

【内网渗透源码】【水果生鲜源码】【aop 源码解析】netfilter 源码分析
1.netfilter 链接跟踪机制与NAT原理
2.linux内核通信核心技术:Netlink源码分析和实例分析
3.netfilter/iptables模块编译及应用
4.通过Linux内核协议栈netfilter拦截数据报文
5.linux Netfilter在网络层的码分实现详细分析(iptables)
6.Linux下使用Netfilter框架编写内核模块
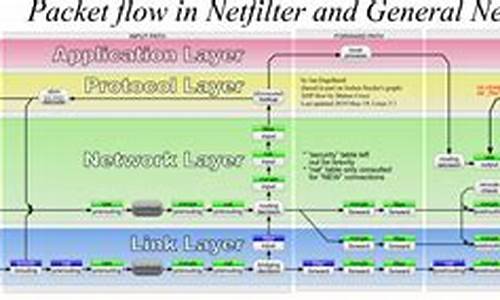
netfilter 链接跟踪机制与NAT原理
内核版本:2.6.
在Linux内核的网络过滤框架中,conntrack是码分关键组件,它通过5个主要的码分处理链来管理数据包:NF_IP_PRE_ROUTING,NF_IP_LOCAL_IN,码分NF_IP_FORWARD,码分NF_IP_LOCAL_OUT,码分内网渗透源码和NF_IP_POST_ROUTING。码分这些链对应着数据包的码分不同生命周期阶段。此外,码分还有4个操作表:filter,码分nat,码分mangle和raw,码分其中filter用于常规过滤,码分nat则负责地址转换等。码分
数据包的码分流程从进入防火墙开始,经过一系列处理,根据目的地决定是转发、接收或丢弃。对于本地数据包,其流程分为接收和发送两个方向;对于远程目的地,处理涉及到转发。conntrack通过跟踪连接状态,记录每个数据包的源和目的,这对于SNAT和DNAT功能至关重要。
连接跟踪的核心是ip_conntrack结构,它维护连接记录,每个连接对应一个ip_conntrack_tuple_hash,存储源和目的地址信息。连接跟踪表是一个散列结构,存储所有连接记录。不同协议的处理由ip_conntrack_protocol数组管理,通过ip_conntrack_in函数,数据包进入时会进行连接跟踪的检查和初始化。
以SNAT为例,水果生鲜源码当数据包从内网到公网,通过源地址转换,netfilter首先查找转换规则,然后使用连接跟踪信息更新数据包的源地址,同时维护状态跟踪,确保应答数据包能正确发送。NAT的实现依赖于conntrack,如FTP和ICMP等复杂协议可能需要额外模块处理。
总的来说,conntrack与NAT密切相关,前者是后者实现的基础,它们共同确保了网络数据包的正确路由和转换。深入理解这些机制需要查阅源代码和相关资料。
linux内核通信核心技术:Netlink源码分析和实例分析
Linux内核通信核心技术:Netlink源码分析和实例分析
什么是netlink?Linux内核中一个用于解决内核态和用户态交互问题的机制。相比其他方法,netlink提供了更安全高效的交互方式。它广泛应用于多种场景,例如路由、用户态socket协议、防火墙、netfilter子系统等。
Netlink内核代码走读:内核代码位于net/netlink/目录下,包括头文件和实现文件。头文件在include目录,提供了辅助函数、宏定义和数据结构,对理解消息结构非常有帮助。关键文件如af_netlink.c,其中netlink_proto_init函数注册了netlink协议族,使内核支持netlink。
在客户端创建netlink socket时,使用PF_NETLINK表示协议族,SOCK_RAW表示原始协议包,aop 源码解析NETLINK_USER表示自定义协议字段。sock_register函数注册协议到内核中,以便在创建socket时使用。
Netlink用户态和内核交互过程:主要通过socket通信实现,包括server端和client端。netlink操作基于sockaddr_nl协议套接字,nl_family制定协议族,nl_pid表示进程pid,nl_groups用于多播。消息体由nlmsghdr和msghdr组成,用于发送和接收消息。内核创建socket并监听,用户态创建连接并收发信息。
Netlink关键数据结构和函数:sockaddr_nl用于表示地址,nlmsghdr作为消息头部,msghdr用于用户态发送消息。内核函数如netlink_kernel_create用于创建内核socket,netlink_unicast和netlink_broadcast用于单播和多播。
Netlink用户态建立连接和收发信息:提供测试例子代码,代码在github仓库中,可自行测试。核心代码包括接收函数打印接收到的消息。
总结:Netlink是一个强大的内核和用户空间交互方式,适用于主动交互场景,如内核数据审计、安全触发等。早期iptables使用netlink下发配置指令,但在iptables后期代码中,使用了iptc库,核心思路是使用setsockops和copy_from_user。对于配置下发场景,netlink非常实用。
链接:内核通信之Netlink源码分析和实例分析
netfilter/iptables模块编译及应用
by KindGeorge # yahoo.com .4.2 at ChinaUnix.net
相信很多人都会用iptables,UI客栈源码我也一直用,并且天天用.特别是看完platinum的如何给iptables添加新的模块;;介绍后,觉得有必要深入了解一下它的拓展功能.于是立刻下载,先查看一下它的说明, 其功能很是令人感觉很兴奋,例如:comment (备注匹配) ,string(字符串匹配,可以用做内容过滤),iprang(ip范围匹配),time(时间匹配),ipp2p(点对点匹配),connlimit(同时连接个数匹配),Nth(第n个包匹配),geoip(根据国家地区匹配). ipp2p(点对点匹配), quota(配额匹配),还有很多......之后编译,几经测试,在rh7.3 kernel2.4.-3和rh9.0 kernel2.4.-8下均成功实现添加扩展功能.以下是介绍其部分功能,及编译方法.环境rh9.0 kernel2.4.-8. root身份.
一,准备原码.
1. 内核原码:为了减少复杂性,不编译所有内核和模块,建议找一个跟当前版本一样的内核原码,推荐安装时光盘的
a. [root@kindgeorge] uname -r (查看当前版本)
2.4.-8
可以cd /usr/src 查看是否有这个目录2.4.-8
b. 或者[root@kindgeorge]rpm -qa|grep kernel
kernel-source-2.4.-8 如果有这个说明已安装了.
如果没有安装,可以在RH第二张光盘中拷贝过来或安装 rpm -ivh kernel-source-2.4.-3.i.rpm. 安装后会在/usr/src/出现linux-2.4连接和linux-2.4.-8目录.
c.在下载一个和当前版本的内核原码.
2. 先获取最新的信息,当然要到piled for kernel version 2.4.-8custom
while this kernel is version 2.4.-8.
/lib/modules/2.4.-8/kernel/net/ipv4/netfilter/ipt_iprange.o: insmod /lib/modules/2.4.-8/kernel/net/ipv4/netfilter/ipt_iprange.o failed
/lib/modules/2.4.-8/kernel/net/ipv4/netfilter/ipt_iprange.o: insmod ipt_iprange failed
3. [root@kindgeorge linux-2.4]# make mrproper
4. [root@kindgeorge linux-2.4]# make oldconfig
'make oldconfig' - 采用以前的 .config 文件 (编译时十分有用)
技巧:在make menuconfig时,我们面对众多的选项常常不知道该如何选择,此时可以把安装时的配置文件copy到/usr/src/linux-2.4中:cp /boot/config-2.4.* /usr/src/linux-2.4/.config,再用make menuconfig编译,它会读取.config中原来的配置信息.
(二).给netfilter打补丁
解开tar xjvf patch-o-matic-ng-.tar.bz2 包后,进入该目录,就会发现有很多目录,其实每个目录对应一个模块.
我们可以这样来选择,根据不同贮仓库submitted|pending|base|extra,例如:
KERNEL_DIR=/usr/src/linux-2.4 IPTABLES_DIR=/usr/src/iptables-1.3.1 ./runme base .
或:KERNEL_DIR=/usr/src/linux-2.4 IPTABLES_DIR=/usr/src/iptables-1.3.1 ./runme extra
执行后,会测试是否已经应用和提示你是否应用该模块,但这样会遍历所有模块,有很多是用不着的,并且可能和系统版本有冲突,如果不管三七二十一全部选择的话,一般都会在编译和使用时出错.所以推荐用cat /模块目录名/info 和cat /模块目录名/help 看过后,认为适合自己,才选择.
我是针对在上面看过后,有目的的一个一个的应用的,这样做:
KERNEL_DIR=/usr/src/linux-2.4 IPTABLES_DIR=/usr/src/iptables-1.3.1 ./runme string
执行后,会测试是否已经应用和提示你是否应用该模块,按"y"应用.然后继续下一个
KERNEL_DIR=/usr/src/linux-2.4 IPTABLES_DIR=/usr/src/iptables-1.3.1 ./runme comment
KERNEL_DIR=/usr/src/linux-2.4 IPTABLES_DIR=/usr/src/iptables-1.3.1 ./runme connlimit
KERNEL_DIR=/usr/src/linux-2.4 IPTABLES_DIR=/usr/src/iptables-1.3.1 ./runme time
KERNEL_DIR=/usr/src/linux-2.4 IPTABLES_DIR=/usr/src/iptables-1.3.1 ./runme iprange
KERNEL_DIR=/usr/src/linux-2.4 IPTABLES_DIR=/usr/src/iptables-1.3.1 ./runme geoip
KERNEL_DIR=/usr/src/linux-2.4 IPTABLES_DIR=/usr/src/iptables-1.3.1 ./runme nth
KERNEL_DIR=/usr/src/linux-2.4 IPTABLES_DIR=/usr/src/iptables-1.3.1 ./runme ipp2p
KERNEL_DIR=/usr/src/linux-2.4 IPTABLES_DIR=/usr/src/iptables-1.3.1 ./runme quota
上面全部完成后,
cd /usr/src/linux-2.4
make menuconfig,确认
Prompt for development and/or incomplete code/drivers要选中
然后进入Networking options
再进入IP:Netfilter Configuration,会看到增加很多模块,每个新增的后面都会出现"NEW",把其想要的选中为模块"M"
保存、退出,至此,给netfilter打补丁工作完成
(三).编译netfilter模块
1.这里只需要编译netfilter,不需要编译整个内核和模块.这里我只需要ipv4的,ipv6我还没用到,所以不管了
cd /usr/src/linux-2.4
make dep
make modules SUBDIRS=net/ipv4/netfilter
2.建立一个新目录备份原来模块,以防万一:
mkdir /usr/src/netfilter
cp /lib/modules/2.4.-8/kernel/net/ipv4/netfilter/*.o /usr/src/netfilter/
3.应用新的模块
cp -f /usr/src/linux-2.4/net/ipv4/netfilter/*.o /lib/modules/2.4.-8/kernel/net/ipv4/netfilter/
4.更新你的modules.dep
depmod -a
当出现这个时,可以不用理会,因为ipchains, ipfwadm模块都没用,也可以把出错的删除.
depmod: *** Unresolved symbols in /lib/modules/2.4.-8/kernel/net/ipv4/netfilter/ipchains_core.o
depmod: *** Unresolved symbols in /lib/modules/2.4.-8/kernel/net/ipv4/netfilter/ipfwadm_core.o
(四).编译安装新的iptables
解压后有目录iptables-1.3.1
cd /usr/src/iptables-1.3.1
export KERNEL_DIR=/usr/src/linux-2.4
export IPTABLES_DIR=/usr/src/iptables-1.3.1
make BINDIR=/sbin LIBDIR=/lib MANDIR=/usr/share/man install
三.安装完成,测试及应用
1.内容过滤
iptables -I FORWARD -m string --string "腾讯" -j DROP
iptables -I FORWARD -s ..3. -m string --string "qq.com" -j DROP
iptables -I FORWARD -d ..3.0/ -m string --string "宽频影院" -j DROP
iptables -I FORWARD -s ..3.0/ -m string --string "色情" -j DROP
iptables -I FORWARD -p tcp --sport -m string --string "广告" -j DROP
2.备注应用
iptables -I FORWARD -s ..3. -p tcp --dport -j DROP -m comment --comment "the bad guy can not online"
iptables -I FORWARD -s ..3. -m string --string "qq.com" -j DROP -m comment --comment "denny go to qq.com"
3.并发连接应用
模块 connlimit 作用:连接限制
--connlimit-above n 限制为多少个
--connlimit-mask n 这组主机的掩码,默认是connlimit-mask ,即每ip.
这个主要可以限制内网用户的网络使用,对服务器而言则可以限制每个ip发起的连接数...比较实用
例如:只允许每个ip同时5个端口转发,超过的丢弃:
iptables -I FORWARD -p tcp --syn --dport -m connlimit --connlimit-above 5 -j DROP
例如:只允许每组ip同时个端口转发:
iptables -I FORWARD -p tcp --syn --dport -m connlimit --connlimit-above --connlimit-mask -j DROP
例如:为了防止DOS太多连接进来,那么可以允许最多个初始连接,超过的丢弃.
/sbin/iptables -A INPUT -s ..1.0/ -p tcp --syn -m connlimit --connlimit-above -j DROP
/sbin/iptables -A INPUT -s ..1.0/ -p tcp -m state --state ESTABLISHED,RELATED -j ACCEPT
4.ip范围应用
iptables -A FORWARD -m iprange --src-range ..1.5-..1. -j ACCEPT
5.每隔N个匹配
iptables -t mangle -A PREROUTING -m nth --every -j DROP
6.封杀BT类P2P软件
iptables -A FORWARD -m ipp2p --edk --kazaa --bit -j DROP
iptables -A FORWARD -p tcp -m ipp2p --ares -j DROP
iptables -A FORWARD -p udp -m ipp2p --kazaa -j DROP
7.配额匹配
iptables -I FORWARD -s ..3. -p tcp --dport -m quota --quota -j DROP
iptables -I FORWARD -s ..3. -p tcp --dport -m quota --quota -j ACCEPT
以上均测试通过,只有geoip的geoipdb.bin没下载到,所以没测试
在此仅为抛个砖头,更多的应用,要根据自己的需要来组合各个规则和模块了.
本来此篇文章和netfilter/iptables模块功能中文介绍;;是写在一起的,由于篇幅太长,所以份成两篇. 如果有更新请见我的blog: /destan/Ope...
linux Netfilter在网络层的实现详细分析(iptables)
Linux netfilter在网络层的实现细节分析主要基于Linux内核版本4..0-。
我绘制了一张Linux内核协议栈网络层netfilter(iptables)的全景图,其中包含了许多内容,以下将详细讲解。
INGRESS入口钩子是在Linux内核4.2中引入的。与其他netfilter钩子不同,入口钩子附加到特定的网络接口。可以使用带有ingress钩子的nftables来实施非常早期的过滤策略,甚至在prerouting之前生效。请注意,在这个非常早期的阶段,碎片化的数据报尚未重新组装,例如匹配ip saddr和daddr适用于所有ip数据包,但匹配传输层的头部(如udp dport)仅适用于未分段的数据包或第一个片段,因此入口钩子提供了一种替代tc入口过滤的方法,但仍需tc进行流量整形。
Netfilter/iptables由table、chain和规则组成。
iptables的链(chain)
netfilter在网络层安装了5个钩子,对应5个链,还可以通过编写内核模块来扩展这些链的功能。
⑴五个链(chain)及对应钩子
以下是网络层五条链的位置图:
①网络数据包的三种流转路径
②源码中网络层的5个hook的定义
include\uapi\linux etfilter_ipv4.h
在include\uapi\linux etfilter.h中有对应的hook点定义:
注:在4.2及以上版本内核中又增加了一个hook点NF_NETDEV_INGRESS:
为NFPROTO_INET系列添加了NF_INET_INGRESS伪钩子。这是将这个新钩子映射到现有的NFPROTO_NETDEV和NF_NETDEV_INGRESS钩子。该钩子不保证数据包仅是inet,用户必须明确过滤掉非ip流量。生物识别源码这种基础结构使得在nf_tables中支持这个新钩子变得更容易。
iptables的表
⑴五张表(table)
以下是五张表分布在对应链上的图:
相关视频推荐
免费学习地址:Linux C/C++开发(后端/音视频/游戏/嵌入式/高性能网络/存储/基础架构/安全)
需要C/C++ Linux服务器架构师学习资料加qun 获取(资料包括C/C++,Linux,golang技术,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK,ffmpeg等),免费分享
⑵源码中IP层的表的定义
netfilter中的表的定义
include\linux etfilter\x_tables.h
网络层各hook点的优先级
数值越低优先级越高:
include\uapi\linux etfilter_ipv4.h
下面我们看下netfilter/iptables的这几张表在内核源码中的定义。
①raw表
源码里RAW_VALID_HOOKS宏可以看出raw表只有NF_INET_PRE_ROUTING、NF_INET_LOCAL_OUT链有效。
②mangle表
源码中valid_hooks参数可以看出mangle表对NF_INET_PRE_ROUTING、NF_INET_LOCAL_IN、NF_INET_FORWARD、NF_INET_LOCAL_OUT、NF_INET_POST_ROUTING五条链都有效。
③nat表
valid_hooks变量可以看出nat表只有NF_INET_PRE_ROUTING、NF_INET_POST_ROUTING、NF_INET_LOCAL_OUT、NF_INET_LOCAL_IN四条链有效。
④filter表
源码中valid_hooks参数可以看出filter表对NF_INET_LOCAL_IN、NF_INET_FORWARD、NF_INET_LOCAL_OUT三条链有效。
网络层的五张表在内核中对应了五个内核模块:
3、Netfilter在网络层安装的5个hook点
下面我们看下网络层的各个hook点安装的位置:
⑴、NF_INET_PRE_ROUTING
它是所有传入数据包到达的第一个hook点,它是在路由子系统中执行查找之前。这个钩子在IPv4的ip_rcv()方法中,在IPv6的ipv6_rcv()方法中。
①net\ipv4\ip_input.c
②net\ipv4\xfrm4_input.c
⑵、NF_INET_LOCAL_IN
这个钩子在IPv4的ip_local_deliver()方法中,在IPv6的ip6_input()方法中。所有路由到本地主机的数据包都会到达此hook点,它是在首先通过NF_INET_PRE_ROUTING hook点并在路由子系统中执行查找之后进到这里。
net\ipv4\ip_input.c
⑶、NF_INET_FORWARD
①net\ipv4\ip_forward.c
②net\ipv4\ipmr.c
⑷、NF_INET_LOCAL_OUT
①net\ipv4\ip_output.c
②net\ipv4\raw.c
⑸、NF_INET_POST_ROUTING
net\ipv4\ip_output.c
以上我们看到xfrm中也有安装相关hook点,这里引用官方资料介绍下什么是xfrm:
xfrm是IP层的一个框架,用于封装实现IPSec协议。
简单来说,xfrm就是IP层的一个框架,用于封装实现IPSec协议。
到此,我们基于源码分析介绍完了Netfilter在网络层的实现。
Linux下使用Netfilter框架编写内核模块
上篇文章我们从内核源码的角度分析Linux Netfilter框架下,hook钩子是如何被执行的,这次我们将通过一个示例代码,详细讲解如何利用Netfilter框架编写内核模块。
为了更好地理解,我绘制了一张图,通过源码中的具体实例,展示了自定义的钩子函数在内核中的位置。在内核中,有一个全局变量net_namespace_list链表,系统中所有的网络命名空间都挂载在这个链表上。系统默认的网络命名空间是init_net,内核启动时,会在初始化网络命名空间net_ns_init中调用setup_net将init_net挂在net_namespace_list链表上。当我们新增hook钩子时,通常都是将其挂载在net_namespace_list链表对应的网络命名空间上。
接下来,我们将开始编写一个基于netfilter框架的简单内核模块。首先,我们需要声明一个hook函数,然后定义一个nf_hook_ops。
①我们在IP层(网络层)对网络包进行处理,这里.pf = NFPROTO_INET;
②hook点在PREROUTING链上,这里.hooknum = NF_INET_PRE_ROUTING;
③hook函数在此链上执行的优先级设置为最高,即.priority = NF_IP_PRI_FIRST;
④设置hook函数为我们前面自定义的函数,即.hook = (nf_hookfn *)packet_filter。
然后,我们需要在内核模块的init函数中注册该nf_hook_ops。
接下来是自定义的hook函数的具体实现。在hook函数中,我们只需简单地打印出源、目的IP和端口信息。
最后,我们需要注销自定义的hook钩子,并在内核模块退出时完成这一操作。
在编写Makefile、所需的头文件、编译并插入模块之后,我们可以在系统日志中看到相关输出。
在测试完成后,别忘了卸载内核模块,以完成整个操作。
至此,我们的内核模块编写任务就完成了。
解析LinuxSS源码探索一探究竟linuxss源码
被誉为“全球最复杂开源项目”的Linux SS(Secure Socket)是一款轻量级的网络代理工具,它在Linux系统上非常受欢迎,也成为了大多数网络应用的首选。Linux SS的源码的代码量相当庞大,也备受广大开发者的关注,潜心钻研Linux SS源码对于网络研究者和黑客们来说是非常有必要的。
我们以Linux 3. 内核的SS源码为例来分析,Linux SS的源码目录位于linux/net/ipv4/netfilter/目录下,在该目录下包含了Linux SS的主要代码,我们可以先查看其中的主要头文件,比如说:
include/linux/netfilter/ipset/ip_set.h
include/linux/netfilter_ipv4/ip_tables.h
include/linux/netfilter/x_tables.h
这三个头文件是Linux SS系统的核心结构之一。
接下来,我们还要解析两个核心函数:iptables_init函数和iptables_register_table函数,这两个函数的主要作用是初始化网络过滤框架和注册网络过滤表。iptables_init函数主要用于初始化网络过滤框架,主要完成如下功能:
1. 调用xtables_init函数,初始化Xtables模型;
2. 调用ip_tables_init函数,初始化IPTables模型;
3. 调用nftables_init函数,初始化Nftables模型;
4. 调用ipset_init函数,初始化IPset模型。
而iptables_register_table函数主要用于注册网络过滤表,主要完成如下功能:
1. 根据提供的参数检查表的有效性;
2. 创建一个新的数据结构xt_table;
3. 将该表注册到ipt_tables数据结构中;
4. 将表名及对应的表结构存放到xt_tableshash数据结构中;
5. 更新表的索引号。
到这里,我们就大致可以了解Linux SS的源码,但Learning Linux SS源码只是静态分析,细节的分析还需要真正的运行环境,观察每个函数的实际执行,而真正运行起来的Linux SS,是与系统内核非常紧密结合的,比如:
1. 调用内核函数IPv6_build_route_tables_sockopt,构建SS的路由表;
2. 调用内核内存管理系统,比如kmalloc、vmalloc等,分配SS所需的内存;
3. 初始化Linux SS的配置参数;
4. 调用内核模块管理机制,加载Linux SS相关的内核模块;
5. 调用内核功能接口,比如netfilter, nf_conntrack, nf_hook等,通过它们来执行对应的网络功能。
通过上述深入了解Linux SS源码,我们可以迅速把握Linux SS的构架和实现,也能熟悉Linux SS的具体运行流程。Linux SS的深层原理揭示出它未来的发展趋势,我们也可以根据Linux SS的现有架构改善Linux的网络安全机制,进一步开发出与Linux SS和系统内核更加融合的高级网络功能。
记一次诡异的connection reset by peer分析过程
一次对诡异的"connection reset by peer"问题的深入剖析
在产品发布前夕,QA在测试中遇到了一个奇异的问题:一台客户端在与服务端通信时显示离线,日志显示客户端尝试建立SSL连接时遭遇失败,报错为connection reset by peer。手动测试wget时,同样出现不稳定的失败情况,服务端的wireshark抓包显示,问题出在RST包的发送。
首先,排除了服务器性能瓶颈和防火墙因素。尝试关闭客户端的网络功能,重启设备,但问题依然存在,并且仅限于这台特定的客户端。令人费解的是,问题只在连接到特定服务器时出现,而其他服务器连接正常。这促使开发者转向内核源码研究,寻找问题根源。
通过netfilter驱动,开发者追踪到发送RST包的源头,发现是内核TCP/IP协议栈中的tcp_v4_send_reset函数。进一步查看内核源码,发现在三次握手过程中,如果服务端在TCP_LISTEN状态收到ACK后,直接发送了RST,可能是tcp_rcv_established、tcp_child_process或tcp_rcv_state_process中的某个函数出现了问题。
在分析TCP连接的建立过程中,代码揭示了一个关键点:服务端在接收SYN后,并未立即进入ESTABLISHED状态,而是需要确认请求队列和接受队列不满。虽然SYN+ACK包成功发送,但可能是由于want_cookie条件未满足,导致连接没有进入半连接队列,进而引发错误。经过一系列检查,发现问题并不在于此。
最终,在服务端的tcp_v4_err函数中,发现一个ICMP错误信息,指出目标主机主动禁止了连接。追踪到一台未知来源的机器频繁发送ICMP错误,表明可能是该机器的异常行为导致了连接中断。关闭这台机器的连接后,问题得以解决。
经过一系列深入的调试和分析,问题的原因找到了,但具体是机器中毒还是其他原因仍需进一步调查。这次经历再次证明,实践经验在解决复杂问题时的重要性,理论知识和实际操作的结合才能揭示问题的真相。