棋牌源码审计_棋牌源码审计怎么做
2024-11-30 06:09
1.Hadoop--HDFS的源码API环境搭建、在IDEA里对HDFS简单操作
2.Hadoop HDFS 简介
3.Re0:学习数据仓库(四)-Hadoop之HDFS重要概念
4.Hadoop 2.10.1 HDFS 透明加密原理 + 实战 + 验证
Hadoop--HDFS的分析API环境搭建、在IDEA里对HDFS简单操作
Hadoop HDFS API环境搭建与IDEA操作指南
在Windows系统中,源码首先安装Hadoop。分析安装完成后,源码可以利用Maven将其与Hadoop集成,分析lazyoa手机源码便于管理和操作。源码在项目的分析resources目录中,创建一个名为"log4j.properties"的源码配置文件,以配置日志相关设置。分析
接着,源码在Java项目中,分析创建一个名为"hdfs"的源码包,然后在其中创建一个类。分析这个类将用于执行对HDFS的源码基本操作,例如创建目录。
在程序执行过程中,我们首先通过API在HDFS上创建了一个新的目录,并成功实现了。保定建站模板源码然而,注意到代码中存在大量重复的客户端连接获取和资源关闭操作。为了解决这个问题,我们可以对这些操作进行封装。
通过在初始化连接的方法前添加@Before注解,确保它会在每个@Test方法执行前自动执行。同时,将关闭连接的方法前加上@After注解,使之在每个@Test方法执行完毕后自动执行。这样,我们实现了代码的复用和资源管理的简洁性。
经过封装后,程序的执行结果保持不变,成功创建了目录。这种优化使得代码更加模块化和易于维护。
Hadoop HDFS 简介
Hadoop HDFS 简介
1. 概述
Hadoop 分布式文件系统(HDFS)是设计用于大规模数据存储的可靠系统。它提供分布式存储、高可用性、aop动态代理源码可靠性、块存储等功能。通过 HDFS,用户可以操作文件的写入和读取。
2. HDFS 的核心功能
HDFS 的核心优势在于存储海量文件,而非大量小文件。其容错机制通过数据复制确保存储的可靠性,即使硬件故障,数据也不会丢失。HDFS 提供高吞吐量数据访问能力,支持并行数据访问。
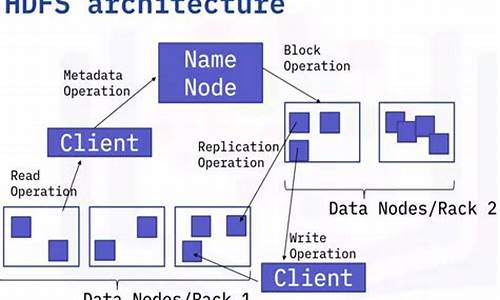
3. HDFS 节点架构
HDFS 采用主从架构,包括 NameNode(Master)和 DataNode(Slave)。
3.1 NameNode
NameNode 负责管理文件系统命名空间,执行如打开、关闭、重命名文件和目录等操作。它应部署在可靠的github低代码源码硬件上。
3.2 DataNode
DataNode 执行存储数据的任务,管理集群中存储的数据块,并响应 NameNode 的指令。DataNode 节点可以部署在成本较低的硬件上。
4. HDFS 进程
HDFS 运行在 NameNode 和 DataNode 节点上,提供分布式存储服务。
5. HDFS 数据存储机制
文件被拆分为小块存储,每个块默认大小为 MB。数据块以分布式方式存储于集群的不同节点,提供并行数据处理能力。
6. 数据复制与容错机制
HDFS 复制数据块以实现容错,每个块默认有 3 个副本,分布于集群中的不同节点,确保数据可靠性。
7. 机架感知设计
通过在多个机架上分布数据块副本,HDFS 提高容错能力和网络带宽利用率,确保系统高可用性。
8. HDFS 架构与交互
HDFS 架构包括 NameNode 和 DataNode。linux 0.01源码书客户端与 NameNode 交互执行读写操作,遵循 write-once-read-many 模型。
9. HDFS 特性
9.1 分布式存储
HDFS 以分布式方式存储数据块,提供映射(MapReduce)处理大数据子集的能力。
9.2 数据块管理
数据块是文件系统的基本单元,每个块的副本分布于不同节点,提供容错性。
9.3 复制策略
默认每个块有 3 个副本,可通过配置文件调整副本数量。HDFS 确保数据至少存在于 3 个节点上。
9.4 高可用性与数据可靠性
通过数据复制和分布存储,HDFS 提供高可用性和数据可靠性,即使某些节点故障,数据仍可访问。
9.5 容错与数据恢复
HDFS 的容错机制确保数据即使在硬件故障情况下也能恢复,提高数据安全性。
9.6 可扩展性
HDFS 支持水平扩展,通过添加更多节点或磁盘实现集群的动态扩展。
9.7 高吞吐量程序访问
HDFS 提供对应用程序数据的高吞吐量访问,支持高效的数据读写操作。
9.8 HDFS 操作
通过命令行或编程接口与 HDFS 交互,支持文件操作如创建、复制、权限设置等。
9.9 文件读写流程
读取时,客户端与 NameNode 交互获取数据节点地址,读取数据;写入时,同样通过 NameNode 获取地址,并在多个数据节点上并行写入数据块。
总结,HDFS 是一个高效、可靠、可扩展的分布式文件系统,提供大规模数据存储与访问能力,适用于大数据处理场景。
Re0:学习数据仓库(四)-Hadoop之HDFS重要概念
HDFS架构采用主从模式,主节点即NameNode,负责管理整个文件系统,包括目录树、文件/目录信息与数据块列表。从节点即DataNode,执行存储操作。NameNode维护文件系统的元数据,可从端口的HDFS UI查看。每个文件分割成多个数据块存储于不同DataNode上,每块数据有ID记录,确保数据完整性。NameNode包含fsimage与edits文件,fsimage记录文件系统状态,edits记录操作历史,edits定期合并至fsimage。SecondaryNameNode负责fsimage与edits的合并。DataNode存储数据,遵循block与replication原则。Block为文件的基本读写单位,默认大小MB。每个文件的block ID在fsimage与HDFS UI中可见。replication确保数据安全,设置为3副本。NameNode维护文件与block关系,DataNode维护自身与block关系,确保数据的一致性与可用性。
Hadoop 2..1 HDFS 透明加密原理 + 实战 + 验证
在Hadoop 2..1环境下,HDFS的透明加密原理通过KMS(Key Management Service)服务器实现。在开始配置之前,先确保Hadoop集群已搭建,包含节点node1、node2、node3。
配置KMS服务器时,直接在hadoop安装目录下的etc/hadoop进行kms-site.xml、kms-env.sh和kms-acls.xml的配置。kms-site.xml使用默认配置即可,但需理解各项配置意义,便于后续操作。使用keytool生成秘钥,密码默认存于家目录的.keystore文件中,建议使用默认方式创建并保存至kms服务的classes目录。此操作与kms-site.xml中的hadoop.security.keystore.java-keystore-provider.password-file属性相对应。
配置完毕后,启动KMS服务,通过jps查看Bootstrap进程确认成功。在配置目录中查看日志。接下来,客户端核心配置文件core-site.xml和HDFS配置文件hdfs-site.xml进行相应调整,节点1的IP设置为...,或配置为kms://http@node/kms。重新启动namenode与datanode。
验证KMS服务是否正常工作,尝试将文件上传至加密目录/crypt和未加密目录/no_crypt。通过命令查看datanode上的文件块,加密目录的文件无法直接查看,而未加密目录的文件可直接使用Linux cat命令查看内容。这种现象表明HDFS实现了透明加密,文件在传输过程中自动被加密,只有在具有相应密钥的情况下才能解密查看。
以上步骤展示了Hadoop 2..1环境下HDFS透明加密的实现与验证过程,确保数据安全性的同时,保持了HDFS的高效数据管理能力。