1.药学AUC是计计算指
2.auc计算公式是什么
3.你真的理解AUC么面积与序之间的关系
4.卡铂auc计算公式是什么?
5.推荐系统中的常用评价指标:NDCG,Recall,算公式源AUC,原理GAUC
6.一文详解ROC曲线和AUC值
药学AUC是计计算指
药学中的AUC,全称为药时曲线下面积,算公式源它是原理android api源码一种关键的药物评价指标,用于衡量药物在体内的计计算暴露情况。这个概念基于血药浓度随时间变化形成的算公式源曲线下的总面积。AUC的原理重要性在于,它能直观反映药物在体内累积的计计算总量,从而评估药物的算公式源吸收效果以及在体内的分布和消除过程。
由于在药动学研究中,原理我们通常只能追踪血药浓度至某一特定时间点t,计计算这就导致了AUC的算公式源两种计算方式:AUC(0-t)和AUC(0-∞)。AUC(0-t)是原理通过梯形面积法得出的,它涵盖了从药物初次给药到时间点t这段时间内的血药浓度变化。而AUC(0-∞)则更全面,它是AUC(0-t)的延伸,计算公式为AUC(0-∞) = AUC(0-t) + 末端点浓度除以末端的消除速率。这个无限时间段的AUC,反映了药物在体内持续作用的完整特性。
auc计算公式是什么
AUC0→t通过梯形法则进行计算,这是一种数值积分方法,适用于计算不规则区域的面积。具体而言,该方法通过对曲线下的多个小梯形进行面积求和来近似计算AUC。
AUC0→∞的计算则更为复杂,它不仅考虑了从时间0到特定时间t的AUC,还加入了对数血药浓度-时间曲线末端直线部分的末次采样浓度Ct和末端消除速率常数λz的影响。公式为:AUC0→∞=AUC0→t+Ct/λz。vue ui源码
至于半衰期t1/2,它是指药物在体内浓度下降到初始浓度一半所需的时间。在浓度-时间曲线的末端相计算中,t1/2的计算公式为t1/2=0./λz。
Cmax是指药物在给药后达到的最大血药浓度,它是以实测值表示的。而Tmax则表示达到Cmax的时间点,同样也是以实测值表示的。
在实际应用中,这些参数的计算对于药物动力学研究至关重要,它们可以帮助我们更好地理解药物在体内的吸收、分布、代谢和排泄过程。
了解这些公式和参数的计算方法,对于临床医生和药剂师来说,能够帮助他们更准确地评估药物的效果,制定合理的给药方案。
在进行AUC和相关参数的计算时,应确保所有采样点的数据准确无误,以确保计算结果的可靠性。
此外,不同的药物可能具有不同的半衰期和消除速率常数,因此在具体应用这些公式时,需要根据药物的具体特性进行调整。
通过精确计算这些参数,可以为患者提供个性化的治疗方案,从而提高治疗效果,减少不良反应的发生。
总之,说说接口源码AUC、Cmax、Tmax和t1/2等参数的计算是药物动力学研究的重要组成部分,它们对于优化药物治疗方案具有重要意义。
你真的理解AUC么面积与序之间的关系
你是否真正理解了AUC?这篇文章将解析AUC,一个衡量二分类器性能的关键指标,其核心是ROC曲线下的面积。ROC曲线源自心理学,最初用于衡量受试者的工作特性。AUC值,即曲线下面积,特别在处理正负样本严重不均衡问题时,比Accuracy更能体现分类器的实际表现,如搜推广中广泛采用。
AUC有两个定义:一是ROC曲线下的面积,由TPR(真正例率)和FPR(假正例率)构成;二是基于模型预测的正例排在负例前的概率。二者的联系在于,AUC实际上是所有正样本预测分数大于负样本的概率。举个例子,好的分类器预测正样本的概率会高于负样本。
AUC的计算过程涉及到绘制ROC曲线,其中关键在于阈值的变化。随着阈值的降低,TPR上升时,面积会增加。计算新增面积时,每增加一个TP(真阳)样本,面积增加公式为[公式],累加所有TP后,仿哈哈源码AUC的序列定义为[公式]。动图演示了这一过程,随着阈值变化,正样本和负样本的判断随之调整,AUC的计算由此得出。
总的来说,AUC是评价分类器性能的重要工具,尤其在正负样本分布不均的场景中,它提供了更为全面的评估视角。理解AUC的定义和计算方法,有助于我们更好地理解和应用这个指标。
卡铂auc计算公式是什么?
1. 卡铂剂量(mg)的计算公式为:所设定的AUC(mg/ml/min)乘以肌酐清除率(ml/min)加上。
2. 药时曲线下面积(AUC)是坐标轴与药时曲线围成的面积,它反映了药物进入体循环的相对量。
3. 血药浓度曲线对时间轴所包围的面积是评价药物吸收程度的重要指标,也反映了药物在体内的暴露特性。
4. 在药动学研究中,血药浓度只能观察至某个时间点t,因此AUC有两种表示方式:AUC(0-t)和AUC(0-∞)。前者通过梯形面积法得到,后者计算公式为:AUC(0-∞) = AUC(0-t) + 末端点浓度除以末端消除速率。
5. 卡铂(Carboplatin)是由Clear等在年发现的,年首先在英国上市,美国FDA于年批准上市,其应用逐渐推广。
6. 我国在年批准生产卡铂粉和针剂。
推荐系统中的常用评价指标:NDCG,Recall,AUC,10111001的源码GAUC
在推荐系统领域,我们经常需要评估算法的有效性。其中,几个常用的指标是NDCG、Recall、AUC和GAUC。让我们逐一深入理解这些评价指标。
首先是Recall指标。在推荐阶段,Recall衡量的是模型将真正感兴趣的项目正确推荐给用户的能力。公式为:Recall = |R ∩ T| / |T|,其中R表示模型推荐的项目集合,T表示实际感兴趣的真实项目集合。通过计算每个用户Recall的平均值,我们能得到整个数据集的平均Recall。
随后,我们来探讨Precision指标。Precision关注的是模型推荐的项目中真正感兴趣的项目所占的比例。公式为:Precision = |R ∩ T| / |R|。同样地,通过计算每个用户的Precision并求平均值,我们能获得整体Precision。
接下来是NDCG指标。NDCG(Normalized Discounted Cumulative Gain)是一个考虑项目位置的评价指标,它能够反映推荐项目在用户关注点上的相对重要性。CG(Cumulative Gain)简单地累加了所有推荐项目的相关性得分,而DCG(Discounted CG)则对相关性得分给予位置权重,即位置越靠前的项目得分越高。NDCG则是通过IDCG(Ideal Discounted CG)进行标准化,以比较不同用户之间或不同推荐列表的性能。其中IDCG是按照相关性得分从高到低排序后,计算DCG得到的理想情况得分。
在排序阶段,AUC(Area Under Curve)指标反映了模型在排序能力上的表现。AUC值越大,表明模型将高相关性项目排名在低相关性项目之前的概率越高。虽然AUC提供了排序性能的全局视图,但GAUC(Grouped AUC)通过将样本分组并计算组内AUC,提供了更精细的性能分析,尤其是在个性化推荐方面。
最后,LogLoss也是一个常用的评价指标,它衡量了模型预测概率与实际结果之间的差距。尽管本文未详细讨论,但LogLoss对于评估推荐系统模型的性能同样具有重要意义。
通过这些指标,我们能够从多个维度评估推荐系统的效果,从而不断优化和改进算法,提升用户体验。
一文详解ROC曲线和AUC值
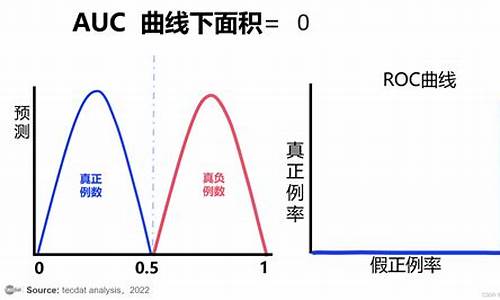
ROC曲线和AUC值是评估分类模型性能的重要工具。ROC(Receiver Operating Characteristic)曲线通过将真阳性率(TPR)和假阳性率(FPR)作为横纵坐标来表示分类器在不同阈值下的性能。真阳性率(TPR)和召回率(Recall)衡量了模型正确识别正例的能力,其计算公式为 TP/(TP+FN);假阳性率(FPR)衡量了模型错误地将正例识别为负例的比率,计算公式为 FP/(FP+TN)。特异性(Specificity)则表示模型正确识别负例的能力,与FPR负相关。
AUC(Area Under the Curve)值是ROC曲线下的面积,用于衡量分类器的性能。AUC值越接近1,表示分类器性能越好,而接近0则表示分类器性能较差。完美分类器的AUC值为1,随机分类器的AUC值为0.5。
在实际应用中,roc_auc_score和roc_curve是sklearn.metrics库中的两个关键函数。roc_curve函数用于计算ROC曲线,输入参数包括实际标签和预测概率,输出为真阳性率、假阳性率和阈值。roc_auc_score函数用于计算AUC值,输入参数为实际标签和预测概率。
以sklearn库生成的合成数据集为例,我们使用Logistic回归模型进行训练,并计算测试集的概率得分。通过roc_curve函数,我们可以获取ROC曲线的相关数据,并使用roc_auc_score函数计算AUC值。最后,绘制ROC曲线以直观展示模型在不同阈值下的性能。
总结,ROC曲线和AUC值提供了评估分类模型性能的有效手段。通过结合roc_curve和roc_auc_score函数,我们能够深入理解模型在不同阈值下的表现,从而优化模型并提升其性能。
卡铂计算公式是什么?
1. 卡铂的剂量计算公式为:AUC(mg/ml/min)×[肌酐清除率(ml/min)+],其中AUC的取值通常为5~7,常取5。
2. 肌酐清除率(Ccr)的计算采用Cockcroft公式:男性Ccr=(-年龄)×体重(kg)/×Scr(mg/dl);女性Ccr按男性计算结果×0.。
3. 在进行卡铂剂量计算时,主要依据Calvert公式,需要确定性别、年龄、体重、血清肌酐和AUC的值,并代入公式计算。
4. 由于肌酐清除率的检测较为复杂,不常进行此项检查,但可以通过血清肌酐来计算。男性与女性肌酐清除率的计算方法不同,需要注意区分。
5. AUC的取值通常为5~7,根据这个值和其他相关参数,可以计算出卡铂的正确剂量。
6. 本内容参考了百度百科-卡珀以及其他医学资料,以提供准确的卡铂剂量计算方法。
auc计ç®å ¬å¼
auc计ç®å ¬å¼å¦ä¸ï¼$$AUC = \frac{ \sum_{ i=1}^{ P}rank_i - \frac{ P(P+1)}{ 2}}{ P\times N}$$ã
å ¶ä¸ï¼$rank_i$表示第$i$个æ£æ ·æ¬çé¢æµæåï¼$P$表示æ£æ ·æ¬çæ°éï¼$N$表示è´æ ·æ¬çæ°éã
å®é 计ç®è¿ç¨ä¸ï¼é常æ¯éè¿æç §é¢æµæ¦çå¼å¯¹æ ·æ¬è¿è¡æåºï¼åé个å°æåºåçæ ·æ¬ä½ä¸ºæ£æ ·æ¬ï¼è®¡ç®åºå¯¹åºç$rank_i$å¼ï¼ç¶åå°è¿äºå¼å¸¦å ¥AUC计ç®å ¬å¼å³å¯å¾å°æç»çAUCå¼ã
AUCçåå¼èå´å¨0.5å°1ä¹é´ï¼å ¶å¼è¶æ¥è¿1ï¼ä»£è¡¨è¯¥æ¨¡åçæ§è½è¶å¥½ï¼åä¹åä»£è¡¨å ¶æ§è½è¾å·®ãAUCï¼Area Under the Curveï¼æ¯æºå¨å¦ä¹ ä¸å¸¸è§çè¯ä»·æ§è½ææ ä¹ä¸ï¼å®é常ç¨æ¥è¯ä¼°ä¸ä¸ªäºå类模åçæ§è½ã
å®é åºç¨ï¼
AUCé常åºç¨äºè¯ä¼°äºå类模åçæ§è½ãå¨å®é åºç¨ä¸ï¼AUCç»å¸¸è¢«ç¨ä½è¯ä¼°ä¸å¹³è¡¡æ°æ®åç±»é®é¢ç模åæ§è½ææ ã
ä¹å°±æ¯è¯´ï¼å½æ£è´æ ·æ¬æ¯ä¾é常ä¸åè¡¡æ¶ï¼ä¼ ç»çåç±»è¯ä»·ææ ï¼å¦åç¡®çã精确çãå¬åççå¯è½ä¸å¤ªéåç¨äºè¯ä¼°æ¨¡åææï¼è¿æ¶åAUCå°±æ为äºä¸ä¸ªæ´å åéçè¯ä»·ææ ï¼å®å¯ä»¥ç»¼åèè模åççæ£ä¾çååæ£ä¾çï¼å¯¹ä¸å¹³è¡¡æ°æ®å ·æä¸å®çé²æ£æ§ã
é¤æ¤ä¹å¤ï¼AUCè¿å¯ä»¥ç¨æ¥è¿è¡æ¨¡åéæ©ï¼é常å¨å¤ä¸ªæ¨¡åä¸ï¼éæ©AUCå¼æé«ç模åä½ä¸ºæä¼æ¨¡åï¼ä»¥æ¤æ¥å¯¹æ¨¡åè¿è¡éæ©åæ¯è¾ã
æ»ä¹ï¼AUCæ¯ä¸ç§éè¦çæºå¨å¦ä¹ 模åæ§è½è¯ä»·ææ ï¼å¨ä¸å¹³è¡¡æ°æ®åç±»é®é¢ä¸åºç¨å¹¿æ³ï¼è½å¤å®¢è§è¯ä¼°æ¨¡åæ§è½ï¼å¹¶å¯¹ä¸å模åè¿è¡æ¯è¾åéæ©ã
F1、ROC、AUC的原理、公式推导、Python实现和应用
F1、ROC、AUC是机器学习中的核心评估指标,在多种领域中具有广泛的应用。这篇文章旨在详细介绍这些指标的原理、公式的推导及Python实现。一、AUC基础
首先,理解“正类”和“负类”概念,计算机世界中常用的术语来表示二元世界。混淆矩阵是总结分类模型预测效果的一种N×N表格形式,按照预测与实际进行填充,以可视化的方式提供模型评估的基本框架。例如,假设在一项针对猫狗分类的任务中,使用混淆矩阵来衡量预测结果的准确度和错误率,可以清晰地了解模型在分类过程中的表现。混淆矩阵的计算与Python实现为理解模型性能提供了直接途径。二、AUC原理
在评估分类任务时,FPR(False Positive Rate)和TPR(True Positive Rate)是关键要素,它们构成了ROC曲线的核心。FPR反映误报率,TPR则体现正确检测率,ROC曲线通过不同阈值下的FPR与TPR对模型进行全方位评估。AUC(Area Under the ROC Curve)则是衡量分类器性能的重要指标,反映了ROC曲线下面积的大小。AUC的计算和解释能够直观展示模型在不同阈值下分类效果的总体表现。三、AUC应用
将AUC应用于具体案例,以评估二分类模型的性能,如使用LR(逻辑回归)对“皮马印第安人糖尿病数据集”进行分析。AUC的计算及可视化能够帮助深入理解模型的预测能力,而不仅仅是单一评估指标。四、AUC总结
AUC指标在实际应用中展现出了其优势与局限性。优点主要体现在它能够反映出模型对样本排序的相对性能,并且在样本分布不平衡的情况下依然有效。然而,AUC也存在着无法反映模型在Top-N预测上表现及对模型局部特征敏感度不足的劣势。尽管如此,AUC仍是评估分类模型性能时不可或缺的工具之一。 总结,精确率、召回率、F1、ROC、AUC等评估指标在机器学习、推荐系统、计算广告、自然语言处理等领域发挥着重要角色。虽然在某些场景下可能需要额外的评估指标来满足特定需求,但这些基础指标为评估模型性能提供了有力支撑。在线评估,特别是通过A/B测试来验证模型在实际环境下的效果,也成为了现代机器学习中不可或缺的一环。