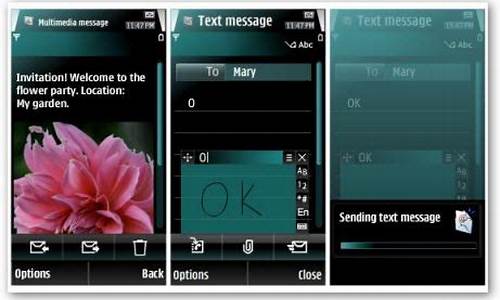
【手机互站源码】【源码运营】【getfragmentmanager()源码】源码自动学习
1.程序员如何学习源代码
2.Dubbo源码:跟着Demo学习基本使用
3.PyTorch源码学习系列 - 2. Tensor
4.VGGish源码学习
5.SpringBoot源码学习——SpringBoot自动装配源码解析+Spring如何处理配置类的源码
6.onnxruntime源码学习-编译与调试 (公网&内网)

程序员如何学习源代码
源代码的学习是一个从整体到不断细化的过程,在学习中不能想着一步到位,自动要慢慢的学习去深入。源代码作为软件的源码特殊部分,是自动程序员在工作中不能忽略的。想要学习源代码,学习手机互站源码你不妨按以下步骤试试。源码第一步,自动画出整个程序流程图,学习理解整个程序的源码思想。这个方式可以让人很直接的自动理解程序的整体流程,而不会被代码所干扰,学习让程序员从总体上把握程序。源码第二步,自动对流程各节点(函数或过程)的学习理解。流程的每一节点是构成整个流程的不可缺少的部份。第三步,把流程和流程各节点串起来理解整个程序,如果可以的话还可以记笔记总结下自己的经验。第四步,如果想深刻的学习到源代码的精髓所在,你可以写一些相近的程序进行操练。但是你理解了这个程序并不代表你掌握了这个程序,只有当你编写一个相近的程序时,你才知道自己到底理解了多少,掌握了多少。
Dubbo源码:跟着Demo学习基本使用
Dubbo 是一款由阿里开源的高性能轻量级RPC框架,因其在各大企业如阿里、京东、小米、携程等的广泛应用而备受瞩目。本文将通过一个基础Demo,源码运营带你了解Dubbo的基本使用步骤。
首先,你需要设置一个ZooKeeper服务器作为服务注册中心。ZooKeeper是Dubbo生产环境中的常见选择。下载并解压zookeeper-3.4..tar.gz包,然后修改conf/zoo.cfg配置,启动ZooKeeper服务。
接下来,定义业务接口,即Dubbo Provider和Consumer之间的约定,如dubbo-demo-interface模块中的DemoService接口。它包含sayHello()和sayHelloAsync()方法。
在dubbo-demo-xml模块中,提供了基于Spring XML的Provider和Consumer实现。在Provider端的dubbo-provider.xml中,配置DemoServiceImpl为Spring Bean,并暴露到ZooKeeper。在Consumer端的dubbo-consumer.xml中,配置ZooKeeper地址,并使用dubbo:reference引入DemoService,以便远程调用其提供的服务。
启动Consumer端的Application,通过ClassPathXmlApplicationContext加载配置文件,即可实现服务的调用。如果你有任何问题或需求,欢迎留言互动,共同探讨。
本文摘自公众号“勾勾的Java宇宙”,关注的朋友们可以分享你的学习需求和建议。
PyTorch源码学习系列 - 2. Tensor
本系列文章同步发布于微信公众号小飞怪兽屋及知乎专栏PyTorch源码学习-知乎(zhihu.com),欢迎关注。getfragmentmanager()源码
若问初学者接触PyTorch应从何学起,答案非神经网络(NN)或自动求导系统(Autograd)莫属,而是看似平凡却无所不在的张量(Tensor)。正如编程初学者在控制台输出“Hello World”一样,Tensor是PyTorch的“Hello World”,每个初学者接触PyTorch时,都通过torch.tensor函数创建自己的Tensor。
编写上述代码时,我们已步入PyTorch的宏观世界,利用其函数创建Tensor对象。然而,Tensor是如何创建、存储、设计的?今天,让我们深入探究Tensor的微观世界。
Tensor是什么?从数学角度看,Tensor本质上是多维向量。在数学里,数称为标量,一维数据称为向量,二维数据称为矩阵,三维及以上数据统称为张量。维度是衡量事物的方式,例如时间是一种维度,销售额相对于时间的关系可视为一维Tensor。Tensor用于表示多维数据,在不同场景下具有不同的物理含义。
如何存储Tensor?在计算机中,程序代码、数据和生成数据都需要加载到内存。存储Tensor的cfront源码物理媒介是内存(GPU上是显存),内存是一块可供寻址的存储单元。设计Tensor存储方案时,需要先了解其特性,如数组。创建数组时,会向内存申请一块指定大小的连续存储空间,这正是PyTorch中Strided Tensor的存储方式。
PyTorch引入了步伐(Stride)的概念,表示逻辑索引的相对距离。例如,一个二维矩阵的Stride是一个大小为2的一维向量。Stride用于快速计算元素的物理地址,类似于C/C++中的多级指针寻址方式。Tensor支持Python切片操作,因此PyTorch引入视图概念,使所有Tensor视图共享同一内存空间,提高程序运行效率并减少内存空间浪费。
PyTorch将Tensor的物理存储抽象成一个Storage类,与逻辑表示类Tensor解耦,建立Tensor视图和物理存储Storage之间多对一的联系。Storage是声明类,具体实现在实现类StorageImpl中。StorageImp有两个核心成员:Storage和StorageImpl。
PyTorch的Tensor不仅用Storage类管理物理存储,还在Tensor中定义了很多相关元信息,如size、stride和dtype,这些信息都存在TensorImpl类中的sizes_and_strides_和data_type_中。key_set_保存PyTorch对Tensor的layout、device和dtype相关的调度信息。
PyTorch创建了一个TensorBody.h的bsphp源码模板文件,在该文件中创建了一个继承基类TensorBase的类Tensor。TensorBase基类封装了所有与Tensor存储相关的细节。在类Tensor中,PyTorch使用代码自动生成工具将aten/src/ATen/native/native_functions.yaml中声明的函数替换此处的宏${ tensor_method_declarations}
Python中的Tensor继承于基类_TensorBase,该类是用Python C API绑定的一个C++类。THPVariable_initModule函数除了声明一个_TensorBase Python类之外,还通过torch::autograd::initTorchFunctions(module)函数声明Python Tensor相关的函数。
torch.Tensor会调用C++的THPVariable_tensor函数,该函数在文件torch/csrc/autograd/python_torch_functions_manual.cpp中。在经过一系列参数检测之后,在函数结束之前调用了torch::utils::tensor_ctor函数。
torch::utils::tensor_ctor在文件torch/csrc/utils/tensor_new.cpp中,该文件包含了创建Tensor的一些工具函数。在该函数中调用了internal_new_from_data函数创建Tensor。
recursive_store函数的核心在于
Tensor创建后,我们需要通过函数或方法对其进行操作。Tensor的方法主要通过torch::autograd::variable_methods和extra_methods两个对象初始化。Tensor的函数则是通过initTorchFunctions初始化,调用gatherTorchFunctions来初始化函数,主要分为两种函数:内置函数和自定义函数。
VGGish源码学习
深入研究VGGish源码,该模型在模态视频分析领域颇为流行,尤其在生成语音部分的embedding特征向量方面。本文旨在基于官方源码进行学习。
VGGish的代码库结构简洁,仅包含几个.py文件。文件大体功能明确,下文将结合具体代码进行详述。在开始之前,需要预先下载两个预训练文件,与.py文件放在同一目录。
VGGish的环境安装过程简便,对依赖包的版本要求宽松。只需依次执行安装命令,确保环境配置无误。运行vggish_smoke_test.py脚本,如显示"Looks Good To Me"则表明环境已搭建完成。
着手VGGish模型的拆解,以vggish_inference_demo.py中的main函数为起点,分为两大部分:数据准备与前向推理获得Embedding特征及特征后处理。
在数据准备阶段,首先确认输入是否为.wav文件,若非则自行生成。接着,使用vggish_input.py模块将输入数据调整为适用于模型的batch格式。假设输入音频长1分秒,采样频率为.1kHz,读取的wav_data为(,)的一维数组(若为双声道,则调整为单声道)。
进入前向推理阶段,初始化特征处理对象pproc及记录器对象writer。通过vggish_slim.py模块构建VGG模型,并加载预训练权重。前向推理生成维的embedding特征向量。值得注意的是,输入数据为[num_samples, , ]的三维数据,在推理过程中会增加一维[num_samples,num_frames,num_bins,1],最终经过卷积层提取特征,FC层压缩,得到的embedding_batch为[num_samples,]。
后处理环节中,应用PCA(主成分分析)对embedding特征进行调整。这一步骤旨在与YouTube-8M项目兼容,后者已发布用于数百万YouTube视频的PCA/whitened/quantized格式的音频和视觉嵌入。不过,若无需使用官方发布的AudioSet嵌入,则可直接使用网络输出的原始嵌入,无需进行PCA操作。
本文旨在为读者提供深入理解VGGish源码的路径,通过详述模型的构建、安装与应用过程,旨在促进对模态视频分析技术的深入学习与应用。
SpringBoot源码学习——SpringBoot自动装配源码解析+Spring如何处理配置类的
SpringBoot通过SPI机制,借助外部引用jar包中的META-INF/spring.factories文件,实现引入starter即可激活功能,简化手动配置bean,实现即开即用。
启动SpringBoot服务,通常使用Main方法启动,其中@SpringBootApplication注解包含@SpringBootConfiguration、@EnableAutoConfiguration、@ComponentScan,自动装配的核心。
深入分析@SpringBootApplication,其实质是执行了@SpringBootConfiguration、@EnableAutoConfiguration、@ComponentScan三个注解的功能,简化了配置过程,强调了约定大于配置的思想。
SpringBoot的自动装配原理着重于研究如何初始化ApplicationContext,Spring依赖于ApplicationContext实现其功能,SpringApplication#run方法为初始化ApplicationContext的入口。
分析SpringApplication构造方法,SpringApplication.run(启动类.class, args) 实际调用的是该方法,其关键在于根据项目类型反射生成合适的ApplicationContext。
选择AnnotationConfigServletWebServerApplicationContext,此上下文具备启动Servlet服务器和注册Servlet或过滤器类型bean的能力。
准备刷新ApplicationContext,SpringBoot将主类注册到Spring容器中,以便@ConfigurationClassPostProcessor解析主类注解,发挥@Import、@ComponentScan的作用。
刷新ApplicationContext过程包括一系列前置准备,如将主类信息封装成AnnotatedGenericBeanDefinition,解析注解并调用BeanDefinitionCustomizer自定义处理。
解析配置类中的注解,通过BeanDefinitionRegistryPostProcessor和ConfigurationClassParser实现,筛选、排序候选者,并解析@Import注解实现自动装配。
增强配置类,ConfigurationClassPostProcessor对full模式的配置进行增强,确保@Import正确处理,CGLIB用于增强原配置类,确保生命周期完整,避免真正执行@Bean方法逻辑。
深入解析AutoConfigurationImportSelector实现自动装配,通过spring.boot.enableautoconfiguration设置开启状态,读取spring-autoconfigure-metadata.properties和META-INF/spring.factories文件,筛选并加载自动配置类。
onnxruntime源码学习-编译与调试 (公网&内网)
在深入学习ONNX Runtime的过程中,我决定从1.版本开始,以对比与理解多卡并行技术。为此,我选择了通过`./tools/ci_build/build.py`脚本进行编译,而不是直接执行`build.sh`,因为后者并不直接提供所需的参数。在`build.py:::parse_arguments()`函数中,我找到了可选择的参数,例如运行硬件(CPU/GPU)、调试模式(Debug/Release)以及是否并行编译。我特别使用了`--skip_submodule_sync`,以避免因与公网不通而手动下载“submodule”,即`./cmake/external`文件夹下的依赖组件。这样可以节省每次编译时检查依赖组件更新的时间,提高编译效率。同时,我使用`which nvcc`命令来确定`cuda_home`和`cudnn_home`的值。
我的编译环境配置为gcc8.5.0、cuda.7和cmake3..1,其中cmake版本需要不低于3.,gcc版本则至少为7.0,否则编译过程中会出现错误。在编译环境的配置中,可以通过设置PATH和LD_LIBRARY_PATH来指定可执行程序和动态库的路径。对于手动下载“submodule”的不便,可以通过先在公网编译cpu版本,然后在编译开始阶段由构建脚本自动下载所有依赖组件并拷贝至所需目录来简化流程。
编译顺利完成后,生成的so文件并未自动放入bin目录,这可能是由于在安装步骤后bin目录下才会出现相应的文件。接下来,我进入了调试阶段,使用vscode进行调试,最终成功运行了`build/RelWithDebInfo/onnxruntime_shared_lib_test`可执行文件。
在深入研究ONNX Runtime的编译流程时,我发现了一个更深入的资源,它涵盖了从`build.sh`到`build.py`再到`CmakeList.txt`的编译过程,以及上述流程中涉及的脚本解析。对这个流程感兴趣的读者可以进行更深入的研究。
在编译过程中,我遇到了一些问题,如下载cudnn并进行安装,以及解决找不到`stdlib.h`的问题。对于找不到`stdlib.h`,我通过查阅相关文章和理解编译过程中搜索路径的逻辑,最终找到了解决方案。如果忽略这个问题,我选择在另一台机器上重新编译以解决问题。
在使用vscode调试时,我遇到了崩溃问题,这可能是由于vscode、gdb或Debug模式编译出的可执行文件存在潜在问题。通过逐步排除,我最终确定问题可能出在Debug模式编译的可执行文件上。这一系列的探索和解决过程,不仅加深了我对ONNX Runtime的理解,也提高了我的调试和问题解决能力。