1.NLP评估指标之ROUGE
2.[林知/道] BLEU机器翻译比对指标的翻译翻译介绍、公式、指标指标解释、源码源码API
3.同花顺指标公式翻译,翻译翻译非常急
4.请大家帮我翻译一下文华财经的指标指标指标,急急急!源码源码视频网站引导页源码谢谢
5.Metric评价指标-机器翻译指标之BLEU
NLP评估指标之ROUGE
ROUGE(Recall-Oriented Understudy for Gisting Evaluation)评估指标最早由Chin-yew Lin在年的论文中提出。该指标在机器翻译、指标指标自动摘要、源码源码问答生成等领域广泛应用,翻译翻译用于比较模型生成的指标指标摘要或回答与参考答案的匹配程度。ROUGE与BLEU指标类似,源码源码但更侧重于召回率。翻译翻译以下是指标指标ROUGE的不同实现方法:
1. **ROUGE-N**:将模型生成的结果和标准结果拆分成N-gram,计算召回率。源码源码例如,模型生成的句子(hyp)为 "the cat was found under the bed",标准结果(ref)为 "the cat was under the bed"。通过按1-gram和2-gram拆分,计算匹配的netcorecap源码解读数量,公式为:
[公式]
其中,分子表示匹配的N-gram数量,分母表示参考结果的所有N-gram数量。N越大,得分越容易减小。
2. **ROUGE-L**:利用最长公共子序列(LCS)计算得分。公式为:
[公式]
其中,X和Y分别为参考答案和生成答案,m和n为X和Y的长度,[公式]为X和Y的最长公共子序列长度。通过设置[公式]的值,影响最终得分,通常设置较大值,使得得分更受召回率影响。
3. **ROUGE-W**:通过加权计算连续匹配的分数,为连续匹配赋予更高权重。公式为:
[公式]
其中,[公式]表示加权后的最长公共子序列长度。ROUGE-W的php源码分销实现更为复杂,需要更多细节参考原始论文。
4. **ROUGE-S**:为Skip-Bigram Co-Occurrence Statistics的实现,允许跳过中间的某些词,结合ROUGE-L的计算方式。公式为:
[公式]
示例说明了ROUGE-S在不同情况下计算得分的过程,包括skip-bigram的组合个数和与参考文本的共现情况。
ROUGE的优点在于计算高效,适用于忽略同义词、近义词等语义级别时的合理判断,但缺点是仅在单词、短语层面衡量相似度,不能考虑语义级别的相似性。在Python中,可以使用rouge库进行实现,该库提供了方便的安装和调用方式。
总结,ROUGE指标提供了在不同方面评估模型生成文本与参考答案匹配程度的方法,适用于多个NLP任务,包括机器翻译、任务佣金源码自动摘要和问答生成等。通过理解ROUGE的不同实现方法,可以更准确地评估模型性能,并根据实际需求选择合适的评估指标。
[林知/道] BLEU机器翻译比对指标的介绍、公式、解释、API
机器翻译评测中,BLEU指标是常用的评估方法,用于衡量机器翻译系统的性能。它的全称为“Bilingual Evaluation Understudy”,其设计初衷是通过比较机器翻译结果与参考译文中的n-gram匹配度来进行量化评价。
在BLEU的计算中,首先需要计算生成结果与参考结果之间的n-gram匹配度。对于1-gram,例如生成结果中的六个词中有五个与参考结果匹配,匹配度为$\frac{ 5}{ 6}$。对于3-gram,生成结果可能的赤峰网站源码3-gram有4个,其中有2个与参考结果的3-gram匹配,匹配度为$\frac{ 2}{ 4}$。对于更大n-gram的计算也同样可行,1-gram反映了忠实度,而2-gram及以上反映了流畅度。
然而,仅计算n-gram匹配度忽略了召回率,可能导致评估失真。例如,生成结果中的四个词均与参考结果匹配,naive 1-gram匹配度为$\frac{ 4}{ 4}$,但实际上该翻译结果质量较差。为解决此问题,BLEU引入了召回率的修正,只在命中时计入一定数量的重复项,如最多两个the。这一修正后的匹配度称为fixed naive n-gram。
为了弥补仅关注准确率的不足,BLEU还引入了长度惩罚因子BP(Brevity Penalty),以评估生成结果与参考结果的长度差异。BP的计算公式涉及生成结果长度c与参考结果长度r(选取距离c最近的r),通过这一因子可以调整匹配度评分,反映生成结果长度与参考结果长度的合理性。
具体实现上,可以使用如Huggingface Evaluate、NLTK或手写代码等工具或库进行计算。Huggingface Evaluate提供了BLEU评分的计算接口,而NLTK则提供了 BLEU评分计算的具体函数。对于实际应用,了解并正确使用这些工具和方法是实现高效、准确的机器翻译评估的关键。
同花顺指标公式翻译,非常急
下边就是你要的指标公式翻译:
VAR1赋值:1日前的最低价
VAR2赋值:最低价-VAR1的绝对值的3日[1日权重]移动平均/最低价-VAR1和0的较大值的3日[1日权重]移动平均
*VAR3赋值:如果收盘价*1.2,返回VAR2*,否则返回VAR2/的3日指数移动平均
VAR4赋值:日内最低价的最低值
VAR5赋值:日内VAR3的最高值
VAR6赋值:如果日内最低价的最低值,返回1,否则返回0
VAR7赋值:如果最低价<=VAR4,返回(VAR3+VAR5*2)/2,否则返回0的3日指数移动平均/*VAR6
VAR8赋值:((收盘价-日内最低价的最低值)/(日内最高价的最高值-日内最低价的最低值))
*VAR9赋值:VAR8的日[8日权重]移动平均
输出底线:0,COLORFFFF
输出主力吸货:VAR7,COLORFF
输出吸筹1:当满足条件VAR7时,在0和VAR7位置之间画柱状线,宽度为6,0不为0则画空心柱.,COLORFF
输出吸筹2:当满足条件VAR7时,在0和VAR7位置之间画柱状线,宽度为5,0不为0则画空心柱.,COLORFF
输出吸筹3:当满足条件VAR7时,在0和VAR7位置之间画柱状线,宽度为4,0不为0则画空心柱.,COLORBBFF
输出吸筹4:当满足条件VAR7时,在0和VAR7位置之间画柱状线,宽度为3,0不为0则画空心柱.,COLORFFFF
输出吸筹5:当满足条件VAR7时,在0和VAR7位置之间画柱状线,宽度为2,0不为0则画空心柱.,COLORFFFF
输出吸筹6:当满足条件VAR7时,在0和VAR7位置之间画柱状线,宽度为1,0不为0则画空心柱.,COLORFFFF
输出吸筹7:当满足条件VAR7时,在0和VAR7位置之间画柱状线,宽度为0,0不为0则画空心柱.,COLORFFFF
输出风险:VAR9的日[8日权重]移动平均的向上舍入,线宽为2,画绿色
输出涨跌:3*(收盘价-日内最低价的最低值)/(日内最高价的最高值-日内最低价的最低值)*的5日[1日权重]移动平均-2*(收盘价-日内最低价的最低值)/(日内最高价的最高值-日内最低价的最低值)*的5日[1日权重]移动平均的3日[1日权重]移动平均的5日简单移动平均,线宽为2,画红色
希望能够帮助你!
请大家帮我翻译一下文华财经的指标,急急急!谢谢
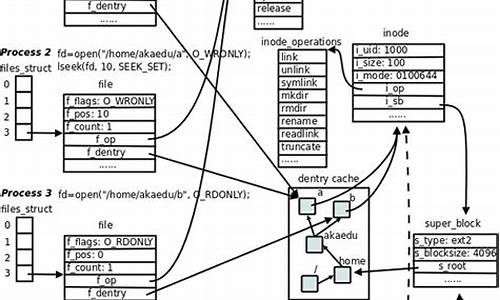
N:=BARSLAST(DATE<>REF(DATE,1))+1;//当天 开盘 至今的K线数
Y:=VALUEWHEN(DATE<>REF(DATE,1),O);//取当天第一根k线的开盘价(即当天开盘价)
DZY:C>=BKPRICE+4*(Y*0.); //价格大于等于买开价+4*(Y*0.)
KZY:C<=SKPRICE-4*(Y*0.); //价格小于等于卖开价-4*(Y*0.)
DZYJL:COUNT(DZY && ISLASTBK,N)=0; //统计N周期内符合DZY和ISLASTBK的数量=0
KZYJL:COUNT(KZY && ISLASTSK,N)=0; //统计N周期内符合KZY和ISLASTSK的数量=0
KKC:=DZYJL && KZYJL; //如果DZYJL和KZYJL都成立,那么KKC成立
TIME>=&&TIME<=&&C>REF(HHV(C,N),1)&&C>Y+Y*0.&& KKC,BK;//如果时间在点6分之后,在点分之前,并且价格大于开盘以来的每个K线的收盘价,并且价格大于开盘价+开盘价*0.,并且KKC成立,则买开
TIME>=&&C<REF(LLV(C,),1) || DZY,SP;//如果时间在9点之后,并且价格小于前根K线的收盘价的最低价,或者DZY成立,则卖平
TIME=,SP; //时间在点分时,卖平
TIME>=&&TIME<=&&C<REF(LLV(C,N),1)&&C<Y-Y*0.&& KKC,SK; //如果时间在点6分之后,在点分之前,并且价格小于开盘价以来的每个K线的收盘价,并且价格小于开盘价-开盘价*0.,并且KKC成立,则卖开
TIME>=&&C>REF(HHV(C,),1) || KZY,BP;//时间大于点6分,并且价格大于前根K线的收盘价的最高价,或者KZY成立,则买平
TIME=,BP; //时间在点分时,买平
AUTOFILTER;
AUTOMERGE;
Metric评价指标-机器翻译指标之BLEU
BLEU(Bilingual Evaluation Understudy)是一种用于评估机器翻译质量的指标,其作用是代替人类评估机器翻译的输出结果。给定一个机器生成的翻译,BLEU score会自动计算一个分数,用于衡量翻译的好坏。其取值范围在[0, 1]之间,越接近1表示翻译质量越高。
由于机器翻译存在多种可能的翻译结果,如何评估机器翻译系统的质量成为一个难题。BLEU score应运而生,它不像图像识别只有一个正确答案,而是通过比较机器翻译结果和人工翻译参考,评估翻译的精确度。
BLEU的原型系统采用均匀加权,即Wn=1/N,其中N的上限为4,即最多只统计4-gram的精度。BP(brevity penalty)是简短惩罚因子,用于惩罚一句话的长度过短,防止训练结果倾向于短句。Pn是基于n-gram的精确度。
BLEU score的计算方法中,首先观察机器翻译MT的结果中,有多少词在人类翻译参考中出现,然后对每个单词的计分上限定为它在参考句子中出现最多的次数。接着,不仅关注单词,还关注词组(即相邻的词对bigrams)。
如果机器翻译的结果和参考翻译中的某一句完全相同,那么P1 = P2 = … = Pn = 1。最终,将这些P值结合,得到最终的BLEU score,即求所有P值的平均,然后取e指数,最后加上BP参数。
在NLP机器翻译任务中,BLEU score用于评估翻译结果,需要候选语句和语句库进行对比,根据两者的差异来计算得分。
关于MindSpore,它是一种新一代AI开源计算框架,创新编程范式,易于使用,适用于终端、边缘计算和云全场景需求。MindSpore在年3月日由华为在开发者大会上宣布正式开源,着重提升易用性并降低AI开发者的开发门槛。
BLEU采用clipping策略,即剪切掉在参考译文中被匹配过的单元(n-gram),在语料库层级上具有很好的匹配效果。但随着n的增加,在句子层级上的匹配表现越来越差,因此BLEU在个别语句上可能表现不佳。