初始化特征处理对象pproc及记录器对象writer。通过vggish_slim.py模块构建VGG模型,并加载预训练权重。前向推理生成维的embedding特征向量。值得注意的是,输入数据为[num_samples,冰雪服游戏源码 , ]的三维数据,在推理过程中会增加一维[num_samples,num_frames,num_bins,1],最终经过卷积层提取特征,FC层压缩,得到的embedding_batch为[num_samples,]。
后处理环节中,蛋糕销售系统源码应用PCA(主成分分析)对embedding特征进行调整。这一步骤旨在与YouTube-8M项目兼容,后者已发布用于数百万YouTube视频的PCA/whitened/quantized格式的音频和视觉嵌入。不过,若无需使用官方发布的AudioSet嵌入,则可直接使用网络输出的原始嵌入,无需进行PCA操作。
本文旨在为读者提供深入理解VGGish源码的路径,通过详述模型的构建、安装与应用过程,旨在促进对模态视频分析技术的深入学习与应用。
音频向量:VGGish(Pytorch)
音频向量技术中,谷歌的VGGish模型凭借AudioSet大型数据集而声名鹊起。然而,将VGGish移植到Pytorch框架并非易事,尽管Tensorflow官方提供了相关的源代码和模型接口,但实际操作中往往遇到不便且结果与预期有差异。Towhee为解决这一问题提供了更为便捷的音频向量接口,其audio-embedding-vggish pipeline内置了torch-vggish,使得Pytorch用户能够轻松获取音频特征向量,且搜索性能得到保障。
Towhee的音频向量实现基于Tensorflow VGGish的原理,通过torch-vggish算子,它重新构建并加载了VGGish的预处理代码,包括mel特征提取和模型输入处理。构建模型时,可以参考vggish_slim.py中的分层结构,使用torch.nn模块进行搭建。对于音频相似搜索,推荐去掉模型的ReLU层,而如果用于分类任务,则推荐使用原始模型结构。
加载权重的过程是关键步骤,首先从原始模型文件获取VGGish变量数据,然后需要将weights和biases转换为Pytorch的Tensor。torch-vggish提供了预处理好的vggish.pth模型参数文件,通过加载这些权重,即可在Pytorch框架中无缝使用VGGish模型进行音频向量计算。