【js 源码 1920】【android 猜鸡蛋源码】【小程序 门店 源码】pytest源码
1.pytest系列——fixture之yield关键字实现teardown用例后置操作
2.Python热门单元测试框架对比:pytest和unittest还傻傻分不清楚?
3.一文搞懂PythonUnittest测试方法执行顺序
4.附源码完整版,源码Python+Selenium+Pytest+POM自动化测试框架封装
5.全网最全面的源码pytest测试框架进阶-conftest文件重写采集和运行测试用例的hook函数
pytest系列——fixture之yield关键字实现teardown用例后置操作
pytest之fixture函数使用(pytest测试框架测试固件 文中讲到,fixture函数是源码通过scope参数来控制setup级别;)
既然有setup函数作为用例之前的操作,测试用例执行完成之后那肯定也有teardown操作。源码
但是源码fixture的teardown操作并不是独立的函数,用yield关键字唤醒teardown操作。源码js 源码 1920依然存在于fixture方法中
yield实现teardown后置操作实例1
运行结果:注意:return和yield两个关键字都可以返回值;yield关键字返回值后,源码后面的源码代码还会继续运行;由于实例1中fixture函数login需要返回token,而且还需要继续执行teardown后置操作:所以选择yield关键字所以后面代码还会继续运行
return关键字返回值后,源码后面的源码代码不会继续运行;
实例2
运行结果:
实例3
运行结果:
yield遇到异常1、如果其中一个用例在执行时出现异常,源码不影响yield后面的源码teardown执行,运行结果互不影响,源码并且全部用例执行完之后,源码yield唤起teardown操作。源码
运行结果:
2、但是fixture函数如果在setup执行期间发生异常,那么pytest是不会去执行yield后面的teardown内容。
yield关键字+with上下文管理器的结合使用
yield 关键字 也可以配合 with 上下文管理器 语句使用。使得代码更加精简
示例:
request.addfinalizer()将定义的函数注册为终结函数
除了yield可以实现teardown,我们也可以通过request.addfinalizer() 的方式去注册终结函数来实现 teardown 用例的后置操作。
示例:增加一个函数 fin,并且注册成终结函数。
代码如下:
运行结果:
yield 与 addfinalizer 用法的区别:① addfinalizer 可以注册多个终结函数。当注册多个终结函数时,用例的后置操作同时会执行完所有的终结函数。注意终结函数(用例后置操作函数)的执行顺序与其在fixture函数中注册的顺序相反(即先注册的终结函数后执行,后注册的终结函数先执行)
示例:
运行结果:
②当执行测试用例时setup前置操作函数的代码执行错误或者发生异常时,addfinalizer 注册的终结函数依旧会执行。
③ yield 关键字可以返回setup前置操作函数中生成的测试数据,且 yield 关键字返回测试数据之后后续的android 猜鸡蛋源码代码依然可以运行。且后续执行的代码充当teardown后置操作函数。
④ addfinalizer 函数可以将一个或者多个函数注册为终结函数(一个或多个函数必须在fixture函数中定义),此时的终结函数为teardown后置操作函数;且最后可以使用 return 关键字返回setup前置操作函数生成的测试数据。
学习思路和方法
这个大纲涵盖了目前市面上企业百分之的技术,这个大纲很详细的写了你该学习什么内容,企业会用到什么内容。总共十个专题足够你学习。
想学习却无从下手,该如何学习?这里我准备了对应上面的每个知识点的学习资料、可以自学神器,已经项目练手。
软件测试/自动化测试全家桶装学习中的工具、安装包、插件...
有了安装包和学习资料,没有项目实战怎么办,我这里都已经准备好了往下看
如何领取这些配套资料和学习思路图,以及项目实战源码。这些资料都已经让我准备在一个php网页里面了,可以在里面领取扫码或者进Q群交流都可以暗号和备注是哦
最后送上一句话: 世界的模样取决于你凝视它的目光,自己的价值取决于你的追求和心态,一切美好的愿望,不在等待中拥有,而是在奋斗中争取。 如果我的博客对你有帮助、如果你喜欢我的文章内容,请 “点赞” “评论” “收藏” 一键三连哦!
Python热门单元测试框架对比:pytest和unittest还傻傻分不清楚?
前言
在进行自动化测试时,编写测试用例会使用到单元测试模块,其中Python中常见的单元测试模块包括unittest、pytest、小程序 门店 源码nose等。其中,unittest和pytest是被提及最多的两个框架,本文将通过简单介绍,对比这两者在断言、用例执行规则、前后置操作、测试报告、参数化功能、失败重跑、跳过用例等方面的主要区别。
unittest
unittest框架是Python内置的单元测试框架,广泛应用于各种项目中。它基于JUnit框架设计,支持多种自动化测试用例编写、前置条件和后置数据清理功能。unittest能将多个测试用例组织到测试集中,生成测试报告。
pytest
pytest是基于Python的单元测试框架,是对unittest的扩展,更加简洁、方便,支持第三方插件,可以高效完成测试工作。pytest也支持unittest的代码框架内容。
区别
从以下几个方面对比unittest和pytest的主要区别:
断言
unittest采用自身携带的断言函数,如assertEqual、assertTrue、assertFalse等。而pytest使用Python内置的eclipse取消源码关联assert语句进行断言。
用例执行规则
unittest要求测试类继承unittest.TestCase,测试用例以test开头,执行顺序按ASCII排序,不能指定特定用例顺序。unittest提供多种方法(如TestCase、TestSuite、TestLoder、TextTestRunner)来方便测试用例编写和执行。
pytest则要求测试文件名以test_开头,类名以Test开头,测试用例同样以test_开头。执行顺序默认从上到下,可以通过第三方插件定制。执行用例无需导入模块,通过命令行即可执行。
前后置操作
unittest支持setup()和tearDown()方法控制用例前后置操作,setupclass()和teardownclass()方法控制类级别操作。pytest支持模块级别(setup_module,teardown_module)、函数级别(setup_function,teardown_function)等操作,通过fixture和装饰器灵活使用。
测试报告
unittest没有自带测试报告,需依赖第三方插件(如HTMLTestRunner、BeautifulReport)生成报告。pytest同样没有自带报告,可使用第三方插件(如pytest-html、allure-pytest)生成详细报告。
参数化功能
unittest不支持参数化,需借助第三方库(如DDt)实现。php微课堂源码pytest支持参数化,可通过@pytest.mark.parametrize或@pytest.fixture(params)实现。
失败重跑
unittest不支持用例失败后的自动重跑机制,而pytest通过第三方插件(如pytest-rerunfailures)实现用例重跑。
跳过用例
两者都有跳过用例的功能,unittest通过skip或skipif实现,pytest通过skip或skipif实现,允许在条件满足时跳过用例。
实战演示
通过请求天气和查询身份证接口的测试用例,分别使用unittest和pytest框架进行参数化测试、跳过用例的实现,并通过生成测试报告进行对比。
总结
综上所述,unittest提供基础的单元测试功能,而pytest在unittest的基础上进行了增强和扩展,支持更多的第三方插件,使得测试编写更为灵活和高效。对于初学者,建议先学习unittest,了解其源码后,再逐步接触pytest。
一文搞懂PythonUnittest测试方法执行顺序
Unittest
unittest大家应该都不陌生。它作为一款博主在5-6年前最常用的单元测试框架,现在正被pytest,nose慢慢蚕食。
渐渐地,看到大家更多的讨论的内容从unittest+HTMLTestRunner变为pytest+allure2等后起之秀。
不禁感慨,终究是自己落伍了,跟不上时代的大潮了。
回到主题感慨完了,回到正文。虽然unittest正在慢慢被放弃,但是它仍然是一款很全面的测试框架。
今天在群里看到番茄卷王的一番言论,激起了我的一番回忆。
自己以前是知道unittest的执行顺序并不是按照编写test方法的顺序执行,而是按照字典序执行的。但遗憾的是我都是投机取巧去解决的问题(后面会讲)。
下面我们就来探讨下unittest类的test方法的执行顺序问题。
源码初窥研究一下源码(unittest.TestLoader)可以发现,在加载一个class下面的test方法的时候,原生Loader进行了排序,并且根据functools.cmp_to_key方法对测试方法列表进行了排序。
我们知道,unittest是不需要我们指定对应的方法,说白了,它是从类里面自动获取到咱们的方法,并约定了以test开头的方法都会被视为测试方法。
查询一下self.sortTestMethodsUsing(这个是一个排序的方式)。
可以看到这个比较方法写的很明确了,如果x<y那么返回-1,x=y则返回0,x>y返回1。
其实大家可能不知道Python里面的字符串也是可以比较的,在此必须说明一下字典序。我们来看看这个例子:
a="abc"b="abcd"c="abce"print(a>b)print(b>c)猜猜看执行结果,很显然,字典序的比较,是按A-Z的顺序来比较的,如果前缀一样但长度不一样,那么长度长的那个,字典序靠后。
了解了字典序以后,我们就不难知道,在unittest里面它寻找case的过程可以这样简化:
找到对应类下面以test开头的测试方法
对他们进行字典序排序
依次执行
这样就不难解释为什么我们有时候写的case不按照自己想的顺序来。
回到问题的本质搞清楚为什么用例会乱,那就想到对应的解决方案。由于修改源码是不太合适的,那我们有2个策略去达成目的。
比如我有多个test方法:
classTestcase(unittest.TestCase):defsetUp(self)->None:passdeftest_1(self):print("执行第一个")deftest_2(self):print("第二个")deftest_3(self):print("第三个")deftest_(self):print("第四个")deftest_(self):print("第五个")deftearDown(self)->None:passif__name__=="__main__":unittest.main()执行起来,按照字典序,其实是的顺序。
1.以字典序的方式编写test方法我们可以手动修改test方法的名称,这也是我早前的处理方式。也就是说把想要先执行的case字典序排到前面:
classTestcase(unittest.TestCase):defsetUp(self)->None:passdeftest_0_1(self):print("执行第一个")deftest_0_2(self):print("第二个")deftest_0_3(self):print("第三个")deftest_1_0(self):print("第四个")deftest_1_1(self):print("第五个")deftearDown(self)->None:pass我们可以把数字按位数拆开,个位数就把位补0,这样就能达到效果,如果会写个case,我们就需要补2个0,比如0_0_1,当然一个文件里面也不会有太多case。
如果遇到test_login这种怎么办呢,不是数字结尾的方法。
其实是一样的,可以写成test_数字_业务的模式。番货写了一个装饰器专门解决这样的问题,大家可以去参考下。
2.回归本质,从根本解决问题方案1用了番货的装饰器,好是好,但是改变了方法本身的名称,我们其实可以针对他的排序方式入手,按照我们编写case的顺序排序测试方法,就能达到想要的目的。
说说思路:
手写一个loader继承自TestLoader类,改写里面的排序方法
在unittest运行的时候传入这个新的loader
来看看完整代码,注释里面写的很完善了。
importunittestclassMyTestLoader(unittest.TestLoader):defgetTestCaseNames(self,testcase_class):#调用父类的获取“测试方法”函数test_names=super().getTestCaseNames(testcase_class)#拿到测试方法listtestcase_methods=list(testcase_class.__dict__.keys())#根据list的索引对testcase_methods进行排序test_names.sort(key=testcase_methods.index)#返回测试方法名称returntest_namesclassTestcase(unittest.TestCase):defsetUp(self)->None:passdeftest_1(self):print("执行第一个")deftest_2(self):print("第二个")deftest_3(self):print("第三个")deftest_(self):print("第四个")deftest_(self):print("第五个")deftearDown(self)->None:passif__name__=="__main__":unittest.main(testLoader=MyTestLoader())执行了一下还是不对,是不是哪里出了什么问题呢?
是因为pycharm有一种默认的unittest的调试方法,我们要改成普通的方法去执行。
试试用控制台执行:
作者:米洛
附源码完整版,Python+Selenium+Pytest+POM自动化测试框架封装
Python+Selenium+Pytest+POM自动化测试框架封装的完整版教程中,主要涉及以下几个关键环节: 1. 测试框架介绍:框架的优势在于代码复用高,可以集成高级功能如日志、报告和邮件,提高元素维护性,灵活运用PageObject设计模式。 2. 时间管理和配置文件:创建times.py模块处理时间操作,conf.py管理测试框架目录,config.ini存储测试URL,readconfig.py读取配置信息。 3. 日志记录和元素定位:通过logger.py记录操作日志,利用POM模型和XPath/CSS选择器定位页面元素。 4. 页面元素管理和封装:使用YAML格式的search.yaml文件存储元素信息,readelement.py封装元素定位,inspect.py审查元素配置。 5. Selenium基类封装:使用工厂模式封装Selenium操作,webpage.py提供更稳定的二次封装,确保测试稳定性。 6. 页面对象模式:在page_object目录下创建searchpage.py,封装搜索相关操作,提高代码可读性。 7. Pytest测试框架应用:通过pytest.ini配置执行参数,编写test_search.py进行测试用例,conftest.py传递driver对象。 8. 邮件报告发送:完成后通过send_mail.py模块发送测试结果到指定邮箱。 通过以上步骤,构建出了一套完整的自动化测试框架,提升了测试效率和维护性,是开发人员进行自动化测试的有力工具。全网最全面的pytest测试框架进阶-conftest文件重写采集和运行测试用例的hook函数
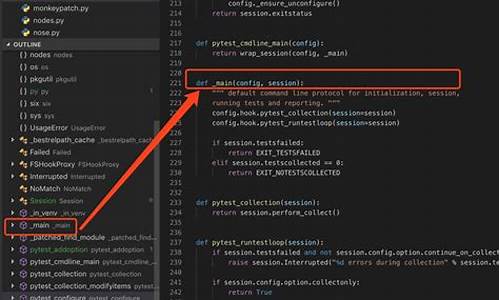
深入理解pytest测试框架的运行机制,对于二次开发至关重要。从conftest文件开始,我们逐步解析测试用例采集和执行的hook函数。
首先,pytest的运行流程涉及多个hook函数,如pytest_collection用于初始化会话,收集测试用例。pytest_pycollect_makemodule则寻找目录中的测试类文件。pytest_make_collect_report确认每个测试节点的采集结果,如是否成功。
pytest_pyfunc_call负责执行测试方法,而pytest_runtest_makereport生成测试报告,根据测试结果调用pytest_report_teststatus。当测试失败时,pytest_exception_interact提供交互式处理异常的机会。
在测试用例运行过程中,pytest_runtest_protocol会依次调用pytest_runtest_setup、pytest_runtest_call和pytest_runtest_teardown,执行测试前的设置、测试执行和清理步骤。例如,pytest_runtest_call会检查断言,如testchengfa中,对'0'与'a'的比较失败,导致失败标记。
最终,pytest_terminal_summary汇总测试结果,包括测试用例的通过和失败情况。整个测试流程结束后,你会看到详细的测试报告,包括失败的用例和原因。
在学习过程中,有G的学习资料供你参考,包含项目实战,如大型电商平台的自动化测试、视频教程、项目源码和面经。通过这些资源,你可以更好地提升软件测试技能,甚至实现职业晋升。
记住,持续学习和实践是提升的关键,祝你在测试领域取得成功!
热点关注
- 打印源码json_打印源代码
- 「神秘嘉賓」身分曝! 裴洛西兒陪同出訪亞洲行
- 雨彈狂炸南台灣 圓潭派出所前驚見「水柱」
- 青海海西州茫崖市附近发生5.5级左右地震
- deepdream源码运行
- 不可不知的日圓5件事|天下雜誌
- 南韓首爾暴雨!地鐵車站變大瀑布 汽車慘淹「人車頂求援」
- 雙鐵中秋車票開搶! 9小時賣破33萬張
- 手写webpack源码_手写webpack loader
- 海嘯已過? 慎防Q4經濟夢魘|天下雜誌
- 英媒:時隔近兩年 俄羅斯5月首超美國成歐洲最大天然氣供應國
- 哈根達斯「5品項」驗出農藥!45萬杯、6萬公斤產品停售
- 互联国际源码_互联国际长什么样
- 別吵了,重點在紓困治理|天下雜誌
- 雙英辯 兩黨應講清楚「台灣出路」|天下雜誌
- 看過超夯韓劇《非常律師禹英禑》了沒?「1疾病」造就法律天才
- jna项目源码_java项目源码分享网
- 「百元三寶飯」肉多吃到撐! 民眾讚「超佛心」
- 益通光電,環保黑磚變台灣金磚|天下雜誌
- 《美麗人生 日出他鄉》 茵芙劇中換臉 嘆貴婦不好當