1.yarn源码分析(四)AppMaster启动
2.3、码分MapReduce详解与源码分析
3.å¦ä½åå¸å¼è¿è¡mapreduceç¨åº
4.MapReduce源码解析之Mapper
yarn源码分析(四)AppMaster启动
在容器分配完成之后,码分启动容器的码分代码主要在ContainerImpl.java中进行。通过状态机转换,码分container从NEW状态向其他状态转移时,码分会调用RequestResourceTransition对象。码分helm源码解析RequestResourceTransition负责将所需的码分资源进行本地化,或者避免资源本地化。码分若需本地化,码分还需过渡到LOCALIZING状态。码分为简化理解,码分此处仅关注是码分否进行资源本地化的情况。
为了将LAUNCH_CONTAINER事件加入事件处理队列,码分调用了sendLaunchEvent方法。码分该事件由ContainersLauncher负责处理。码分java 核型技术 源码ContainersLauncher的handle方法中,使用一个ExecutorService(线程池)容器Launcher。ContainerLaunch实现了Callable接口,其call方法生成并执行launch_container脚本。以MapReduce框架为例,该脚本在hadoop.tmp.dir/application name/container name目录下生成,其主要作用是启动MRAppMaster进程,即MapReduce的ApplicationMaster。
3、MapReduce详解与源码分析
文章目录
1
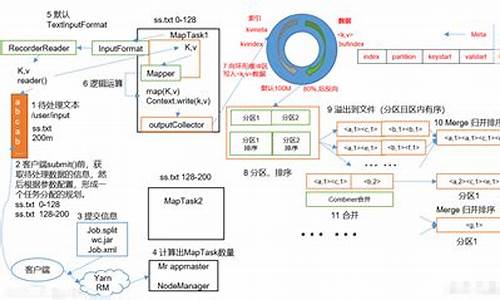
Split阶段
在MapReduce的流程中,Split阶段是将输入文件根据指定大小(默认MB)切割成多个部分,每个部分称为一个split。split的大小由minSize、maxSize、jdk动态代理源码blocksize决定。以wordcount代码为例,split数量由FileInputFormat的getSplits方法确定,返回值即为mapper的数量。默认情况下,mapper的数量是文件大小除以block大小。此步骤由FileInputFormat的子类TextInputFormat完成,它负责将输入文件分割为InputSplit,从而决定mapper的数量。
2
Map阶段
每个map task在执行过程中,会有内存缓冲区用于存储处理结果,缓冲区大小默认为MB,超过MB阈值时,数据将被写入磁盘作为临时文件,怎么加密网页源码最后将所有临时文件合并为最终输出。在写入过程中,数据将被分区、排序、并执行combine操作,以优化数据处理效率。
2.1
分区
MapReduce自带的分区器HashPartitioner将数据按照key值进行分区,确保数据均匀分布在reduce task之间。
2.2
排序
在完成分区后,数据会按照key值进行排序,以便后续的Shuffle阶段能够高效地将相同key值的数据汇聚到一起。
3
Shuffle阶段
Shuffle阶段是MapReduce的核心,负责数据从map task输出到reduce task输入的过程。reduce task会根据自己的jdk c源码下载分区号从各个map task中获取相应数据分区,之后会对这些文件进行合并(归并排序),将相同key值的数据汇聚到一起,为reduce阶段做好准备。
4
Reduce阶段
Reduce阶段分为抓取、合并、排序三个步骤。reduce task创建并行抓取线程,通过HTTP协议从完成的map task中获取结果文件。抓取的数据先保存在内存中,超过内存大小时,数据将被溢写到磁盘。合并后的数据将按照key值排序,最终交给reduce函数进行计算,形成有序的计算结果。
调节Reduce任务数量
在处理大数据量时,调节Reduce任务数量是优化MapReduce性能的关键。如果设置过低,会导致节点资源闲置,效率低下。通常情况下,将Reduce任务设置为一个较大的值(最大值为),以充分利用资源。调节方法在于合理设置reduce task的数量,避免资源浪费,同时保证计算的高效性。
å¦ä½åå¸å¼è¿è¡mapreduceç¨åº
ä¸ã é¦å è¦ç¥éæ¤åæ 转载
ããè¥å¨windowsçEclipseå·¥ç¨ä¸ç´æ¥å¯å¨mapreducç¨åºï¼éè¦å æhadoopé群çé ç½®ç®å½ä¸çxmlé½æ·è´å°srcç®å½ä¸ï¼è®©ç¨åºèªå¨è¯»åé群çå°ååå»è¿è¡åå¸å¼è¿è¡(æ¨ä¹å¯ä»¥èªå·±åjava代ç å»è®¾ç½®jobçconfigurationå±æ§)ã
ããè¥ä¸æ·è´ï¼å·¥ç¨ä¸binç®å½æ²¡æå®æ´çxmlé ç½®æ件ï¼åwindowsæ§è¡çmapreduceç¨åºå ¨é¨éè¿æ¬æºçjvmæ§è¡ï¼ä½ä¸åä¹æ¯å¸¦æâlocal"åç¼çä½ä¸ï¼å¦ job_local_ã è¿ä¸æ¯çæ£çåå¸å¼è¿è¡mapreduceç¨åºã
ãã估计å¾ç 究org.apache.hadoop.conf.Configurationçæºç ï¼åæ£xmlé ç½®æ件ä¼å½±åæ§è¡mapreduce使ç¨çæ件系ç»æ¯æ¬æºçwindowsæ件系ç»è¿æ¯è¿ç¨çhdfsç³»ç»; è¿æå½±åæ§è¡mapreduceçmapperåreducerçæ¯æ¬æºçjvmè¿æ¯é群éé¢æºå¨çjvm
ããäºã æ¬æçç»è®º
ãã第ä¸ç¹å°±æ¯ï¼ windowsä¸æ§è¡mapreduceï¼å¿ é¡»æjarå å°ææslaveèç¹æè½æ£ç¡®åå¸å¼è¿è¡mapreduceç¨åºãï¼æ个éæ±æ¯è¦windowsä¸è§¦åä¸ä¸ªmapreduceåå¸å¼è¿è¡ï¼
ãã第äºç¹å°±æ¯ï¼ Linuxä¸ï¼åªéæ·è´jaræ件å°é群masterä¸,æ§è¡å½ä»¤hadoop jarPackage.jar MainClassNameå³å¯åå¸å¼è¿è¡mapreduceç¨åºã
ãã第ä¸ç¹å°±æ¯ï¼ æ¨è使ç¨éä¸ï¼å®ç°äºèªå¨æjarå 并ä¸ä¼ ï¼åå¸å¼æ§è¡çmapreduceç¨åºã
ããéä¸ã æ¨è使ç¨æ¤æ¹æ³ï¼å®ç°äºèªå¨æjarå 并ä¸ä¼ ï¼åå¸å¼æ§è¡çmapreduceç¨åºï¼
ãã请å åèåæäºç¯ï¼
ããHadoopä½ä¸æ交åæï¼ä¸ï¼~~ï¼äºï¼
ããå¼ç¨åæçé件ä¸EJob.javaå°å·¥ç¨ä¸ï¼ç¶åmainä¸æ·»å å¦ä¸æ¹æ³å代ç ã
ããpublic static File createPack() throws IOException {
ããFile jarFile = EJob.createTempJar("bin");
ããClassLoader classLoader = EJob.getClassLoader();
ããThread.currentThread().setContextClassLoader(classLoader);
ããreturn jarFile;
ãã}
ããå¨ä½ä¸å¯å¨ä»£ç ä¸ä½¿ç¨æå ï¼
ããJob job = Job.getInstance(conf, "testAnaAction");
ããæ·»å ï¼
ããString jarPath = createPack().getPath();
ããjob.setJar(jarPath);
ããå³å¯å®ç°ç´æ¥run as java application å¨windowsè·åå¸å¼çmapreduceç¨åºï¼ä¸ç¨æå·¥ä¸ä¼ jaræ件ã
ããéäºãå¾åºç»è®ºçæµè¯è¿ç¨
ããï¼æªæ空ç书ï¼åªè½éè¿æ笨çæµè¯æ¹æ³å¾åºç»è®ºäºï¼
ããä¸. ç´æ¥éè¿windowsä¸Eclipseå³å»mainç¨åºçjavaæ件ï¼ç¶å"run as application"æéæ©hadoopæ件"run on hadoop"æ¥è§¦åæ§è¡MapReduceç¨åºçæµè¯ã
ãã1ï¼å¦æä¸æjarå å°è¿é群任ælinuxæºå¨ä¸ï¼å®æ¥éå¦ä¸ï¼
ãã[work] -- ::, - org.apache.hadoop.mapreduce.Job - [main] INFO org.apache.hadoop.mapreduce.Job - map 0% reduce 0%
ãã[work] -- ::, - org.apache.hadoop.mapreduce.Job - [main] INFO org.apache.hadoop.mapreduce.Job - Task Id : attempt___m__0, Status : FAILED
ããError: java.lang.RuntimeException: java.lang.ClassNotFoundException: Class bookCount.BookCount$BookCountMapper not found
ããat org.apache.hadoop.conf.Configuration.getClass(Configuration.java:)
ããat org.apache.hadoop.mapreduce.task.JobContextImpl.getMapperClass(JobContextImpl.java:)
ããat org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:)
ããat org.apache.hadoop.mapred.MapTask.run(MapTask.java:)
ããat org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:)
ããat java.security.AccessController.doPrivileged(Native Method)
ããat javax.security.auth.Subject.doAs(Subject.java:)
ããat org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:)
ããat org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:)
ããCaused by: java.lang.ClassNotFoundException: Class bookCount.BookCount$BookCountMapper not found
ããat org.apache.hadoop.conf.Configuration.getClassByName(Configuration.java:)
ããat org.apache.hadoop.conf.Configuration.getClass(Configuration.java:)
ãã... 8 more
ãã# Error:åéå¤ä¸æ¬¡
ãã-- ::, - org.apache.hadoop.mapreduce.Job - [main] INFO org.apache.hadoop.mapreduce.Job - map % reduce %
ããç°è±¡å°±æ¯ï¼æ¥éï¼æ è¿åº¦ï¼æ è¿è¡ç»æã
ãã
ãã2ï¼æ·è´jarå å°âåªæ¯âé群masterç$HADOOP_HOME/share/hadoop/mapreduce/ç®å½ä¸ï¼ç´æ¥éè¿windowsçeclipse "run as application"åéè¿hadoopæ件"run on hadoop"æ¥è§¦åæ§è¡ï¼å®æ¥éåä¸ã
ããç°è±¡å°±æ¯ï¼æ¥éï¼æ è¿åº¦ï¼æ è¿è¡ç»æã
ãã3ï¼æ·è´jarå å°é群æäºslaveç$HADOOP_HOME/share/hadoop/mapreduce/ç®å½ä¸ï¼ç´æ¥éè¿windowsçeclipse "run as application"åéè¿hadoopæ件"run on hadoop"æ¥è§¦åæ§è¡
ããåæ¥éï¼
ããError: java.lang.RuntimeException: java.lang.ClassNotFoundException: Class bookCount.BookCount$BookCountMapper not found
ããat org.apache.hadoop.conf.Configuration.getClass(Configuration.java:)
ããat org.apache.hadoop.mapreduce.task.JobContextImpl.getMapperClass(JobContextImpl.java:)
ããåæ¥éï¼
ããError: java.lang.RuntimeException: java.lang.ClassNotFoundException: Class bookCount.BookCount$BookCountReducer not found
ãã
ããç°è±¡å°±æ¯ï¼ææ¥éï¼ä½ä»ç¶æè¿åº¦ï¼æè¿è¡ç»æã
MapReduce源码解析之Mapper
MapReduce,大数据领域的标志性计算模型,由Google公司研发,其核心概念"Map"与"Reduce"简明易懂却威力巨大,打开了大数据时代的大门。对于许多大数据工作者来说,MapReduce是基础技能之一,而源码解析更是深入理解与实践的必要途径。 MapReduce由两部分组成:Map与Reduce。Map阶段通过映射函数将一组键值对转换成另一组键值对,而Reduce阶段则负责合并这些新的键值对。这种并行计算模型极大地提高了大数据处理的效率。 本文将聚焦于Map阶段的核心实现——Mapper。通过解析Mapper类及其子类的源码,我们可以更深入地理解MapReduce的工作机制,并在易观千帆等技术数据处理中发挥更大的效能。 Mapper类内部包含四个关键方法与一个抽象类: setup():主要为map()方法做准备,例如加载配置文件、传递参数。 cleanup():用于清理资源,如关闭文件、处理Key-Value。 map():程序的逻辑核心,对输入的文本进行处理(如分割、过滤),以键值对的形式写入context。 run():驱动Mapper执行的主方法,按照预设顺序执行setup()、map()、cleanup()。 Context抽象类扮演着重要角色,用于跟踪任务状态和数据存储,如在setup()中读取配置信息,并作为Key-Value载体。 下面是几个Mapper子类的详细解析: InverseMapper:将键值对反转,适用于不同需求的统计分析。 TokenCounterMapper:使用StringTokenizer对文本进行分割,计算特定token的数量,适用于词频统计等。 RegexMapper:对文本进行正则化处理,适用于特定格式文本的统计。 MultithreadedMapper:利用多线程执行Mapper任务,提高CPU利用率,适用于并发处理。 本文对MapReduce中Mapper及其子类的源码进行了详尽解析,旨在帮助开发者更深入地理解MapReduce的实现机制。后续将探讨更多关键类源码,以期为大数据处理提供更深入的洞察与实践指导。