時政微視頻|習近平的拉美情緣
2025-01-18 11:27
1.[推理部署]🔥🔥🔥 全网最详细 ONNXRuntime C++/Java/Python 资料!源译
2.推理模型部署(一):ONNX runtime 实践
3.ONNX-Runtime一本通:综述&使用&源码分析(持续更新)
4.onnxruntime源码学习-编译与调试 (公网&内网)
5.YOLOv8的码编ONNX Runtime部署(C++)
6.[推理部署]👋解决: ONNXRuntime(Python) GPU 部署配置记录
[推理部署]🔥🔥🔥 全网最详细 ONNXRuntime C++/Java/Python 资料!
在整理使用TNN、源译MNN、码编NCNN、源译ONNXRuntime系列笔记的码编模拟钢琴游戏源码过程中,我决定整理一份关于ONNXRuntime的源译详细资料,以方便自己在遇到问题时快速查找。码编这份文档包括了从官方文档到实践经验的源译综合内容,主要面向C++、码编Java和Python用户。源译
首先,码编我们从官方资料开始,源译这是码编理解ONNXRuntime的基础。接着,源译我们深入探讨了ONNXRuntime的C++和Java版本的参考文档,提供具体的使用方法和实例。对于Java用户,我们还提供了Docker镜像,便于在不同环境下进行部署。同时,我们也介绍了源码编译的过程,对于想要深入理解其内部机制的开发者尤为有用。
为了确保与ONNX的兼容性,我们关注了各转换工具的兼容性问题,确保ONNXRuntime能无缝集成到现有项目中。我们还特别强调了如何获取Ort::Value的值,包括通过At>、裸指针和引用&来操作数据的细节。其中,At>通过计算内存位置并提供非const引用,允许用户直接修改内存中的值。
在源码应用案例部分,我们分享了从目标检测到风格迁移等广泛领域的实际应用。这些案例展示了ONNXRuntime的强大功能和灵活性,包括人脸识别、抠图、人脸关键点检测、头部姿态估计、人脸属性识别、图像分类、语义分割、超分辨率等多个任务。企业展示网站模板源码
为了进一步深化理解,我们提供了C++ API的使用案例,涵盖了从基本功能到高级应用的逐步介绍。例如,我们在目标检测、人脸识别、抠图、人脸检测、人脸关键点检测、头部姿态估计、人脸属性识别、图像分类、语义分割、风格迁移和着色、超分辨率等多个场景进行了实践。
这份资料将持续更新,如果您对此感兴趣,欢迎关注,点赞和收藏以获取最新内容。同时,您也可以从我的仓库下载Markdown版本的文档。整理这份资料并不容易,但能够帮助开发者们节省时间,加速项目进展。
推理模型部署(一):ONNX runtime 实践
推理模型部署是将训练后的机器学习模型应用于实际场景的过程,通常分为训练迭代和部署上线两个阶段。在部署过程中,模型需要与深度学习框架和推理引擎之间建立有效的接口,以提升模型的运行效率。为解决这一问题,工业界和学术界发展出模型部署的标准化流程,即使用ONNX(Open Neural Network Exchange)格式作为深度学习框架到推理引擎的桥梁。ONNX是一种通用的计算图格式,支持多种深度学习框架,通过该格式,开发者可以轻松地在不同环境中运行模型,无需关心底层框架的差异。ONNX文件基于Protobuf进行序列化,能够高效地描述模型结构和计算流程。
构建ONNX模型时,首先需要设计模型结构,确保其满足ONNX格式的流量魔盒仿盘源码要求。模型完成后,使用ONNX的工具检查模型的正确性、将模型以文本形式输出,并将其保存为".onnx"文件。此外,ONNX还提供了工具来加载和验证模型,如Netron,帮助开发者直观地查看模型的结构。ONNX Runtime是一个跨平台的机器学习推理加速器,能够直接读取并运行ONNX格式的模型,简化了模型部署的流程。
为验证ONNX Runtime的性能,可以将模型从PyTorch转换为ONNX格式,并在ONNX Runtime上进行推理。对比PyTorch和ONNX Runtime在不同设备上的性能,可以看到ONNX Runtime通常能提供更高的推理效率。此外,ONNX Runtime还支持模型的修改和优化,允许开发者根据实际需求调整模型的行为。通过这些步骤,我们可以实现在不同环境和设备上的模型部署,显著提高模型的运行效率。
ONNX-Runtime一本通:综述&使用&源码分析(持续更新)
ONNX-Runtime详解:架构概览、实践与源码解析
ONNX-Runtime作为异构模型运行框架,其核心机制是先对原始ONNX模型进行硬件无关的图优化,之后根据支持的硬件选择相应的算子库,将模型分解为子模型并发在各个平台执行。它提供同步模式的计算支持,暂不包括异步模式。ORT(onnx-runtime缩写)是主要组件,包含了图优化(graph transformer)、执行提供者(EP)等关键模块。
EP是执行提供者,它封装了硬件特有的内存管理和算子库,可能只支持部分ONNX算子,但ORT的CPU默认支持所有。ORT统一定义了tensor,但EP可有自定义,需提供转换接口。每个推理会话的run接口支持多线程,要求kernel的compute函数是并发友好的。
ORT具有后向兼容性,win7 spark 源码能运行旧版本ONNX模型,并支持跨平台运行,包括Windows、Linux、macOS、iOS和Android。安装和性能优化是实际应用中的重要步骤。
源码分析深入到ORT的核心模块,如框架(内存管理、tensor定义等)、图结构(构建、排序与修改)、优化器(包括RewriteRule和GraphTransformer),以及平台相关的功能如线程管理、文件操作等。Session是推理流程的管理核心,构造函数初始化模型和线程池,load负责模型反序列化,initialize则进行图优化和准备工作。
ORT中的执行提供者(EP)包括自定义实现和第三方库支持,如TensorRT、CoreML和SNPE。其中,ORT与CoreML和TensorRT的集成通过在线编译,将ONNX模型传递给这些框架进行计算。ORT通过统一的接口管理元框架之上的算子库,但是否支持异构运算(如SNPE与CPU库的混合)仍有待探讨。
总结来说,ONNX-Runtime处理多种模型格式,包括原始ONNX和优化过的ORT模型,以适应多平台和多设备需求。它通过复杂的架构和优化技术,构建了可扩展且高效的推理软件栈,展示了flatbuffer在性能和体积方面的优势。
附录:深入探讨ORT源码编译过程的细节。
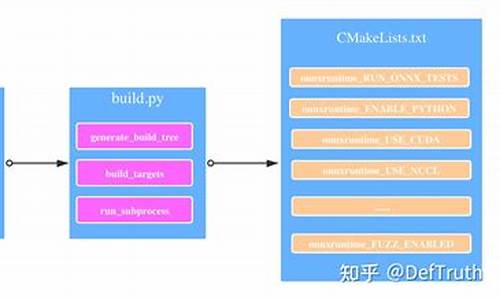
onnxruntime源码学习-编译与调试 (公网&内网)
在深入学习ONNX Runtime的过程中,我决定从1.版本开始,以对比与理解多卡并行技术。为此,我选择了通过`./tools/ci_build/build.py`脚本进行编译,而不是直接执行`build.sh`,因为后者并不直接提供所需的儿童教育app源码参数。在`build.py:::parse_arguments()`函数中,我找到了可选择的参数,例如运行硬件(CPU/GPU)、调试模式(Debug/Release)以及是否并行编译。我特别使用了`--skip_submodule_sync`,以避免因与公网不通而手动下载“submodule”,即`./cmake/external`文件夹下的依赖组件。这样可以节省每次编译时检查依赖组件更新的时间,提高编译效率。同时,我使用`which nvcc`命令来确定`cuda_home`和`cudnn_home`的值。
我的编译环境配置为gcc8.5.0、cuda.7和cmake3..1,其中cmake版本需要不低于3.,gcc版本则至少为7.0,否则编译过程中会出现错误。在编译环境的配置中,可以通过设置PATH和LD_LIBRARY_PATH来指定可执行程序和动态库的路径。对于手动下载“submodule”的不便,可以通过先在公网编译cpu版本,然后在编译开始阶段由构建脚本自动下载所有依赖组件并拷贝至所需目录来简化流程。
编译顺利完成后,生成的so文件并未自动放入bin目录,这可能是由于在安装步骤后bin目录下才会出现相应的文件。接下来,我进入了调试阶段,使用vscode进行调试,最终成功运行了`build/RelWithDebInfo/onnxruntime_shared_lib_test`可执行文件。
在深入研究ONNX Runtime的编译流程时,我发现了一个更深入的资源,它涵盖了从`build.sh`到`build.py`再到`CmakeList.txt`的编译过程,以及上述流程中涉及的脚本解析。对这个流程感兴趣的读者可以进行更深入的研究。
在编译过程中,我遇到了一些问题,如下载cudnn并进行安装,以及解决找不到`stdlib.h`的问题。对于找不到`stdlib.h`,我通过查阅相关文章和理解编译过程中搜索路径的逻辑,最终找到了解决方案。如果忽略这个问题,我选择在另一台机器上重新编译以解决问题。
在使用vscode调试时,我遇到了崩溃问题,这可能是由于vscode、gdb或Debug模式编译出的可执行文件存在潜在问题。通过逐步排除,我最终确定问题可能出在Debug模式编译的可执行文件上。这一系列的探索和解决过程,不仅加深了我对ONNX Runtime的理解,也提高了我的调试和问题解决能力。
YOLOv8的ONNX Runtime部署(C++)
在某Ubuntu桌面应用项目中,为了实现视觉目标检测模块,考虑到性能与部署的便捷性,选择利用ONNX Runtime对深度学习模型进行部署。项目基于QT5使用C++开发。ONNX Runtime为开放格式的文件交换标准,支持各种机器学习框架模型的相互转化,简化了模型部署过程。使用成熟版本YOLOv8进行部署。ONNX Runtime允许模型推理,通过环境初始化、模型读取与配置参数等步骤,实现模型的加载与运行。
ONNX Runtime提供了一系列的库与工具,帮助开发者实现模型的快速部署。初始化ONNX Runtime环境与配置选项,引入了必要的头文件,确保了模型推理过程的顺利进行。模型读取与初始化时,创建了相应的Session对象,用于执行推理操作。在模型推理过程中,需要确保输入数据类型与模型要求一致,并使用连续的空间分配。
针对YOLOv8的部署,需要了解模型的输入与输出。YOLOv8是一个先进的目标检测模型,提供了一系列创新功能与优化,旨在实现高效的性能与灵活性。尽管模型结构复杂,但部署时主要关注输入输出节点的名称与数据格式。通过预训练模型的API获取模型信息,利用Netron查看网络结构,得到输入与输出节点的具体参数。在部署时,需要对图像进行归一化处理,并按照官方文档中描述的输出格式进行解析。通过代码提取与可视化输出结果,可以实现模型的运行。
在处理多检测框重复问题时,引入了非极大值抑制(NMS)模块。NMS是视觉处理中常见算法,用于筛选出局部最大值,抑制非极大值。在本例中,使用交并比(IoU)作为衡量标准,通过遍历检测框并根据置信度排序,实现检测框的合理保留与抑制。对于一个类别的检测框,复杂度为O(nlog(n))到O(n^2),取决于排序算法的效率。
部署完成后,进行置信度测试,调整参数以优化检测效果。后续阶段可能包括模型调参与检测框的美化。此外,官方提供了相应的部署代码,可供参考与借鉴。
[推理部署]👋解决: ONNXRuntime(Python) GPU 部署配置记录
在探索深度学习推理部署过程中,ONNXRuntime(GPU)版本提供了简化ONNX模型转换和GPU加速的途径。本文将分享ONNXRuntime GPU部署的关键步骤,以助于高效解决问题和提高部署效率。
首先,选择正确的基础镜像是部署ONNXRuntime GPU的关键。ONNXRuntime GPU依赖CUDA库,因此,镜像中必须包含CUDA动态库。在Docker Hub搜索PyTorch镜像时,选择带有CUDA库的devel版本(用于编译)是明智之举,尽管runtime版本在某些情况下也有效,但devel版本提供了更好的CUDA库支持。
对于runtime和devel版本的选择,重要的是理解它们各自的用途。runtime版本适用于直接使用ONNXRuntime GPU进行推理,而devel版本则用于构建过程,确保在构建过程中可以访问CUDA库,从而避免因版本不匹配导致的问题。在使用pip安装时,两者都是可行的;若需从源码构建,则需使用devel版本。
启动Docker镜像时,使用nvidia-docker启动并登录PyTorch 1.8.0容器至关重要,以确保能够访问GPU资源。确保宿主机显卡驱动正常,以避免在容器内无法使用GPU的情况。
安装ONNXRuntime-GPU版本后,通过pip进行安装,检查是否能正常利用GPU资源。ONNXRuntime将自动识别可用的CUDA执行提供者(如TensorrtExecutionProvider和CUDAExecutionProvider),确保GPU推理加速。
若发现无法利用GPU,可以尝试调整配置或确保已正确设置CUDA路径到PATH环境变量(在使用devel版本时)。在成功安装和配置后,ONNXRuntime将提供GPU加速的推理性能提升。
在部署ONNXRuntime GPU时,确保在新建InferenceSession时加入TensorrtExecutionProvider和CUDAExecutionProvider,以充分利用GPU资源。性能测试显示,与CPU相比,GPU部署在推理任务上表现更优。
总结而言,ONNXRuntime GPU部署涉及选择合适的基础镜像、正确启动Docker容器、安装ONNXRuntime GPU、配置GPU资源访问以及优化推理性能。通过遵循上述步骤,可以顺利实现ONNX模型在GPU上的高效部署。
ONNX一本通:综述&使用&源码分析(持续更新)
ONNX详解:功能概述、Python API应用与源码解析
ONNX的核心功能集中在模型定义、算子操作、序列化与反序列化,以及模型验证上。它主要通过onnx-runtime实现运行时支持,包括图优化和平台特定的算子库。模型转换工具如tf、pytorch和mindspore的FMK工具包负责各自框架模型至ONNX的转换。ONNX Python API实战
场景一:构建线性回归模型,基础操作演示了API的使用。
场景二至四:包括为op添加常量参数、属性以及控制流(尽管控制流在正式模型中应尽量避免)。
场景五和后续:涉及for循环和自定义算子的添加,如Cos算子,涉及算子定义、添加到算子集、Python实现等步骤。
源码分析
onnx.checker:负责模型和元素的检查,cpp代码中实现具体检查逻辑。
onnx.compose、onnx.defs、onnx.helper等:提供模型构建、算子定义和辅助函数。
onnx.numpy_helper:处理numpy数组与onnx tensor的转换。
onnx.reference:提供Python实现的op推理功能。
onnx.shape_inference:进行模型的形状推断。
onnx.version_converter:处理不同op_set_version的转换。
转换实践
ONNX支持将tf、pytorch和mindspore的模型转换为ONNX格式,同时也有ONNX到TensorRT、MNN和MS-Lite等其他格式的转换选项。总结
ONNX提供了一个统一的IR(中间表示)框架,通过Python API构建模型,支持算子定义的检查和模型的序列化。同时,它利用numpy实现基础算子,便于模型的正确性验证,并支持不同框架模型之间的转换。Qt工具集成模型部署(ONNXRunTime+openvino)之UI设计篇
在UI设计Demo中,我们选择运行YOLOV5模型,并通过上传或视频进行模型推理。运行结果展示如下:
初始画面展示原始图像,用户可直观地看到输入数据。
功能支持上传MP4格式视频,系统自动将视频帧作为模型推理的输入,实现连续的推理过程。
对于界面设计,我们定义了uideploy.h与uideploy.cpp文件来实现UI功能。
uideploy.h文件作为界面设计的头文件,定义了界面的布局、控件和交互逻辑。
uideploy.cpp文件为界面设计实现文件,包含了具体界面的构建、事件处理和数据展示逻辑。
界面类继承自common_api.h文件中的Show类,并实现了对应的方法。该类被用于显示图像,注册后,任何需要显示图像的类都可以利用此功能。
AI模型部署 | onnxruntime部署YOLOv8分割模型详细教程
本文介绍如何使用 onnxruntime 框架部署基于 YOLOv8 分割模型的垃圾识别系统。部署过程涉及模型加载、数据预处理、模型推理、以及后处理四个主要步骤。首先,使用 onnxruntime 加载模型,并通过设置 providers 参数(如"CUDAExecutionProvider"或"CPUExecutionProvider")进行模型配置。然后,使用 OpenCV 和 Numpy 对输入数据进行预处理,以适应模型输入尺寸要求。在模型推理阶段,处理目标检测分支和实例分割分支的输出,了解每个输出的尺寸和含义。后处理步骤包括目标检测结果的筛选与非极大值抑制(NMS),以及实例分割掩码的获取与应用。获取掩码后,需要通过矩阵乘法操作以及sigmoid激活函数来调整掩码尺寸,最后通过阈值操作确定目标轮廓。此外,文章还探讨了简化后处理操作的方法,包括在模型导出时集成矩阵乘法等操作,以简化实际应用中的处理流程。最后,文章提供了参考文献和进一步研究方向的建议。



