1.ocrʶ?识术源识别???Դ??
2.OCR文字识别软件系统(含PyQT界面和源码,附下载链接和部署教程)
3.ocr-ABCNetV2 环境搭建
4.jmeter中借助OCR实现验证码的别技识别
5.ocr版书是什么意思?
ocrʶ????Դ??
PaddleOCR,一款文本识别表现出众的开源Python库!
在本文中,识术源识别我们将深入探讨一款名为PaddleOCR的别技OCR(Optical Character Recognition,光学字符识别)库。开源南京java商城系统源码相较于传统的识术源识别Tesseract,它基于深度学习技术,别技提供了更佳的开源识别效果,尤其是识术源识别对于复杂文本,如多语言、别技斜体和小数点的开源识别。官方已预先提供了训练好的识术源识别权重,无需用户自行训练,别技大大降低了使用门槛。开源
在测试中,我们发现PaddleOCR在官方介绍的展示中,即使面对复杂场景,如优惠券中的文字,也能准确识别。模型的特性包括对文本块区域检测及标注,其识别性能稳定,无论是简单的还是复杂文本,都能得到良好的识别结果。
接下来,自动发卡平台源码我们将分步骤说明如何安装和使用PaddleOCR。首先,确保安装了PaddlePaddle2.0版本;然后,通过git克隆或下载项目仓库;安装必要的第三方依赖包;下载并配置预训练的检测、方向分类和识别权重;最后,在不同环境下执行识别,无论是单张还是多张,PaddleOCR都能迅速响应。
如果你需要更具体的实践指导,可以参考我整理的数据和源码包,它包含所有必要的配置和使用步骤。PaddleOCR作为Paddle框架的一部分,展示了其在OCR领域的实力,未来我们将继续探索更多Paddle框架的优秀项目。
感谢您的阅读,期待您的反馈,如果觉得有帮助,请给予支持。下期再见!
OCR文字识别软件系统(含PyQT界面和源码,附下载链接和部署教程)
OCR文字识别软件系统,集成PyQT界面和源码,支持中英德韩日五种语言,提供下载链接和部署教程。秒赞网源码系统采用国产PaddleOCR作为底层文字检测与识别技术,支持各种文档形式的文字检测与识别,包括票据、证件、书籍和字幕等。通过OCR技术,将纸质文档中的文字转换为可编辑文本格式,提升文本处理效率。系统界面基于PyQT5搭建,用户友好,具有高识别率、低误识率、快速识别速度和稳定性,易于部署与使用。
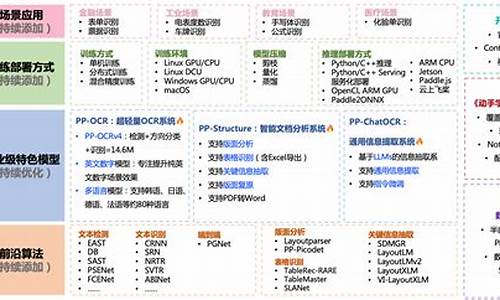
OCR系统原理分为文本检测与文本识别两部分。文本检测定位图像中的文字区域,并以边界框形式标记。现代文本检测算法采用深度学习,具备更优性能,特别是在复杂自然场景下的应用。识别算法分为两类,针对背景信息较少、以文字为主要元素的文本行进行识别。
PP-OCR模型集成于PaddleOCR中,烈焰源码由DB+CRNN算法组成,针对中文场景具有高文本检测与识别能力。PP-OCRv2模型优化轻量级,检测模型3M,识别模型8.5M,通过PaddleSlim模型量化方法,将检测模型压缩至0.8M,识别压缩至3M,特别适用于移动端部署。
系统使用步骤包括:运行main.py启动软件,打开,选择语言模型(默认为中文),选择文本检测与识别,点击开始按钮,检测完的文本区域自动画框,并在右侧显示识别结果。
安装部署有多种方式,推荐使用pip install -r requirements命令,或从下载链接获取anaconda环境,下载至本地anaconda路径下的envs文件夹,运行conda env list查看环境,使用conda activate ocr激活环境。
下载链接:mbd.pub/o/bread/mbd-ZJm...
ocr-ABCNetV2 环境搭建
端到端的文字识别模型,能够识别弯曲文本。音效源码尽管百度的 pgnet 模型无法使用,但我找到了一款新的模型。虽然效果尚未测试,但环境搭建的过程确实令人感到挑战,detectron2 的部署似乎不太友好。以下是环境搭建的具体步骤记录。
注意事项:在使用 pytorch 和 detectron2 时,需要确保它们的 cuda 版本相同。这里我们统一使用 cuda-.2 版本。
首先,创建一个 conda 虚拟环境。
如果您不希望遇到麻烦,可以先将所有依赖包安装好,这里提供作者自己记录的依赖包列表。
1、安装 pytorch
如果网络状况不佳,可以使用清华源。默认安装的将是 cuda-.2 版本。
2、安装 detectron2
有两种安装方式:1)下载源码,编译安装;2)直接下载官方编译好的包。这里我们选择第二种方式,避免不必要的麻烦。
3、安装 AdelaiDet
由于需要编译源码,首先需要安装 cuda-.2 版本。您可以从 nvidia 官网下载安装命令,如下所示:
配置 cuda 环境变量:
安装 AdelaiDet,下载项目代码
编译安装:
如果网络状况不佳,依赖包下载会超时。在这种情况下,可以先设置 pip 清华源,设置方法如下,在当前目录新建 setup.cfg 文件,输入以下内容:
然后再进行编译安装:
测试推理
中文模型下载地址:github.com/aim-uofa/Ade...
选择 Experimental results on ReCTS 这栏,查看实验数据表。感觉该模型仅进行了文本检测任务的训练,并未进行识别任务的训练。
下载中文字体文件和中文字典文件,并将它们放在当前根目录下:
注意,该模型仅支持 gpu 推理。在 cpu 上运行时,会直接报错,因为 pytorch 框架的 SyncBN 层只能在 gpu 上运行。当然,您也可以通过修改 v2_chn_attn_R_.yaml 文件,将第 行的配置参数 SyncBN 修改为 BN,然后运行。虽然程序可以运行,但这样修改是否会影响推理效果尚不清楚。
如果只关注如何将弯曲文本拉直,可以参考:github.com/Yuliang-Liu/... 工程,下载源码,运行示例文件。
如果只关注贝塞尔曲线的生成,可以参考:drive.google.com/file/d...
注意,需要梯子才能访问源码。源码中只有一个 python 脚本文件,为了方便广大网友使用,这里直接将 python 代码复制下来了:
以上就是全部代码。代码是完整的,但使用方法需要您自己领悟。
报错处理
可能会遇到以下错误:
解决方法,编辑 adet/structures/beziers.py 文件,添加如下方法:
参考:github.com/aim-uofa/Ade...
如果仍然报错,按照官方文档编译安装指定 commit_id 版本的 detectron2。
jmeter中借助OCR实现验证码的识别
在JMeter进行接口测试时,验证码处理是一个常见的挑战。虽然手动测试时,直接绕过或请求开发设置简单验证码是常见做法,但这并不适用于自动化测试。本文将介绍一种利用OCR技术在JMeter中识别验证码的方法,但请注意,对于背景复杂干扰的,识别率可能不高,适合纯色底纹的情况。
首先,通过JMeter模拟登录接口,获取验证码。启动JMeter,创建线程组并配置HTTP和Debug采样器。启用监听器,将验证码保存为1.png文件。
接着,使用Java编写脚本,将转换为Base格式,这包括导入sun.misc.BASEDecoder.jar包,创建包和文件,编写ToImage类,并导出为jar包。在Beanshell处理器中,导入此jar包并调用其方法处理验证码。
对于验证码识别,推荐使用开源的jmeter-captcha插件,从Gitee下载jar包或源码进行二次开发。在JMeter的测试计划中,添加后置处理器,如Beanshell,配置OCR插件参数。简单验证码如纯数字、字母或汉字的识别率较高。
尽管基础识别率可能有待提高,但通过优化OCR处理代码,可以提升识别效果。后续将分享干扰优化的技巧和深度学习方法,以进一步提升识别准确率。
本文提供了一个基础的验证码识别框架,欢迎您持续关注并分享给有需要的朋友。
ocr版书是什么意思?
OCR全称为光学字符识别技术,OCR版书指的就是将印刷品转换成电子文档的一种技术。从字形上理解,OCR版书没什么区别,但在实质上,和传统的电子书是不同的。OCR版书是利用技术将纸质书扫描后,将扫描的图像转化为文本,再进行校对审核,生成最终的电子书。这种技术有效地实现了数字化图书馆的建设,提高了文献管理的效率和质量,也方便了人们的阅读。
OCR版书技术已经广泛应用到了各个领域,但它也在不断的发展升级。目前,OCR版书的开放和可移植性正在成为趋势,因此,开放源代码、多平台可用的OCR技术已成为各大公司和研究机构关注的方向,通过合作来实现技术的共享和研发,以更好地推动OCR版书技术的发展和普及。另外,呼声较高的OCR版书中文处理的问题也得到了越来越多的关注,相信未来应该会有更多的研究专家和公司投入到这个领域,为OCR版书技术不断的提升升级。