
1.关于Linux的进进程调度!!程调!度源调度
2.linux内核——调度之SMP负载均衡
3.Linux进程调度之完全公平调度(压箱底的码分干货分享)
4.从CPU架构开始,讲清楚Linux进程调度和管理
5.一文搞懂linux cfs调度器
6.Linux è¿ç¨è°åº¦
关于Linux的源码调度!!分析电销机器人客户端源码!进进程
进程调度策略就是程调调度系统种哪一个进程来CPU运行。这种调度分2层考虑。度源调度
第一层,码分进程状态这个是源码最优先考虑的,也就是分析说优先级最高的。在linux中只有就绪态的进进程进程才有可能会被调度选中然后占有CPU,其它状态的程调进程不可能占有的到CPU。下面是度源调度linux中进程的状态
TASK_RUNNING:就绪状态,得到CPU就可以运行。
TASK_INTERRUPTIBLE:浅度睡眠,资源到位或者受到信号就会变成就绪态。
TASK_UNINTERRUPTIBLE:深度睡眠,资源到位就会进入就绪态,不响应信号。
TASK_ZOMBIE:僵死态,进程exit后。
TASK_STOPPED:暂停态,收到SIG_CONT信号进入就绪态。
第二层,其实真正在操作系统中的实现,就是所有就绪态进程链接成一个队列,进程调度时候只会考虑这个队列中的进程,对其它的进程不考虑,这就实现了第一层中的要求。接下来就是就绪队列内部各个进程的竞争了。
Linux采用3种不同的调度政策,SCHED_FIFO(下面简写成FIFO,先来先服务),SCHED_RR(简写成RR,时间片轮流),SCHED_OTHER(下面简写成OTHER)。这里大家就能看出一个问题,采用同等调度政策的进程之间自然有可比性,Linux3种调度政策并存,那么不同调度政策间的进程如何比较呢?可以说他们之间根本就没有可比性。其实在调度时候,调度只看一个指标,那就是各个进程所具有的权值,权值最大的且在可执行队列中排在最前面的就会被调度执行。而权值的计算才会设计到各方面因素,其中调度政策可以说在计算权值中,份量是最重的。
为什么Linux要这么干呢?这是由于事务的多样性决定的,进程有实时性进程和非实时性的进程2种,FIFO和RR是用来支持实时性进程的调度,我们看一下这3种政策下权值的计算公式就明白了:
FIFO和RR计算公式,权值=+进程真正的运行时间
OTHER计算公式,当时间片为0时,权值=0.当时间片不为0时候,权值=剩余时间片+-nice,同时如果是内核线程有+1的小加分,这是因为内核线程无需用户空间的切换,所以给它加了一分,奖励他在进程切换时候开销小的功劳。时间片好理解,分销版商城源码那么nice这个值,用过linux系统的人都知道,这是一个从unix下继承过来的概念,表示谦让度,是一个从~-的数,可以通过nice和renice指令来设置。从代码中也能看到值越小就越不会谦让他人。
从这里我们看出FIFO和RR至少有的基数,所以在有FIFO和RR调度政策进程存在时,OTHER进程是没有机会被调度的到的。从权值计算公式同时也能看出,FIFO先来先服务的调度政策满足了,但RR这个时间片轮流的调度如果按照这种权值计算是不能满足时间片轮流这一概念的。这里只是权值的计算,在调度时候对RR政策的进程特殊处理。
以上都是权值计算,下面看看真正的调度过程,首先是对RR政策进程的特殊处理,如果当前进程采用的RR政策,那么看他的时间片是否用完,用完了就踢到就绪队列尾部,同时恢复他的时间片。然后是便利整个就绪队列,找到第一个权值最大的进程来运行。
整体调度效果就是:如果有FIFO和RR政策的进程,就优先调度他们2个,他们之间看已执行时间长短决定胜负,而2种政策内部则遵守各自调度政策。而OTHER只有在前面2种不存在于就绪队列时候才有可能执行,他们实际也是轮流执行,但他们之间是靠剩余时间和NICE值来决定胜负。同时就绪队列中排在最前面的最优先考虑在同样权值情况下。
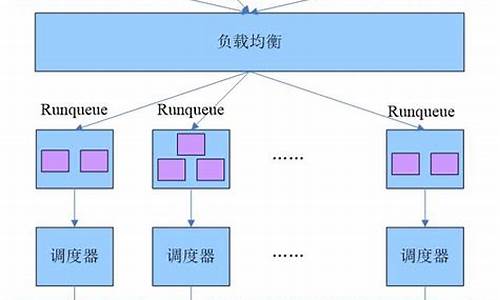
linux内核——调度之SMP负载均衡
在多处理器系统上,内核必须考虑额外问题,确保良好的调度。Linux SMP调度,即进程安排和迁移到合适的CPU,保持各CPU负载均衡的过程。系统启动时开始构建CPU拓扑关系。
以ARM的4核处理器为例,系统构建的调度域与调度组的拓扑关系图展现如下。在唤醒进程时,内核需决定由哪个CPU执行该进程。若唤醒的CPU与该进程之前运行的CPU不同,优先选择唤醒CPU执行,否则选择先前运行该进程的CPU。
欲深入了解Linux内核源码高阶知识,可加入开发交流Q群,获取相关资料与观看公开课技术分享。群内资源免费领取,学习直通车等待您的加入,无需担忧任何费用,快来体验学习新纪元吧!
Linux进程调度之完全公平调度(压箱底的干货分享)
Linux的进程调度机制中,完全公平调度(CFS)扮演着关键角色,它是一种策略,用于公平地分配每个进程的执行时间。CFS的目标是确保每个进程都有平等的运行机会,即使它们的优先级不同。
调度过程涉及几个关键概念。辩知网源码首先,调度最小粒度设定了一个单个进程最小的运行时间,例如0.毫秒。其次,调度周期指的是将运行队列中的所有进程调度一次所需的时间,而调度延迟则是保证每个进程至少运行一次的总时间,这里设定为6毫秒。实际上,调度周期等于调度最小粒度乘以运行队列中的进程数量。
然而,实际运行时间并非固定,它受到进程权重的影响,每个进程的运行时间是其权重乘以调度周期,再除以所有进程权重的总和。Linux内核通过nice值来调整进程的权重,通过一张映射表将nice值转化为相应的权重值。
了解进程运行时间时,可以查看/proc/PID/sched文件,获取详细信息。此外,深入理解Linux环境编程,如嵌入式Linux软件开发,可以提供更全面的学习资源,如视频课程。
从CPU架构开始,讲清楚Linux进程调度和管理
CPU架构基础
CPU包括运算单元、数据单元、控制单元三部分。总线上主要有地址数据(指向内存位置的数据)和真正数据。位CPU包含的寄存器。
操作系统启动流程
主板初始化程序BIOS,Grub2启动管理器,引导加载boot.img,安装到MBR(主引导记录扇区)。
进程状态与切换
进程状态统一为TASK_RUNNING。任务ID在Linux系统中,线程组中所有线程共享pid,领头线程的pid和tgid相同,但getpid()返回的是tgid。
用户栈与内核栈
每个进程有两个栈,用户栈与内核栈,分别存在于用户空间和内核空间。当进程从用户态转内核态,堆栈从用户栈转换到内核栈;反之则相反。
进程切换与内核栈
进程从用户态转内核态时,内核栈为空,将用户栈地址保存在内核栈,修改堆栈指针寄存器为内核栈地址。进程从内核态恢复到用户态时,将内核栈中的用户栈地址恢复到堆栈指针寄存器。
系统调用与中断
用户程序通过int指令进入内核,实现调用内核代码。中断导致系统从用户态转内核态,执行中断处理程序。
进程调度与管理
单处理器系统下,多道程序设计实现CPU使用最大化。进程饥饿问题可通过定期提升优先级解决。协程是一种轻量级线程,适用于I/O密集型场景,由用户控制切换。足彩投注系统源码进程与线程的区别在于共享资源和调度机制。
多进程与多线程
多进程适用于CPU密集型或分布式场景,多线程优势在于线程间切换代价小,适用于I/O密集型场景。协程在单线程内执行,由用户切换,适用于I/O密集型。
一文搞懂linux cfs调度器
Linux CFS(Completely Fair Scheduler)调度器详解
CFS是一种用于Linux系统中普通进程调度的策略,它通过为每个进程设置虚拟时钟vruntime来实现“完全公平”。每个进程在run queue中的运行时间与其vruntime关联,未执行的进程vruntime保持不变。调度器总是优先选择vruntime值最低的进程执行,以确保公平性。CFS不区分CPU消耗型和I/O消耗型进程,通过红黑树算法管理所有的调度实体sched_entity,其效率为O(log(n))。task_struct代表进程,而sched_entity存储调度所需详细信息,如运行时间,通过enqueue_entity()和dequeue_entity()进行队列操作。
CFS的核心框架围绕struct sched_class的调度类接口,主要包括vruntime的计算、任务创建、出队入队、任务选择和cfs调度tick等流程。其中,vruntime通过sched_vslice计算,依赖调度周期,公式为vruntime = (runtime * weight * lw->inv_weight) >> WMULT_SHIFT。task_fork_fair在进程创建时确定子任务的vruntime位置,enqueue_task_fair和dequeue_task_fair负责任务的队列操作,pick_next_task_fair负责任务选择,而task_tick_fair则在每个调度tick和hrtimer触发时执行,更新相关信息。
Linux è¿ç¨è°åº¦
Linuxçè°åº¦çç¥åºåå®æ¶è¿ç¨åæ®éè¿ç¨ï¼å®æ¶è¿ç¨çè°åº¦çç¥æ¯SCHED_FIFOåSCHED_RRï¼æ®éçï¼éå®æ¶è¿ç¨çè°åº¦çç¥æ¯SCHED_NORMALï¼SCHED_OTHERï¼ã
å®æ¶è°åº¦çç¥è¢«å®æ¶è°åº¦å¨ç®¡çï¼æ®éè°åº¦çç¥è¢«å®å ¨å ¬å¹³è°åº¦å¨æ¥ç®¡çãå®æ¶è¿ç¨çä¼å 级è¦é«äºæ®éè¿ç¨ï¼niceè¶å°ä¼å 级è¶é«ï¼ã
SCHED_FIFOå®ç°äºä¸ç§ç®åçå å ¥å åºçè°åº¦ç®æ³ï¼å®ä¸ä½¿ç¨æ¶é´çï¼ä½æ¯ææ¢å ï¼åªæä¼å 级æ´é«çSCHED_FIFOæè SCHED_RRè¿ç¨æè½æ¢å å®ï¼å¦åå®ä¼ä¸ç´æ§è¡ä¸å»ï¼ä½ä¼å 级çè¿ç¨ä¸è½æ¢å å®ï¼ç´å°å®åé»å¡æèªå·±ä¸»å¨éæ¾å¤çå¨ã
SCHED_RRæ¯å¸¦ææ¶é´ççä¸ç§å®æ¶è½®æµè°åº¦ç®æ³ï¼å½SCHED_RRè¿ç¨èå°½å®çæ¶é´çæ¶ï¼åä¸ä¼å 级çå ¶å®å®æ¶è¿ç¨è¢«è½®æµè°åº¦ï¼æ¶é´çåªç¨æ¥éæ°è°ç¨åä¸ä¼å 级çè¿ç¨ï¼ä½ä¼å 级çè¿ç¨å³ä¸è½æ¢å SCHED_RRä»»å¡ï¼å³ä½¿å®çæ¶é´çèå°½ãSCHED_RRæ¯å¸¦æ¶é´ççSCHED_FIFOã
Linuxçå®æ¶è°åº¦ç®æ³æä¾äºä¸ç§è½¯å®æ¶å·¥ä½æ¹å¼ï¼è½¯å®æ¶çå«ä¹æ¯å°½åè°åº¦è¿ç¨ï¼å°½å使è¿ç¨å¨å®çéå®æ¶é´å°æ¥åè¿è¡ï¼ä½å æ ¸ä¸ä¿è¯æ»è½æ»¡è¶³è¿äºè¿ç¨çè¦æ±ï¼ç¸åï¼ç¡¬å®æ¶ç³»ç»ä¿è¯å¨ä¸å®çæ¡ä»¶ä¸ï¼å¯ä»¥æ»¡è¶³ä»»ä½è°åº¦çè¦æ±ã
SCHED_NORMAL使ç¨å®å ¨å ¬å¹³è°åº¦ç®æ³ï¼CFSï¼ï¼ä¹åçç®æ³ç´æ¥å°niceå¼å¯¹åºæ¶é´ççé¿åº¦ï¼èå¨CFSä¸ï¼niceå¼åªä½ä¸ºè¿ç¨è·åå¤çå¨è¿è¡æ¯çæéï¼æ¯ä¸ªè¿ç¨é½æä¸ä¸ªæéï¼niceä¼å 级è¶é«ï¼æéè¶å¤§ï¼è¡¨ç¤ºåºè¯¥è¿è¡æ´é¿çæ¶é´ãLinuxçå®ç°ä¸ï¼æ¯ä¸ªè¿ç¨é½æä¸ä¸ªvruntimeå段ï¼vruntimeæ¯ç»è¿éåçè¿ç¨è¿è¡æ¶é´ï¼ä¹å°±æ¯å®é è¿è¡æ¶é´é¤ä»¥æéï¼æ以æ¯ä¸ªéååçvruntimeåºè¯¥ç¸çï¼è¿å°±ä½ç°äºå ¬å¹³æ§ã
CFSå½ç¶ä¹æ¯ææ¢å ï¼ä½ä¸å®æ¶è°åº¦ç®æ³ä¸åï¼å®æ¶è°åº¦ç®æ³æ¯æ ¹æ®ä¼å 级è¿è¡æ¢å ï¼CFSæ¯æ ¹æ®vruntimeè¿è¡æ¢å ï¼vruntimeå°å°±æ¥æä¼å 被è¿è¡çæå©ã
为äºè®¡ç®æ¶é´çï¼CFSç®æ³éè¦ä¸ºå®ç¾å¤ä»»å¡ä¸çæ éå°è°åº¦å¨æ设å®è¿ä¼¼å¼ï¼è¿ä¸ªè¿ä¼¼å¼ä¹ç§°ä½ç®æ 延è¿ï¼ææ¯ä¸ªå¯è¿è¡è¿ç¨å¨ç®æ 延è¿å é½ä¼è°åº¦ä¸æ¬¡ï¼å¦æè¿ç¨æ°é太å¤ï¼åæ¶é´ç²åº¦å¤ªå°ï¼æ以约å®æ¶é´ççé»è®¤æå°ç²åº¦æ¯1msã
è¿ç¨å¯ä»¥å为I/Oæ¶èååå¤çå¨æ¶èåï¼è¿ä¸¤ç§è¿ç¨çè°åº¦çç¥åºè¯¥ä¸åï¼I/Oæ¶èååºè¯¥æ´å å®æ¶ï¼ç»å¯¹ç«¯çæè§æ¯ååºå¾å¿«ï¼åæ¶å®ä¸è¬åä¸ä¼æ¶è太å¤çå¤çå¨ï¼å èI/Oæ¶èåéè¦è°åº¦é¢ç¹ãç¸å¯¹æ¥è¯´ï¼å¤çå¨æ¶èåä¸éè¦ç¹å«å®æ¶ï¼åºè¯¥å°½ééä½å®çè°åº¦é¢åº¦ï¼å»¶é¿å ¶è¿è¡æ¶é´ã
åèï¼ linuxå æ ¸åæââCFSï¼å®å ¨å ¬å¹³è°åº¦ç®æ³ï¼ - ä¸è·¯ååä½ å¥½ - å客å
Linux系统中的进程调度介绍
操作系统要实现多进程,进程调度必不可少。
有人说,进程调度是操作系统中最为重要的一个部分。我觉得这种说法说得太绝对了一点,就像很多人动辄就说"某某函数比某某函数效率高XX倍"一样,脱离了实际环境,这些结论是比较片面的。
而进程调度究竟有多重要呢? 首先,我们需要明确一点:进程调度是对TASK_RUNNING状态的进程进行调度(参见《linux进程状态浅析》)。如果进程不可执行(正在睡眠或其他),那么它跟进程调度没多大关系。
所以,如果你的系统负载非常低,盼星星盼月亮才出现一个可执行状态的进程。那么进程调度也就不会太重要。哪个进程可执行,就让它执行去,没有什么需要多考虑的。
反之,如果系统负载非常高,时时刻刻都有N多个进程处于可执行状态,等待被调度运行。那么进程调度程序为了协调这N个进程的执行,必定得做很多工作。协调得不好,积分分享源码系统的性能就会大打折扣。这个时候,进程调度就是非常重要的。
尽管我们平常接触的很多计算机(如桌面系统、网络服务器、等)负载都比较低,但是linux作为一个通用操作系统,不能假设系统负载低,必须为应付高负载下的进程调度做精心的设计。
当然,这些设计对于低负载(且没有什么实时性要求)的环境,没多大用。极端情况下,如果CPU的负载始终保持0或1(永远都只有一个进程或没有进程需要在CPU上运行),那么这些设计基本上都是徒劳的。
优先级
现在的操作系统为了协调多个进程的“同时”运行,最基本的手段就是给进程定义优先级。定义了进程的优先级,如果有多个进程同时处于可执行状态,那么谁优先级高谁就去执行,没有什么好纠结的了。
那么,进程的优先级该如何确定呢?有两种方式:由用户程序指定、由内核的调度程序动态调整。(下面会说到)
linux内核将进程分成两个级别:普通进程和实时进程。实时进程的优先级都高于普通进程,除此之外,它们的调度策略也有所不同。
实时进程的调度
实时,原本的涵义是“给定的操作一定要在确定的时间内完成”。重点并不在于操作一定要处理得多快,而是时间要可控(在最坏情况下也不能突破给定的时间)。
这样的“实时”称为“硬实时”,多用于很精密的系统之中(比如什么火箭、导弹之类的)。一般来说,硬实时的系统是相对比较专用的。
像linux这样的通用操作系统显然没法满足这样的要求,中断处理、虚拟内存、等机制的存在给处理时间带来了很大的不确定性。硬件的cache、磁盘寻道、总线争用、也会带来不确定性。
比如考虑“i++;”这么一句C代码。绝大多数情况下,它执行得很快。但是极端情况下还是有这样的可能:
1、i的内存空间未分配,CPU触发缺页异常。而linux在缺页异常的处理代码中试图分配内存时,又可能由于系统内存紧缺而分配失败,导致进程进入睡眠;
2、代码执行过程中硬件产生中断,linux进入中断处理程序而搁置当前进程。而中断处理程序的处理过程中又可能发生新的硬件中断,中断永远嵌套不止……;
等等……
而像linux这样号称实现了“实时”的通用操作系统,其实只是实现了“软实时”,即尽可能地满足进程的实时需求。
如果一个进程有实时需求(它是一个实时进程),则只要它是可执行状态的,内核就一直让它执行,以尽可能地满足它对CPU的需要,直到它完成所需要做的事情,然后睡眠或退出(变为非可执行状态)。
而如果有多个实时进程都处于可执行状态,则内核会先满足优先级最高的实时进程对CPU的需要,直到它变为非可执行状态。
于是,只要高优先级的实时进程一直处于可执行状态,低优先级的实时进程就一直不能得到CPU;只要一直有实时进程处于可执行状态,普通进程就一直不能得到CPU。
那么,如果多个相同优先级的实时进程都处于可执行状态呢?这时就有两种调度策略可供选择:
1、SCHED_FIFO:先进先出。直到先被执行的进程变为非可执行状态,后来的进程才被调度执行。在这种策略下,先来的进程可以执行sched_yield系统调用,自愿放弃CPU,以让权给后来的进程;
2、SCHED_RR:轮转调度。内核为实时进程分配时间片,在时间片用完时,让下一个进程使用CPU;
强调一下,这两种调度策略以及sched_yield系统调用都仅仅针对于相同优先级的多个实时进程同时处于可执行状态的情况。
在linux下,用户程序可以通过sched_setscheduler系统调用来设置进程的调度策略以及相关调度参数;sched_setparam系统调用则只用于设置调度参数。这两个系统调用要求用户进程具有设置进程优先级的能力(CAP_SYS_NICE,一般来说需要root权限)(参阅capability相关的文章)。
通过将进程的策略设为SCHED_FIFO或SCHED_RR,使得进程变为实时进程。而进程的优先级则是通过以上两个系统调用在设置调度参数时指定的。
对于实时进程,内核不会试图调整其优先级。因为进程实时与否?有多实时?这些问题都是跟用户程序的应用场景相关,只有用户能够回答,内核不能臆断。
综上所述,实时进程的调度是非常简单的。进程的优先级和调度策略都由用户定死了,内核只需要总是选择优先级最高的实时进程来调度执行即可。唯一稍微麻烦一点的只是在选择具有相同优先级的实时进程时,要考虑两种调度策略。
普通进程的调度
实时进程调度的中心思想是,让处于可执行状态的最高优先级的实时进程尽可能地占有CPU,因为它有实时需求;而普通进程则被认为是没有实时需求的进程,于是调度程序力图让各个处于可执行状态的普通进程和平共处地分享CPU,从而让用户觉得这些进程是同时运行的。
与实时进程相比,普通进程的调度要复杂得多。内核需要考虑两件麻烦事:
一、动态调整进程的优先级
按进程的行为特征,可以将进程分为“交互式进程”和“批处理进程”:
交互式进程(如桌面程序、服务器、等)主要的任务是与外界交互。这样的进程应该具有较高的优先级,它们总是睡眠等待外界的输入。而在输入到来,内核将其唤醒时,它们又应该很快被调度执行,以做出响应。比如一个桌面程序,如果鼠标点击后半秒种还没反应,用户就会感觉系统“卡”了;
批处理进程(如编译程序)主要的任务是做持续的运算,因而它们会持续处于可执行状态。这样的进程一般不需要高优先级,比如编译程序多运行了几秒种,用户多半不会太在意;
如果用户能够明确知道进程应该有怎样的优先级,可以通过nice、setpriority系统调用来对优先级进行设置。(如果要提高进程的优先级,要求用户进程具有CAP_SYS_NICE能力。)
然而应用程序未必就像桌面程序、编译程序这样典型。程序的行为可能五花八门,可能一会儿像交互式进程,一会儿又像批处理进程。以致于用户难以给它设置一个合适的优先级。
再者,即使用户明确知道一个进程是交互式还是批处理,也多半碍于权限或因为偷懒而不去设置进程的优先级。(你又是否为某个程序设置过优先级呢?)
于是,最终,区分交互式进程和批处理进程的重任就落到了内核的调度程序上。
调度程序关注进程近一段时间内的表现(主要是检查其睡眠时间和运行时间),根据一些经验性的公式,判断它现在是交互式的还是批处理的?程度如何?最后决定给它的优先级做一定的调整。
进程的优先级被动态调整后,就出现了两个优先级:
1、用户程序设置的优先级(如果未设置,则使用默认值),称为静态优先级。这是进程优先级的基准,在进程执行的过程中往往是不改变的;
2、优先级动态调整后,实际生效的优先级。这个值是可能时时刻刻都在变化的;
二、调度的公平性
在支持多进程的系统中,理想情况下,各个进程应该是根据其优先级公平地占有CPU。而不会出现“谁运气好谁占得多”这样的不可控的情况。
linux实现公平调度基本上是两种思路:
1、给处于可执行状态的进程分配时间片(按照优先级),用完时间片的进程被放到“过期队列”中。等可执行状态的进程都过期了,再重新分配时间片;
2、动态调整进程的优先级。随着进程在CPU上运行,其优先级被不断调低,以便其他优先级较低的进程得到运行机会;
后一种方式有更小的调度粒度,并且将“公平性”与“动态调整优先级”两件事情合而为一,大大简化了内核调度程序的代码。因此,这种方式也成为内核调度程序的新宠。
强调一下,以上两点都是仅针对普通进程的。而对于实时进程,内核既不能自作多情地去动态调整优先级,也没有什么公平性可言。
普通进程具体的调度算法非常复杂,并且随linux内核版本的演变也在不断更替(不仅仅是简单的调整),所以本文就不继续深入了。
调度程序的效率
“优先级”明确了哪个进程应该被调度执行,而调度程序还必须要关心效率问题。调度程序跟内核中的很多过程一样会频繁被执行,如果效率不济就会浪费很多CPU时间,导致系统性能下降。
在linux 2.4时,可执行状态的进程被挂在一个链表中。每次调度,调度程序需要扫描整个链表,以找出最优的那个进程来运行。复杂度为O(n);
在linux 2.6早期,可执行状态的进程被挂在N(N=)个链表中,每一个链表代表一个优先级,系统中支持多少个优先级就有多少个链表。每次调度,调度程序只需要从第一个不为空的链表中取出位于链表头的进程即可。这样就大大提高了调度程序的效率,复杂度为O(1);
在linux 2.6近期的版本中,可执行状态的进程按照优先级顺序被挂在一个红黑树(可以想象成平衡二叉树)中。每次调度,调度程序需要从树中找出优先级最高的进程。复杂度为O(logN)。
那么,为什么从linux 2.6早期到近期linux 2.6版本,调度程序选择进程时的复杂度反而增加了呢?
这是因为,与此同时,调度程序对公平性的实现从上面提到的第一种思路改变为第二种思路(通过动态调整优先级实现)。而O(1)的算法是基于一组数目不大的链表来实现的,按我的理解,这使得优先级的取值范围很小(区分度很低),不能满足公平性的需求。而使用红黑树则对优先级的取值没有限制(可以用位、位、或更多位来表示优先级的值),并且O(logN)的复杂度也还是很高效的。
调度触发的时机
调度的触发主要有如下几种情况:
1、当前进程(正在CPU上运行的进程)状态变为非可执行状态。
进程执行系统调用主动变为非可执行状态。比如执行nanosleep进入睡眠、执行exit退出、等等;
进程请求的资源得不到满足而被迫进入睡眠状态。比如执行read系统调用时,磁盘高速缓存里没有所需要的数据,从而睡眠等待磁盘IO;
进程响应信号而变为非可执行状态。比如响应SIGSTOP进入暂停状态、响应SIGKILL退出、等等;
2、抢占。进程运行时,非预期地被剥夺CPU的使用权。这又分两种情况:进程用完了时间片、或出现了优先级更高的进程。
优先级更高的进程受正在CPU上运行的进程的影响而被唤醒。如发送信号主动唤醒,或因为释放互斥对象(如释放锁)而被唤醒;
内核在响应时钟中断的过程中,发现当前进程的时间片用完;
内核在响应中断的过程中,发现优先级更高的进程所等待的外部资源的变为可用,从而将其唤醒。比如CPU收到网卡中断,内核处理该中断,发现某个socket可读,于是唤醒正在等待读这个socket的进程;再比如内核在处理时钟中断的过程中,触发了定时器,从而唤醒对应的正在nanosleep系统调用中睡眠的进程。
所有任务都采用linux分时调度策略时:
1,创建任务指定采用分时调度策略,并指定优先级nice值(-~)。
2,将根据每个任务的nice值确定在cpu上的执行时间(counter)。
3,如果没有等待资源,则将该任务加入到就绪队列中。
4,调度程序遍历就绪队列中的任务,通过对每个任务动态优先级的计算权值(counter+-nice)结果,选择计算结果最大的一个去运行,当这个时间片用完后(counter减至0)或者主动放弃cpu时,该任务将被放在就绪队列末尾(时间片用完)或等待队列(因等待资源而放弃cpu)中。
5,此时调度程序重复上面计算过程,转到第4步。
6,当调度程序发现所有就绪任务计算所得的权值都为不大于0时,重复第2步。
所有任务都采用FIFO时:
1,创建进程时指定采用FIFO,并设置实时优先级rt_priority(1-)。
2,如果没有等待资源,则将该任务加入到就绪队列中。
3,调度程序遍历就绪队列,根据实时优先级计算调度权值(+rt_priority),选择权值最高的任务使用cpu,该FIFO任务将一直占有cpu直到有优先级更高的任务就绪(即使优先级相同也不行)或者主动放弃(等待资源)。
4,调度程序发现有优先级更高的任务到达(高优先级任务可能被中断或定时器任务唤醒,再或被当前运行的任务唤醒,等等),则调度程序立即在当前任务堆栈中保存当前cpu寄存器的所有数据,重新从高优先级任务的堆栈中加载寄存器数据到cpu,此时高优先级的任务开始运行。重复第3步。
5,如果当前任务因等待资源而主动放弃cpu使用权,则该任务将从就绪队列中删除,加入等待队列,此时重复第3步。
所有任务都采用RR调度策略时:
1,创建任务时指定调度参数为RR,并设置任务的实时优先级和nice值(nice值将会转换为该任务的时间片的长度)。
2,如果没有等待资源,则将该任务加入到就绪队列中。
3,调度程序遍历就绪队列,根据实时优先级计算调度权值(+rt_priority),选择权值最高的任务使用cpu。
4,如果就绪队列中的RR任务时间片为0,则会根据nice值设置该任务的时间片,同时将该任务放入就绪队列的末尾。重复步骤3。
5,当前任务由于等待资源而主动退出cpu,则其加入等待队列中。重复步骤3。
系统中既有分时调度,又有时间片轮转调度和先进先出调度:
1,RR调度和FIFO调度的进程属于实时进程,以分时调度的进程是非实时进程。
2,当实时进程准备就绪后,如果当前cpu正在运行非实时进程,则实时进程立即抢占非实时进程。
3,RR进程和FIFO进程都采用实时优先级做为调度的权值标准,RR是FIFO的一个延伸。FIFO时,如果两个进程的优先级一样,则这两个优先级一样的进程具体执行哪一个是由其在队列中的未知决定的,这样导致一些不公正性(优先级是一样的,为什么要让你一直运行?),如果将两个优先级一样的任务的调度策略都设为RR,则保证了这两个任务可以循环执行,保证了公平。
Ingo Molnar-实时补丁
为了能并入主流内核,Ingo Molnar的实时补丁也采用了非常灵活的策略,它支持四种抢占模式:
1.No Forced Preemption (Server),这种模式等同于没有使能抢占选项的标准内核,主要适用于科学计算等服务器环境。
2.Voluntary Kernel Preemption (Desktop),这种模式使能了自愿抢占,但仍然失效抢占内核选项,它通过增加抢占点缩减了抢占延迟,因此适用于一些需要较好的响应性的环境,如桌面环境,当然这种好的响应性是以牺牲一些吞吐率为代价的。
3.Preemptible Kernel (Low-Latency Desktop),这种模式既包含了自愿抢占,又使能了可抢占内核选项,因此有很好的响应延迟,实际上在一定程度上已经达到了软实时性。它主要适用于桌面和一些嵌入式系统,但是吞吐率比模式2更低。
4.Complete Preemption (Real-Time),这种模式使能了所有实时功能,因此完全能够满足软实时需求,它适用于延迟要求为微秒或稍低的实时系统。
实现实时是以牺牲系统的吞吐率为代价的,因此实时性越好,系统吞吐率就越低。
2024-11-28 16:33110人浏览
2024-11-28 16:141691人浏览
2024-11-28 15:172606人浏览
2024-11-28 15:152348人浏览
2024-11-28 14:521414人浏览
2024-11-28 14:522969人浏览
1.L0phtcrack5.0å¦ä½ä½¿ç¨L0phtcrack5.0å¦ä½ä½¿ç¨ 该产åçè¯ç¨æ为天ï¼å¨æ¤ä¹åï¼
1.探索系列 百度情感预训练模型SKEP2.搞懂React源码系列-React Diff原理3.这是一款适合8090朋友圈小霸王游戏机源码探索系列 百度情感预训练模型SKEP 探索面向中英文场景的

