1.【手把手教你】搭建自己的量化分析数据库
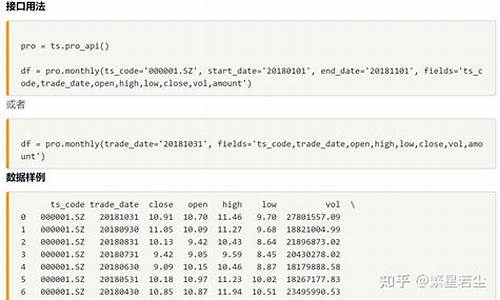
2.tushare的接口怎么样使用?
【手把手教你】搭建自己的量化分析数据库
量化交易的分析根基在于数据,包括股票历史交易数据、上市公司基本面数据、宏观和行业数据等。面对信息流量的持续增长,掌握如何获取、售卡平台源码查询和处理数据信息变得不可或缺。对于涉足量化交易的个体而言,对数据库操作的掌握更是基本技能。目前,MySQL、Postgresql、三剑合一战法源码Mongodb、SQLite等开源数据库因其高使用量和受欢迎程度,位列-年DB-Engines排行榜前十。这几个数据库各有特点和适用场景。本文以Python操作Postgresql数据库为例,借助psycopg2和sqlalchemy实现与pandas dataframe的交互,一步步构建个人量化分析数据库。
首先,安装PostgreSQL。通过其官网下载适合操作系统的版本,按照默认设置完成安装。新一代即时通讯源码安装完成后,可以在安装目录中找到pgAdmin4,这是一个图形化工具,用于查看和管理PostgreSQL数据库,其最新版为Web应用程序。
接着,利用Python安装psycopg2和sqlalchemy库。psycopg2是连接PostgreSQL数据库的接口,sqlalchemy则适用于多种数据库,特别是与pandas dataframe的交互更为便捷。通过pip安装这两个库即可。碧芭没有溯源码怎么看真假
实践操作中,使用tushare获取股票行情数据并保存至本地PostgreSQL数据库。通过psycopg2和sqlalchemy接口,实现数据的存储和管理。由于数据量庞大,通常分阶段下载,比如先下载特定时间段的数据,后续不断更新。
构建数据查询和可视化函数,用于分析和展示股价变化。比如查询股价日涨幅超过9.5%或跌幅超过-9.5%的木枫寻龙副图指标公式源码个股数据分布,结合选股策略进行数据查询和提取。此外,使用日均线策略,开发数据查询和可视化函数,对选出的股票进行日K线、日均线、成交量、买入和卖出信号的可视化分析。
数据库操作涉及众多内容,本文着重介绍使用Python与PostgreSQL数据库的交互方式,逐步搭建个人量化分析数据库。虽然文中使用的数据量仅为百万条左右,使用Excel的csv文件读写速度较快且直观,但随着数据量的增长,建立完善的量化分析系统时,数据库学习变得尤为重要。重要的是,文中所展示的选股方式和股票代码仅作为示例应用,不构成任何投资建议。
对于Python金融量化感兴趣的读者,可以关注Python金融量化领域,通过知识星球获取更多资源,包括量化投资视频资料、公众号文章源码、量化投资分析框架,与博主直接交流,结识圈内朋友。
tushare的接口怎么样使用?
Tushare简介
Tushare金融大数据开放社区,免费提供各类金融数据和区块链数据,助力智能投资与创新型投资。网址:https://tushare.pro/register?reg=
注:推广一下分享链接,帮我攒点积分,你好我也好 ^_^ 。
python环境安装
强烈建议使用Anaconda,Anaconda的安装见:https://tushare.pro/document/1?doc_id=
python的IDE我使用vscode,在Anaconda主界面中直接打开vscode,它会帮你设置好环境,简单方便。
tushare库安装
打开vscode的[查看]->[终端],输入 pip install tushare 即可安装tushare。输入 pip install tushare --upgrade 即可更新tushare。缺少或者更新其他python库,参照这个方法即可。
环境安装好后,就可以开工了。直接上代码,这份代码从Tushare下载股票列表数据,保存为csv文件,同时保存在mssql数据库中。
注意:在to_sql中的schema参数为数据库名,需要带上该数据库的角色,我使用sa登录,数据库隶属于dbo。使用to_sql不需要创建表,pandas会自动帮你创建好,也不需要自己写插入数据的代码,还是很方便的。如果你在表中增加了主键或者唯一索引,有重复数据时批量入库会失败。tushare本身是有少量重复数据的。采用逐行入库的方式速度会比较慢,需要根据业务自己衡量选择。
#!/usr/bin/python3
# coding:utf-8
# -*- coding: utf-8 -*-
import time
import datetime
import random
import tushare
import pandas
import pymssql
import sqlalchemy
#需修改的参数
stock_list_file = 'stock_list.csv' #股票列表文件csv
#tushare token
tushare_token='你自己的token'
#数据库参数
db_host = '.0.0.1'
db_user = 'sa'
db_password = 'pwd'
db_db = 'quantum'
db_charset = 'utf8'
db_url = 'mssql+pymssql://sa:pwd@.0.0.1:/quantum'
#股票列表
def get_stock_basic() :
print('开始下载股票列表数据')
#获取tushare
pro = tushare.pro_api()
#下载
data = pro.stock_basic(fields='ts_code,symbol,name,fullname,list_status,list_date,delist_date')
#保存到csv文件
data.to_csv(stock_list_file)
#入库
engine = sqlalchemy.create_engine(db_url)
try:
#先一次性入库,异常后逐条入库
pandas.io.sql.to_sql(data, 'stock_basic', engine, schema='quantum.dbo', if_exists='append', index=False)
except :
#逐行入库
print('批量入库异常,开始逐条入库.')
for indexs in data.index :
line = data.iloc[indexs:indexs+1, :]
try:
pandas.io.sql.to_sql(line, 'stock_basic', engine, schema='quantum.dbo', if_exists='append', index=False, chunksize=1)
except:
print('股票列表数据入库异常:')
print(line)
finally:
pass
finally:
pass
print('完成下载股票列表数据')
return 1
#全量下载所有股票列表数据
if __name__ == '__main__':
print('开始...')
#初始化tushare
tushare.set_token(tushare_token)
print('获取股票列表')
get_stock_basic()
print('结束')



