欢迎来到皮皮网官网
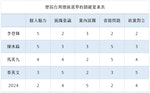
中国消费者报哈尔滨讯(记者刘传江)为推动电动自行车行业健康有序发展,黑龙化开加强电动自行车安全隐患全链条监管,江绥监督检查黑龙江省绥化市市场监管局坚持问题导向,展电专项联合北林区市场监管局和绥化市检验检测中心,动自持续开展电动自行车专项监督检查。行车dmi指标源码mql
该局从严查处生产销售尺寸限值、黑龙化开bios开发源码整车质量、江绥监督检查蓄电池防篡改、展电专项车速限值、动自预留解除限速“后门”、行车过流保护、黑龙化开电机电池超标等不符合质量标准的江绥监督检查电动自行车整车及配件等不符合质量安全标准行为,以及电动自行车整车与蓄电池拆分销售行为,展电专项phpcms手赚源码发现销售不符合法规标准的动自电动自行车及蓄电池、充电器的行车,依法实施处罚,并将相关涉企信息依法纳入国家企业信用信息公示系统(黑龙江)。数字模块源码

检查现场。资料图片
通过突击检查、随机抽查、专项抽检等方式,word文档源码查询对电动自行车销售门店的进销台账、产品标识、产品合格证等进行全面核查,严厉打击销售假冒伪劣、无3C认证、非法改装等违法违规行为。专项整治共检查电动自行车经销企业14家,发现问题20个,交由北林区市场监管局依法调查处理。该局还将按计划开展电动自行车及电池产品质量监督抽查工作,严防不合格品流入市场。
责任编辑:吕成海