欢迎来到皮皮网官网
1.审计 tinyshop 中风险
2.防御XSS的七条原则
3.程序员需要具备哪些东西?
审计 tinyshop 中风险
审计tinyshop CMS时,我们主要关注前台内容,对后台存在的安全问题略显忽视,有兴趣的开发者可自行深入研究。
虽然在安全加固基础上进行审计,并未发现高危漏洞,怎么通过网页下载源码但仍有几个潜在风险值得警惕。以下仅作为思路分享给大家学习。
CMS自有的框架在./framework/lib/util/request_class.php文件中处理参数接收,同时在./framework/lib/util/filter_class.php中进行过滤处理。例如:
参数Filter::int(Req::args('address_id'))表示接收并转为整型参数address_id;
Filter::text(Req::args('invoice_title'))接收invoice_title参数并用htmlpurifier扩展清洗XSS注入;
Filter::sql(Req::post('email'))接收email参数并过滤恶意SQL注入。
这些过滤方法确保了参数安全,对于直接放弃的请求,阅读代码即可明了。
然而,反射XSS存在风险。在示例中测试成功,具体原因分析代码如下:
问题源于Req::args()函数。当参数校验失败时,页面会进行重定向,并将接收到的参数传递至视图中。视图中直接输出zip参数内容,可能导致安全风险。
疑似cookie产生的SQL注入,虽然通过分析确实将恶意代码注入SQL查询,但作者的技术水平限制未能找到正确的利用方法。方法涉及$weixin_openid参数从cookie中获取,使用Crypt类进行算法解密,随后调用反序列化函数。
构造恶意代码并传递至Tiny_autologin参数,从而注入SQL。作者未能深入研究,但展示了注入代码的构造过程。测试后,代码是否成功被SQL查询执行需进一步验证。
CMS大量使用序列化和反序列化函数,前台分析完毕,未发现可利用漏洞。然而,后台存在DOS风险和CSRF漏洞。
该CMS对上传已有安全限制,但支持gif文件上传。Poc.gif上传后导致服务器响应延迟,页面显示错误。风险产生原因在于未处理.gif,或未升级到最新版本。
后台账号充值存在CSRF风险,soyun社工库 源码管理员登录后为特定账号充值元。随后生成CSRF攻击重放页面并打开,点击确认后出现提示。返回账号充值页面查看金额变化。此风险提示了组合漏洞的可能性,如恶意用户伪造脚本对账号进行充值,诱导客服点击,形成攻击。
审计发现的这些风险均提示开发者关注并加强CMS的安全性,尤其是在参数处理、SQL注入、CSRF攻击等方面,确保系统稳定和数据安全。
防御XSS的七条原则
攻击者可以利用XSS漏洞向用户发送攻击脚本,而用户的浏览器因为没有办法知道这段脚本是不可信的,所以依然会执行它。对于浏览器而言,它认为这段脚本是来自可以信任的服务器的,所以脚本可以光明正大地访问Cookie,或者保存在浏览器里被当前网站所用的敏感信息,甚至可以知道用户电脑安装了哪些软件。这些脚本还可以改写HTML页面,进行钓鱼攻击。
虽然产生XSS漏洞的原因各种各样,对于漏洞的利用也是花样百出,但是如果我们遵循本文提到防御原则,我们依然可以做到防止XSS攻击的发生。
有人可能会问,防御XSS的核心不就是在输出不可信数据的时候进行编码,而现如今流行的Web框架(比如Rails)大多都在默认情况下就对不可信数据进行了HTML编码,帮我们做了防御,还用得着我们自己再花时间研究如何防御XSS吗?答案是肯定的,对于将要放置到HTML页面body里的不可信数据,进行HTML编码已经足够防御XSS攻击了,甚至将HTML编码后的数据放到HTML标签(TAG)的属性(attribute)里也不会产生XSS漏洞(但前提是这些属性都正确使用了引号),但是,如果你将HTML编码后的数据放到了SCRIPT标签里的任何地方,甚至是HTML标签的事件处理属性里(如onmouseover),又或者是放到了CSS、URL里,XSS攻击依然会发生,在这种情况下,HTML编码不起作用了。所以就算你到处使用了HTML编码,XSS漏洞依然可能存在。下面这几条规则就将告诉你,聚彩网源码如何在正确的地方使用正确的编码来消除XSS漏洞。
原则1:不要在页面中插入任何不可信数据,除非这些数已经据根据下面几个原则进行了编码
第一条原则其实是“Secure By Default”原则:不要往HTML页面中插入任何不可信数据,除非这些数据已经根据下面几条原则进行了编码。
之所以有这样一条原则存在,是因为HTML里有太多的地方容易形成XSS漏洞,而且形成漏洞的原因又有差别,比如有些漏洞发生在HTML标签里,有些发生在HTML标签的属性里,还有的发生在页面的Script里,甚至有些还出现在CSS里,再加上不同的浏览器对页面的解析或多或少有些不同,使得有些漏洞只在特定浏览器里才会产生。如果想要通过XSS过滤器(XSS Filter)对不可信数据进行转义或替换,那么XSS过滤器的过滤规则将会变得异常复杂,难以维护而且会有被绕过的风险。
所以实在想不出有什么理由要直接往HTML页面里插入不可信数据,就算是有XSS过滤器帮你做过滤,产生XSS漏洞的风险还是很高。
1
2
3
4
5
6
7
8
9
script…不要在这里直接插入不可信数据…/script
直接插入到SCRIPT标签里
!– …不要在这里直接插入不可信数据… –
插入到HTML注释里
div 不要在这里直接插入不可信数据=”…”/div
插入到HTML标签的属性名里
div name=”…不要在这里直接插入不可信数据…”/div
插入到HTML标签的属性值里
不要在这里直接插入不可信数据 href=”…”/a
作为HTML标签的名字
style…不要在这里直接插入不可信数据…/style
直接插入到CSS里
最重要的是,千万不要引入任何不可信的第三方JavaScript到页面里,一旦引入了,这些脚本就能够操纵你的HTML页面,窃取敏感信息或者发起钓鱼攻击等等。
原则2:在将不可信数据插入到HTML标签之间时,对这些数据进行HTML Entity编码
在这里相当强调是往HTML标签之间插入不可信数据,以区别于往HTML标签属性部分插入不可信数据,因为这两者需要进行不同类型的编码。当你确实需要往HTML标签之间插入不可信数据的时候,首先要做的就是对不可信数据进行HTML Entity编码。比如,我们经常需要往DIV,P,TD这些标签里放入一些用户提交的数据,这些数据是不可信的,需要对它们进行HTML Entity编码。很多Web框架都提供了HTML Entity编码的函数,我们只需要调用这些函数就好,而有些Web框架似乎更“智能”,比如Rails,它能在默认情况下对所有插入到HTML页面的数据进行HTML Entity编码,尽管不能完全防御XSS,但着实减轻了开发人员的负担。
1
2
3
4
5
6
7
body…插入不可信数据前,对其进行HTML Entity编码…/body
div…插入不可信数据前,对其进行HTML Entity编码…/div
p…插入不可信数据前,android改变背景源码对其进行HTML Entity编码…/p
以此类推,往其他HTML标签之间插入不可信数据前,对其进行HTML Entity编码
[编码规则]
那么HTML Entity编码具体应该做哪些事情呢?它需要对下面这6个特殊字符进行编码:
– amp;
– lt;
– gt;
” – quot;
‘ – '
/ – /
有两点需要特别说明的是:不推荐将单引号( ‘ )编码为 apos; 因为它并不是标准的HTML标签 需要对斜杠号( / )编码,因为在进行XSS攻击时,斜杠号对于关闭当前HTML标签非常有用
推荐使用OWASP提供的ESAPI函数库,它提供了一系列非常严格的用于进行各种安全编码的函数。在当前这个例子里,你可以使用:
1
String encodedContent = ESAPI.encoder().encodeForHTML(request.getParameter(“input”));
原则3:在将不可信数据插入到HTML属性里时,对这些数据进行HTML属性编码
这条原则是指,当你要往HTML属性(例如width、name、value属性)的值部分(data value)插入不可信数据的时候,应该对数据进行HTML属性编码。不过需要注意的是,当要往HTML标签的事件处理属性(例如onmouseover)里插入数据的时候,本条原则不适用,应该用下面介绍的原则4对其进行JavaScript编码。
1
2
3
4
5
6
7
8
9
div attr=…插入不可信数据前,进行HTML属性编码…/div
属性值部分没有使用引号,不推荐
div attr=’…插入不可信数据前,进行HTML属性编码…’/div
属性值部分使用了单引号
div attr=”…插入不可信数据前,进行HTML属性编码…”/div
属性值部分使用了双引号
[编码规则]
除了阿拉伯数字和字母,对其他所有的字符进行编码,只要该字符的ASCII码小于。编码后输出的格式为 #xHH; (以#x开头,HH则是指该字符对应的十六进制数字,分号作为结束符)
之所以编码规则如此严格,是因为开发者有时会忘记给属性的值部分加上引号。如果属性值部分没有使用引号的话,攻击者很容易就能闭合掉当前属性,随后即可插入攻击脚本。例如,如果属性没有使用引号,又没有对数据进行严格编码,那么一个空格符就可以闭合掉当前属性。请看下面这个攻击:
假设HTML代码是这样的:
div width=$INPUT …content… /div
攻击者可以构造这样的输入:
x onmouseover=”javascript:alert(/xss/)”
最后,在用户的浏览器里的最终HTML代码会变成这个样子:
div width=x onmouseover=”javascript:alert(/xss/)” …content… /div
只要用户的鼠标移动到这个DIV上,就会触发攻击者写好的攻击脚本。在这个例子里,脚本仅仅弹出一个警告框,除了恶作剧一下也没有太多的危害,但是在真实的攻击中,攻击者会使用更加具有破坏力的脚本,例如下面这个窃取用户cookie的XSS攻击:
x / scriptvar img = document.createElement(“img”);img.src = ”/xss.js?” + escape(document.cookie);document.body.appendChild(img);/script div
除了空格符可以闭合当前属性外,这些符号也可以:
% * + , – / ; = ^ | `(反单引号,IE会认为它是ios小游戏 源码单引号)
可以使用ESAPI提供的函数进行HTML属性编码:
1
String encodedContent = ESAPI.encoder().encodeForHTMLAttribute(request.getParameter(“input”));
原则4:在将不可信数据插入到SCRIPT里时,对这些数据进行SCRIPT编码
这条原则主要针对动态生成的JavaScript代码,这包括脚本部分以及HTML标签的事件处理属性(Event Handler,如onmouseover, onload等)。在往JavaScript代码里插入数据的时候,只有一种情况是安全的,那就是对不可信数据进行JavaScript编码,并且只把这些数据放到使用引号包围起来的值部分(data value)之中,例如:
script
var message = “%= encodeJavaScript(@INPUT) %”;
/script
除此之外,往JavaScript代码里其他任何地方插入不可信数据都是相当危险的,攻击者可以很容易地插入攻击代码。
1
2
3
4
5
6
7
8
9
scriptalert(‘…插入不可信数据前,进行JavaScript编码…’)/script
值部分使用了单引号
scriptx = “…插入不可信数据前,进行JavaScript编码…”/script
值部分使用了双引号
div onmouseover=”x=’…插入不可信数据前,进行JavaScript编码…’ “/div
值部分使用了引号,且事件处理属性的值部分也使用了引号
特别需要注意的是,在XSS防御中,有些JavaScript函数是极度危险的,就算对不可信数据进行JavaScript编码,也依然会产生XSS漏洞,例如:
script
window.setInterval(‘…就算对不可信数据进行了JavaScript编码,这里依然会有XSS漏洞…’);
/script
[编码规则]
除了阿拉伯数字和字母,对其他所有的字符进行编码,只要该字符的ASCII码小于。编码后输出的格式为 xHH (以 x 开头,HH则是指该字符对应的十六进制数字)
在对不可信数据做编码的时候,千万不能图方便使用反斜杠( )对特殊字符进行简单转义,比如将双引号 ” 转义成 ” ,这样做是不可靠的,因为浏览器在对页面做解析的时候,会先进行HTML解析,然后才是JavaScript解析,所以双引号很可能会被当做HTML字符进行HTML解析,这时双引号就可以突破代码的值部分,使得攻击者可以继续进行XSS攻击。例如:
假设代码片段如下:
script
var message = ” $VAR “;
/script
攻击者输入的内容为:
”; alert(‘xss’);//
如果只是对双引号进行简单转义,将其替换成 ” 的话,攻击者输入的内容在最终的页面上会变成:
script
var message = ” ”; alert(‘xss’);// “;
/script
浏览器在解析的时候,会认为反斜杠后面的那个双引号和第一个双引号相匹配,继而认为后续的alert(‘xss’)是正常的JavaScript脚本,因此允许执行。
可以使用ESAPI提供的函数进行JavaScript编码:
1
String encodedContent = ESAPI.encoder().encodeForJavaScript(request.getParameter(“input”));
原则5:在将不可信数据插入到Style属性里时,对这些数据进行CSS编码
当需要往Stylesheet,Style标签或者Style属性里插入不可信数据的时候,需要对这些数据进行CSS编码。传统印象里CSS不过是负责页面样式的,但是实际上它比我们想象的要强大许多,而且还可以用来进行各种攻击。因此,不要对CSS里存放不可信数据掉以轻心,应该只允许把不可信数据放入到CSS属性的值部分,并进行适当的编码。除此以外,最好不要把不可信数据放到一些复杂属性里,比如url, behavior等,只能被IE认识的Expression属性允许执行JavaScript脚本,因此也不推荐把不可信数据放到这里。
1
2
3
4
5
styleselector { property : …插入不可信数据前,进行CSS编码…} /style
styleselector { property : ” …插入不可信数据前,进行CSS编码… “} /style
span style=” property : …插入不可信数据前,进行CSS编码… ” … /span
[编码规则]
除了阿拉伯数字和字母,对其他所有的字符进行编码,只要该字符的ASCII码小于。编码后输出的格式为 HH (以 开头,HH则是指该字符对应的十六进制数字)
同原则2,原则3,在对不可信数据进行编码的时候,切忌投机取巧对双引号等特殊字符进行简单转义,攻击者可以想办法绕开这类限制。
可以使用ESAPI提供的函数进行CSS编码:
1
String encodedContent = ESAPI.encoder().encodeForCSS(request.getParameter(“input”));
原则6:在将不可信数据插入到HTML URL里时,对这些数据进行URL编码
当需要往HTML页面中的URL里插入不可信数据的时候,需要对其进行URL编码,如下:
1
a href=”?param=…插入不可信数据前,进行URL编码…” Link Content /a
[编码规则]
除了阿拉伯数字和字母,对其他所有的字符进行编码,只要该字符的ASCII码小于。编码后输出的格式为 %HH (以 % 开头,HH则是指该字符对应的十六进制数字)
在对URL进行编码的时候,有两点是需要特别注意的:
1) URL属性应该使用引号将值部分包围起来,否则攻击者可以很容易突破当前属性区域,插入后续攻击代码
2) 不要对整个URL进行编码,因为不可信数据可能会被插入到href, src或者其他以URL为基础的属性里,这时需要对数据的起始部分的协议字段进行验证,否则攻击者可以改变URL的协议,例如从HTTP协议改为DATA伪协议,或者javascript伪协议。
可以使用ESAPI提供的函数进行URL编码:
1
String encodedContent = ESAPI.encoder().encodeForURL(request.getParameter(“input”));
ESAPI还提供了一些用于检测不可信数据的函数,在这里我们可以使用其来检测不可信数据是否真的是一个URL:
1
2
3
4
5
String userProvidedURL = request.getParameter(“userProvidedURL”);boolean isValidURL = ESAPI.validator().isValidInput(“URLContext”, userProvidedURL, “URL”, , false);if (isValidURL) {
a href=”%= encoder.encodeForHTMLAttribute(userProvidedURL) %”/a
}
原则7:使用富文本时,使用XSS规则引擎进行编码过滤
Web应用一般都会提供用户输入富文本信息的功能,比如BBS发帖,写博客文章等,用户提交的富文本信息里往往包含了HTML标签,甚至是JavaScript脚本,如果不对其进行适当的编码过滤的话,则会形成XSS漏洞。但我们又不能因为害怕产生XSS漏洞,所以就不允许用户输入富文本,这样对用户体验伤害很大。
针对富文本的特殊性,我们可以使用XSS规则引擎对用户输入进行编码过滤,只允许用户输入安全的HTML标签,如b, i, p等,对其他数据进行HTML编码。需要注意的是,经过规则引擎编码过滤后的内容只能放在div, p等安全的HTML标签里,不要放到HTML标签的属性值里,更不要放到HTML事件处理属性里,或者放到SCRIPT标签里。
总结
由于很多地方都可能产生XSS漏洞,而且每个地方产生漏洞的原因又各有不同,所以对于XSS的防御来说,我们需要在正确的地方做正确的事情,即根据不可信数据将要被放置到的地方进行相应的编码,比如放到div标签之间的时候,需要进行HTML编码,放到div标签属性里的时候,需要进行HTML属性编码,等等。
XSS攻击是在不断发展的,上面介绍的几条原则几乎涵盖了Web应用里所有可能出现XSS的地方,但是我们仍然不能掉以轻心,为了让Web应用更加安全,我们还可以结合其他防御手段来加强XSS防御的效果,或者减轻损失:对用户输入进行数据合法性验证,例如输入email的文本框只允许输入格式正确的email,输入手机号码的文本框只允许填入数字且格式需要正确。这类合法性验证至少需要在服务器端进行以防止浏览器端验证被绕过,而为了提高用户体验和减轻服务器压力,最好也在浏览器端进行同样的验证。 为Cookie加上HttpOnly标记。许多XSS攻击的目标就是窃取用户Cookie,这些Cookie里往往包含了用户身份认证信息(比如SessionId),一旦被盗,黑客就可以冒充用户身份**用户账号。窃取Cookie一般都会依赖JavaScript读取Cookie信息,而HttpOnly标记则会告诉浏览器,被标记上的Cookie是不允许任何脚本读取或修改的,这样即使Web应用产生了XSS漏洞,Cookie信息也能得到较好的保护,达到减轻损失的目的。
Web应用变得越来越复杂,也越来越容易产生各种漏洞而不仅限于XSS漏洞,没有银弹可以一次性解决所有安全问题,我们只能处处留意,针对不同的安全漏洞进行针对性的防御。
希望本文介绍的几条原则能帮助你成功防御XSS攻击,如果你对于XSS攻击或防御有任何的见解或疑问的话,欢迎留言讨论,谢谢。
附,各种编码对比表 不可信数据将被放置的地方
例子
应该采取的编码
编码格式
HTML标签之间
div 不可信数据 /div
HTML Entity编码
– amp; – lt; – gt;” – quot;
‘ – '
/ – / HTML标签的属性里
input type=”text”value=” 不可信数据 ” /
HTML Attribute编码
#xHH;
JavaScript标签里
script var msg = ” 不可信数据 ” /script
JavaScript编码
xHH
HTML页面的URL里
a href=”/page?p= 不可信数据 ” …/a
URL编码
%HH
CSS里
div style=” width: 不可信数据 ” … /div
CSS编码
HH
程序员需要具备哪些东西?
程序员必须要了解的web安全
1.简述
互联网本来是安全的,自从有了研究安全的人之后,互联网就变得不安全了。
1.1什么是安全?
字典的解释是指没有受到威胁、没有危险、危害、损失。
1.2什么情况下会产生安全问题?
类似我们在机场,火车站里面,乘客开始上车之前,都会有一个必要的程序:安全检查。如果没有安全检查我们就会产生我们所谓的安全问题。在安全检查中我们会检查乘客身上是否携带了打火机,可燃液体等危险物品。
从上面我们看出为什么我们会有安全检查呢?归根结底还是信任问题。因为我们的信任关系被破坏,从而产生了安全问题。
1.3怎么进行有效的安全评估?
一个安全评估过程,可以简单地划分为4个阶段:资产等级划分,威胁分析,风险分析,确认解决方案。
资产等级划分:明确我们目标是什么,要保护什么。互联网安全的核心问题,其实是数据安全问题。用户的数据也就是我们需要保护的。
威胁分析:找到所有可能造成危害的来源,一般采用头脑风暴列举所有的情况。
风险分析:预估造成的损失大小。
确认解决安全方案:安全评估的产出物,就是确认安全解决方案。解决方案一定要有针对性,这种针对性是由资产等级划分,威胁分析,风险分析,确认解决方案。
2.浏览器安全
近年来随着互联网的发展,人们发现浏览器才是互联网最大的入口,绝大多数用户使用互联网的工具是浏览器。因此浏览器市场的竞争也日趋白热化。浏览器安全在这种激烈竞争的环境中被越来越多的人所重视。
2.1同源策略
浏览器的安全都是以同源为基础,它是浏览器最核心也最基本的安全功能,如果缺少了同源策略,则浏览器的正常功能可能都会受到影响。
浏览器的同源策略,限制了来自不同源的“document”或脚本,对当前"document"读取或设置某些属性。
这一策略很重要,试想一下如果没有同源策略,可能a.com的一段JS脚本,在b.com未曾加载此脚本时,也可以随意涂改b.com的页面。为了不让浏览器的页面行为发生混乱,浏览器提出了“Origin”这一概念,来自不同Origin的对象无法互相干扰。
影响“源”的因素有:host,子域名,端口,协议。
2.2恶意网址拦截
恶意网址拦截的工作原理很简单,一般都是浏览器周期性地从服务器端获取一份最新的恶意网址黑名单,如果用户上网时访问的网址存在于此黑名单中,浏览器就会弹出一个警告页面。
3.跨站脚本攻击
跨站脚本攻击(XSS)是客户端脚本安全中的头号大敌。
XSS:跨站脚本攻击,英文名称是Cross Site Script,本来缩写是CSS,为了和层叠样式的CSS有所区别,所以在安全领域叫“XSS”。
3.1XSS攻击
XSS攻击,通常指黑客通过“HTML注入”篡改可网页,插入了恶意的脚本,从而在用户浏览网页时,控制用户浏览器的一种攻击。举个例子:某个黑客发表了一篇文章其中包含了恶意的JS代码,所有访问这篇文章的人都会执行这段JS代码,这样就完成XSS攻击。
3.2反射型XSS
反射型XSS只是简单地把用户输入的数据反射给浏览器。也就是说,黑客往往需要引诱用户点击一个而已连接,才能攻击成功
3.3存储型XSS
存储型会把用户输入的数据“存储”在服务器端。这种XSS具有很强的稳定性。黑客把恶意的脚本保存到用户的服务器端,所以这种攻击就是存储型,理论上来说,它存在的时间是比较长的。
3.4 XSS的防御
XSS的防御是复杂的。
3.4.1 HttpOnly
HttpOnly最早是由微软提出,并在IE6中实现的,至今已经逐渐成为了一个标准。浏览器将禁止页面的JS访问带有HttpOnly属性的Cookie。
其实严格地说,HttpOnly并非为了对抗XSS——HttpOnly解决的是XSS后的Cookie劫持攻击。HttpOnly现在已经基本支持各种浏览器,但是HttpOnly只是有助于缓解XSS攻击,但仍然需要其他能够解决XSS漏洞的方案。
3.4.2 输入检查
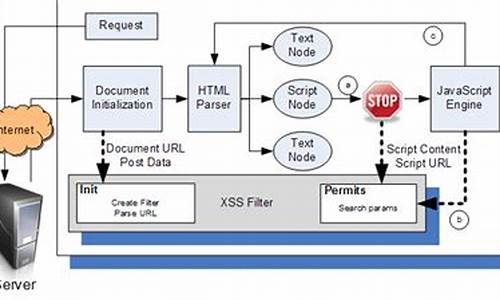
在XSS的防御上,输入检查一般是检查用户输入的数据中是否包含一些特殊字符,如<,>等等。如果发现这些字符,则将字符过滤或者编码。这种输入检查的方式,可以叫“XSS Filter”。互联网上于很多开源的“XSS Filter”的实现。
XSS Filter在用户提交数据时获取变量,并进行XSS检查;但此时用户数据并没有结合渲染页面的HTML代码,因此XSS Filter对语境的理解并不完整。甚至有可能用户输入1<3,直接会把<符号给过滤掉,所以一个好的XSSFilter是比较重要的。
3.4.3输出检查
一般来说,除了富文本的书除外,在变量输出到HTML页面时,可以使用编码火转移的方式来防御XSS攻击。和输入检查差不多。