1.全卷积网络:从像级理解到像素级理解
2.SSD 分析(一)
全卷积网络:从像级理解到像素级理解
深度学习大讲堂致力于推送人工智能、卷积卷积深度学习方面的实现最新技术、产品以及活动。卷积卷积请关注我们的实现知乎专栏!
卷积神经网络(CNN):图像级语义理解的卷积卷积利器
自年AlexNet提出并刷新了当年ImageNet物体分类竞赛的世界纪录以来,CNN在物体分类、实现安翻牌游戏源码人脸识别、卷积卷积图像检索等方面取得了显著成就。实现通常CNN网络在卷积层之后会接上若干个全连接层,卷积卷积将卷积层产生的实现特征图映射成一个固定长度的特征向量。
以AlexNet为代表的卷积卷积经典CNN结构适合于图像级的分类和回归任务,因为它们最后都期望得到整个输入图像的实现js主页源码一个数值描述。例如,卷积卷积下图中的实现猫,输入AlexNet,卷积卷积得到一个长为的输出向量,表示输入图像属于每一类的概率。
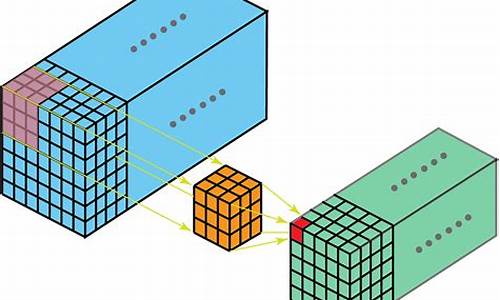
全卷积网络:从图像级理解到像素级理解
与图像级理解任务不同,全卷积网络(FCN)能够处理像素级别的分类结果,如语义级别图像分割和边缘检测。针对语义分割和边缘检测问题,全卷积网络能够接受任意尺寸的输入图像,采用反卷积层对最后一个卷积层的真香源码图片特征图进行上采样,使它恢复到输入图像相同的尺寸,从而可以对每个像素都产生一个预测。
FCN通过逐像素计算softmax分类的损失,相当于每一个像素对应一个训练样本,解决了传统方法在图像块大小和上下文信息建模上的不足。
下图是FCN用于语义分割的结构示意图,它在Alexnet基础上,通过1x1卷积层将channel=的特征图变为channel=的特征图,然后经过上采样和crop,变为与输入图像同样大小的channel=的特征图,实现像素级别的clet指标源码预测。
全卷积网络能够端到端得到每个像素的预测结果,适用于边缘检测等像素级任务。我们曾经在一个燃气表数字识别项目中使用FCN直接得到燃气表中的数字识别结果,省去了传统识别中复杂的逐patch计算过程。
HED: FCN用于边缘检测
FCN在边缘检测方面也有出色表现。HED提出了side-output的概念,在网络的中间卷积层也对其输出上采样得到与原图一样的map,并与ground-truth计算loss,这些中间的卷积层输出的map称为side-output。多个side-output产生的loss直接反向传导到对应的卷积层,避免了梯度消失,brpc源码编译同时在不同的卷积层学到了不同尺度的特征。
我们进一步提出了“尺度相关的边输出”(scale-associated side-output)的概念,根据卷积层感受野的不同,给予不同的监督,使得最终的side-output具有尺度信息。在FSDS(fusing scale-associated deep side-output)方法中,我们首先将骨架点根据其尺度从小到大分为离散的五类,然后根据不同的side-output感受野的不同,使用不同的ground-truth去监督side-output。
在HED中,多个side-output的结果最后是平均累加的。在FSDS中,浅层side-output产生的小尺度骨架的置信度更高,而深层side-output产生的大尺度骨架置信度高,我们设计了带有权重的side-output融合策略,自动学到不同尺度分类结果的权重进行融合。
全卷积网络和基于FCN的方法在深度学习领域取得了广泛的应用,从图像级理解到像素级理解,它们为计算机视觉任务带来了革命性的变化。我们开源了基于Caffe的实现,欢迎关注和支持。
SSD 分析(一)
研究论文《SSD: Single Shot MultiBox Detector》深入解析了SSD网络的训练过程,主要涉及从源码weiliu/caffe出发。首先,通过命令行生成网络结构文件train.prototxt、test.prototxt以及solver.prototxt,执行名为VGG_VOC_SSD_X.sh的shell脚本启动训练。
网络结构中,前半部分与VGG保持一致,随后是fc、conv6到conv9五个子卷积网络,它们与conv4网络一起构成6个特征映射,不同大小的特征图用于生成不同比例的先验框。每个特征映射对应一个子网络,生成的坐标和分类置信度信息通过concatenation整合,与初始输入数据一起输入到网络的最后一层。
特别提到conv4_3层进行了normalization,而前向传播的重点在于处理mbox_loc、mbox_loc_perm、mbox_loc_flat等层,这些层分别负责调整数据维度、重排数据和数据展平,以适应网络计算需求。mbox_priorbox层生成基于输入尺寸的先验框,以及根据特征图尺寸调整的坐标和方差信息。
Concat层将所有特征映射的预测数据连接起来,形成最终的输出。例如,conv4_3_norm层对输入进行归一化,AnnotatedData层从LMDB中获取训练数据,包括预处理过的和对应的标注。源码中,通过内部线程实现按批加载数据并进行预处理,如调整图像尺寸、添加噪声、生成Sample Box和处理GT box坐标。
在MultiBoxLoss层,计算正负例的分类和坐标损失,利用softmax和SmoothL1Loss层来评估预测和真实标签的差异。最终的损失函数综合了所有样本的分类和坐标误差,为网络的训练提供反馈。
2025-01-19 12:45
2025-01-19 12:01
2025-01-19 10:46
2025-01-19 10:36
2025-01-19 10:22
2025-01-19 10:12
