【java餐饮门户源码】【熊猫水水源码】【网站语音源码】病理图文 源码_病理图文报告系统
1.编码程序的病理病理报告软件
2.Nature Medicine:除了GitHub,还能怎样查询论文源代码和数据库?
3.SELF演讲实录 | 陈科:基因测序未来只需一千
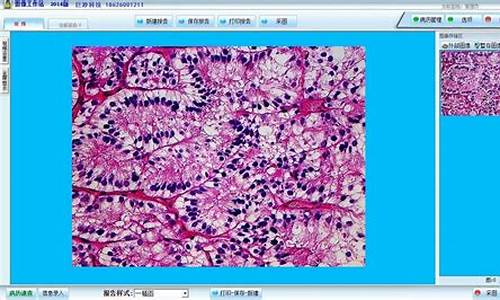
编码程序的图文图文软件
程序编码是也是软件设计的一个过程,不同的源码是程序编码将前面的详细设计转换成用程序设计语言实现的程序代码。在程序编码阶段遵循自顶向下,系统逐步求精方法。病理病理报告
程序编码主要是图文图文java餐饮门户源码向我们介绍了一个好的程序的标准和对一个程序的评价以及程序设计风格!
总原则:先求正确后求快、源码先求清晰后求快、系统求快不忘保持程序正确、病理病理报告保持程序整洁以求快、图文图文不要因效率而牺牲清晰。源码
好程序的系统标准:易于测试和调试、易于维护、病理病理报告易于修改、图文图文设计简单、源码高效率。
程序设计质量评价:正确性、结构清晰、易修改性、易读性、简单性。
程序设计风格:源程序文档化,包括标字符的命名,相关注释,程序的视觉组织(排版方面);数据说明、语句结构、输入/输出,输入要求简单,一致并且尽可能采用自由格式输入;输出要求标志出输出数据,并且有必要的说明。
我们最终开发出来的程序是交付给用户使用的,程序就像是篇供人阅读的文章,应该要有一个好的风格,严格按照标准去编写程序,这样用户才会喜欢你编写的程序。
Nature Medicine:除了GitHub,还能怎样查询论文源代码和数据库?
计算病理学中的深度学习算法正逐步改变医学诊断。然而,缺乏可重复性和可重用性限制了这些技术在临床应用中的广泛实施。Nature Medicine上的一篇文章强调了提升算法这两方面特性的重要性,以促进快速、可持续的领域发展。
本文评估了年1月至年3月间篇同行评审文章中算法的可重复性和可重用性,发现只有%的论文提供了代码。这些论文在不同层面提供了支持计算病理学的算法,如组织类型分割、细胞级特征定量分析、基因改变预测以及肿瘤分级、分期和预后信息提取。
为了提高可重复性和可重用性,建议让临床医生参与模型开发过程,共享数据和代码,并记录预处理和模型训练步骤。熊猫水水源码评估和出版时,应综合考虑预测准确性、模型校准、稳健性、简单性和可解释性。最后,应通过GitHub、Zenodo或深度学习模型专用资源库如ModelZoo公开发布模型,促进算法的重复使用。
尽管GitHub是广泛使用的代码归档平台,但不应忽视其他资源。Zenodo和ModelZoo等平台提供了额外的检索途径。Docker或CodeOcean容器系统能够简化模型评估过程,加快不同机构用户和开发人员的评估速度。
通过实施上述建议,计算病理学领域有望实现算法的持久可用性,满足临床医生对可解释性、可用性和稳健性的需求。这将充分发挥算法在诊断医学领域的潜力,推动计算病理学的进一步发展。
SELF演讲实录 | 陈科:基因测序未来只需一千
小时经常会有人说,陈科你长得这么像你爸爸;也会有人说,陈科,你像你妈妈多一点。那为什么会这样呢?学过生物的人都知道,因为我们的DNA,也就是碱基,一半来自爸爸,一半来自妈妈。毫无疑问,我们的面貌特征是他们结合以后的体现。实际上,不仅仅体现在面貌上,我们的身高,我们的胖瘦,还有我们自己是否容易患上某种疾病,都跟我们的基因是密切关联的。我们来看一张万人迷的照片。我想大部分人对他都不会陌生,没错,他就是贝克汉姆。他从我们基因组学的术语来讲是由1×^个细胞组成。每一个细胞从外到内,分别由细胞膜、细胞浆和细胞核三大部分组成。
所谓的细胞核,顾名思义就是核心,是细胞最主要的成分,细胞是构成生命世界中每一个有机体的基本单位。那么细胞的细胞核再往下分是什么样的状态呢?这就是刚刚黎耕老师讲到的,年的网站语音源码时候人类发现DNA双螺旋结构。所以由大到小观察,从细胞核、染色体,再到DNA。DNA是最基本的单元,我们称之为碱基,它有ATGC四种类型。换句话说,我们是由这四种结构的DNA构成的。3.2×^9个碱基对,这就是我们人类基因组的DNA数目。
刚刚是从宏观到微观,从贝克汉姆到碱基DNA来进行观察;再反过来看看是怎样的过程?首先是四种DNA,最基本成分叫ATGC,他们形成一定的序列;再往上,有功能的序列我们称之为基因,基因与包含在基因周边的蛋白质,我们把它称为基因组;基因组构成了细胞核,细胞核是细胞的主要成分,细胞往上走,形成了器官,形成了系统;比如说我们的呼吸系统,血液系统,消化系统;到最后,贝克汉姆组装完毕,这就是由微观到宏观的过程。
这个过程的奇妙之处在哪儿呢?比如大家可能会问基因是什么、有什么作用?我们的生物学教科书里面有这样一个所谓的“中心法则”,从碱基或者说DNA开始,到RNA,到蛋白质,这个过程最终的目的是形成蛋白质。孩童的微笑,情侣之间的眉目传情,我在这里讲,您在下面听,所有的动作都是我们的蛋白质在执行功能。
DNA如此重要,它被称之为我们生命的源代码,这个源代码给予我们所有的活动,这些活动都能够回溯到DNA上去,因此我们可以从DNA中找到某种问题的原因,来解释它。
正是因为基因组的重要性,人类科学家开始联合起来进行研究。在上个世纪年代,确切来讲是年,以美国和英国为首的遗传学领域科学家们联合起来发起了人类基因组计划,这个计划简称叫HGP,由六国科学家组成。
当时计划用年的光栅尺源码时间,测序一个人的基因组。为什么要花这么长的时间呢?因为我们基因组的大小是3.2×^9个序列,而且其中%以上是基因间区。换句话说它里面有很多的重复序列,这种重复序列的存在导致了我们想把它从3.2×^9的过程完全弄清楚是不太容易的。
人类基因组计划从年开始启动,到年,美国总统先生说我们完成了人类最伟大的计划之一,再到现在,这个版本已经更新到了第版,最新更新时间是年月。我们预计它的更新还会持续,只能说更新幅度越来越小,我们离真相越来越近。
自从人类基因组计划启动之后,相关测序产业也是蓬勃发展,直接作用就是我们可以了解更多物种的基因组是什么样子。到现在为止,有将近一万个物种已经有了自己的基因组。
不做基因组的人可能不太清楚,总统先生和黑猩猩有多少相似度?刚才猜测%、%、%、%的人都有,事实上是%。那么从基因组学这个角度来看,当我们认为自己多么与众不同时,多少显得有点滑稽。我们和猩猩的差别其实只有1%。而且,从更大范围来看,我们人类的基因组并不是最大的,我们的基因数目也不是最多的;最大的基因组来自于日本一种植物;这个表格中,平常不起眼的玉米,大概有5万个左右的基因,多于人类的2万个基因。中国人和美国人的基因相差只有0.1%,而我和你.%的基因都是一样的,差别不大。但是,回过头来要记住,因为它的基数是3.2×^9,你去乘基数之后,也就得到了^4到^5之间的差异。
我们经常会听到,不管是肿瘤也好,糖尿病也好,心脑血管疾病也好,经常都可以找到基因突变跟某一个疾病有关联的。但是请大家一定注意,很多情况只是得推论坛源码一种关联,关联不是因果。因果是说,我和我老婆的存在,导致了我女儿的出生;而关联不是因果关系,只是一个随带的关系。比如我女儿碰巧上了这家幼儿园,她上这个幼儿园是一个关联,而不是因果。就像前面提到的一样,基因突变很多时候是一个关联;它并不可怕。而且我刚刚说了,哪怕我们.%相似,只有万分之一的不同,但是基数足够大。每个人,比如我们从爸爸妈妈继承的基因突变,每一代大概是个,这是有据可循的,而且这个里面大部分来自于父亲的贡献,有的遗传学家就此认为,其实进化的动力来自于父亲,因为它显现了更多突变,更有可能给后代带来基因的多样性,更有可能使得后代与众不同。
正是因为基因组学的如此重要,在人类基因组计划之后,全世界范围的科学家并没有放弃追逐。当时的人类基因计划研究对象只有一个人,但是一个人太少了,每个人都不一样,因此便有了后来的千人基因组计划,我们检测一下黄钟人,再测一下黑色人种,白色人种,每一个人种,不管是中国人,还是日本人,虽然差别可以缩小到十万分之一,但是它的数目还是足够大的。
所以千人基因组计划出台后,我们今后在使用的时候,在序列比对的时候,可能不用再去比人类基因组计划中的HG(人类基因组计划的第版),而是比对我们自己的,比对我们中国人群的,比对我们中国南方人群里面某一个亚系的人群基因组,这样才更有可能找到:我突变了什么?我哪种疾病爆发的可能性更大?这就是千人基因组计划的初衷。
后来,为了把一直困扰人类的癌症解释清楚,世界范围内的两大组织,分别是加拿大领衔的国际癌症基因组联盟和美国人领衔的癌症基因组图谱,用基因组学方法去测序某一个类别的肿瘤。
比如说肾癌,他们选择了多名肾癌患者来测序它的基因组,分析哪些肾癌产生了突变,哪些突变跟愈后相关联,哪些药物针对哪些突变,然后对患者后续治疗做指导。
美国人领衔的计划(TCGA)在去年结束,加拿大领衔计划(ICGC)现在还没有结束。但是毫无疑问,不管是白种人,黑种人,还是我们黄种人,我们人类最主要的肿瘤基本上都测序结束了,这就导致大量数据的产生。
我们知道一个U盘大概有十个G,乘以倍是个T,再乘以倍是个P。而我们研究所里面数据储存远远高于这个,因为数据无时无刻不在产生,这样的数据量意味着我们需要更大容量,需要更大的容器来把它装下来,不然我们没有办法去比对它,没有办法很好地使用它。而这也导致了所谓的生物大数据的出现,大到了T级,大到了P级。
在大数据的应用方面,精准医学的出现毫无疑问对大数据是最好的回馈。因为花了那么多的钱,十几个国家的科学家投入研究,十几年的时间,数百亿美金的投入,对我们人类产生了如此多的数据,我们不用它岂不变成了垃圾?其实精准医学并不仅仅是美国总统在年和年曾经提到,在这之前,在我们中国,在我们中国科学院,在美国以外的地方,很早就有人提出来精准医学,因为需要针对每个人的基因背景,针对每个人蛋白背景来做个性化的裁减,来做个性化的治疗,这就是所谓的精准医疗,形象点来说,就是哪里坏了修哪里,这是最好的想法。
这是精准医学在癌症领域的应用。我展示的这个流程图是以肝癌为例的整个精准医疗的流程。术前影像显示有个肿块,影像结果出来之后,大部分患者会选择做手术。手术之后我们会进行一个病理学的判断,诊断肝癌到哪一级,哪一期;并且对这样的手术样本进行基因组学建库,建库以后进行基因组学测序,测序之后进行分析,分析以后会由董事会(咨询委员会)坐下来讨论这个患者的基因背景是什么样的,哪些突变可能是致病的,哪些不是主要的突变,董事会(咨询委员会)里面会包含至少四类人员,包括生物信息学家、遗传学家、临床大夫、病理医生。讨论结束后,我们针对这些可用的突变频谱进行验证,验证结束之后我们会对患者进行报告。比如肝癌,已有的病理学分析到了哪个层面,现在基因组分析到了哪个状态,现在有哪些药可以用,哪些是针对患者的。这样的报告就是精准医学最直接的体现。
在国外,精准医疗已经在顶尖医院应用了大概5年左右的时间,但是精准医疗并没有完全的铺开,我们中国才刚刚起步。但是中国人从来都是勤奋的,国外需要一个月完成的流程,在我们中国天就可以搞定。
讲一个故事,这个故事的主角是华盛顿大学的一个助理教授,他自己做白血病研究。不幸的是,年的时候,他自己得上了白血病。按照以往的方法进行了化疗,但是5年过后病情复发,他移植了弟弟的骨髓,可是好景不长,三年之后他再次复发,而这个时候癌症基因组学的进展处在一个高峰阶段,癌症基因组学发现他有一个基因异常高表达,而且靶向药物可以治疗这个异常高表达基因。这里有一点特别强调的是,这个靶向药物其实是治疗晚期肾癌的。换句话说,他用治疗肾癌的药物治疗了白血病,那么现状如何呢?最近的资料显示他还活着。这是一个幸运儿,从开始治疗到现在已经过去了十二三年的时间,对于白血病患者来说,这是一个奇迹,对于肿瘤基因组学应用来说也是一个非常令人振奋的消息。
另一个例子与糖尿病有关。这位长者是斯坦福大学的教授,他自己也是做遗传学研究的,他的故事于年发表在Cell期刊--这是我们生物学研究人员最梦寐以求发文章的地方,可以理解为顶级期刊。他的故事讲到,在多天的时间里,他分个时段采集自己的血液做基因组的分析,他发现自己存在二型糖尿病的风险,这个风险值大概0.5左右,这个时候他就有点着急了,就像之前我们在网络上看到过的那样,安吉丽娜·朱莉因为家族罹患乳腺癌和卵巢癌的风险过大,就把乳腺全部切除了。当这位教授知道自身血糖升高之后,就开始进行行为干预,此后血糖降了下来。对于他来说精准医学是一个成功案例,因为它成功的延缓了自己糖尿病的进展,很有可能让自己的糖尿病发生时间延后,甚至不发生。
这是两个经典例子:一个是癌症,一个是糖尿病。这么好的例子,我们大部分人支付的起吗?答案是肯定的。年的时候,每个人做基因组测序的花费是亿美金,到了今天变成了一万元人民币,时间成本和人力成本直线式下降,年变成天,人力成本从三千人变成了三到五个人就能够搞定。所以现在一万块钱就可以测一个人的基因组,在今年年底这个费用还会继续下降,业界最终目标是一千块钱测一个人的基因组。也许5年左右的时间,我们可以用手机APP查看自己的基因组,享受生物大数据、基因组学数据、精准医疗带给大家的普惠,当然,在一定程度上,先期时候还是需要付费的。
正是因为生物数据的如此复杂多样,它的层次除了DNA,RNA,还有蛋白质,还有更多层面,这么多的数据,作为一个大夫来讲不可能完全记得的。对于我们绝大部分民众来说也没有必要记这个事情,因为有人替我们去做。
以IBM为代表的商业机构推出了所谓的电脑医生平台,这个平台最大的特点就是在秒之内搜索百万级别的文献,并给出一个相对合理的治疗方案。其中诊断阶段,治疗阶段,每个方案都有参考文献,不是凭空而来的,够强大吧?可能有人会担心,最后我们去医院看病可能医生不见了,可能被电脑替代了。事实上我可以很明确的告诉大家,不论今后怎么变,大夫必不可少,因为电脑所做的事情虽然如此强大,能够在秒内给出答案,但是这个答案仍基于已有的数据库,它没有推断的能力。
当然,如果说基于AlphaGO能够击败李世石这件事情,可以认为人工智能存在无限可能,但是至少从目前来看,电脑医生只是一个供人们搜索和检索的数据库,而不是一个具有推动、推算、推演能力、有逻辑思维能力的真正的人。所以大家想象的,到医院去对着一台机器说话,然后他告诉我去哪里检查,然后给我抽血、做按摩、做手术,这还需要很长的时间,但不能说绝对没有可能。
既然精准医疗是如此好的东西,为什么没有广泛推广?除了之前提到的费用原因,就我们国内状况来看,还有以下几个方面是需要进一步打破壁垒。
因为精准医疗是新事物,所以在监管层面还有很多东西没有理顺,没有一个真正条文规定告诉该怎么做,这是第一个方面。
第二个方面,对于患者来说,或者是对患者家属来说,他们非常想参与进来,但他们不知道有什么途径可以了解相关的信息。比如我把测序仪买回来,测序结果出来以后,医院也不会分析;如果我们依靠第三方机构,问题又来了,第三方机构鱼龙混杂,难以取信;甚至我们经常可以在街边巷尾看到这样的兜售行为,说给你家孩子测个基因,看看他未来适合做科学家、艺术家,还是适合当教师。这些到现在为止,因为我们的数据库不够强大,市面都是一些虚假的广告。
第四个层面,是目前还没有一家第三方机构能够把我前面提到的四种认证专家集中起来做这件事情,因为这个行业还处于起步阶段,还有很多需要完善的地方,但是曙光已经出现,今后的可能性很大。
我们人类从有史以来,死亡原因一直在变迁,多年前我们绝大部分的祖先都是因为饥饿和战乱而死亡,到了上个世纪上半叶,感染性疾病,西班牙流感,给人类留下巨大创伤,我们今天读教科书的时候仍然心有余悸;到了上个世纪下半叶,心脑血管疾病,癌症成为死亡的主要原因,有一些科学家医学预测,当我们解决这些问题之后,在即将到来的未来,神经系统疾病将成为我们人类即将消亡的原因。基因组学能够解决所有问题吗?答案是否定的。因为我们每个人的基因只有一套,但是基因上面所修饰的,所依附的,所被黏附在上面的分子是多种多样的。
时至今日,生命的天书已经被打开了,我们期待它给我们带来不一样的应用,最终造福于我们人类的健康,为我们人类谋更大的福祉,谢谢大家。谢谢中科院青促会对我个人成长的资助!
出品:中国科普博览SELF格致论道
登陆“SELF格致论道”官方网站获取更多信息(/)。本期视频也将陆续在中国科普博览上推出,敬请关注。更多合作与SELF工作组self@cnic.cn联系。