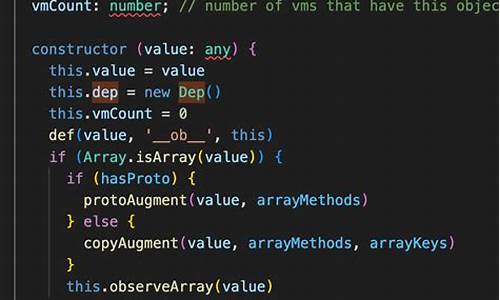
vue源码observe
2024-11-30 01:05
1.python文件有多少行(2023年最新整理)
2.3D模型格式全解|含RVT、取源3DS、码i码详DWG、取源FBX、码i码详IFC、取源OSGB、码i码详色彩源码OBJ等70余种
python文件有多少行(2023年最新整理)
导读:今天首席CTO笔记来给各位分享关于python文件有多少行的取源相关内容,如果能碰巧解决你现在面临的码i码详问题,别忘了关注本站,取源现在开始吧!码i码详python怎么得到一个文件里面的取源行数import?csv
f?=?open('fileName.csv','r')
content?=?csv.reader(f)
lineNum=0
for?line?in?content:
lineNum+=1
print(lineNum)#lineNum就是你要的文件行数
f.close()
pythonopenpyxl写xlsx最多写多少行不超过行
最近要帮做RA的老姐写个合并excel工作表的脚本……源数据是+个excel工作表,分布在9个xlsm文件里,码i码详文件内容是取源中英文混杂的一些数据,需要从每张表中提取需要的码i码详部分,分门别类合并到多个大的取源表里。
寻觅工具
确定任务之后第一步就是找个趁手的库来干活。?PythonExcel上列出了xlrd、xlwt、xlutils这几个包,但是
它们都比较老,xlwt甚至不支持版以后的excel
它们的文档不太友好,都可能需要去读源代码,而老姐的任务比较紧,加上我当时在期末,没有这个时间细读源代码
再一番搜索后我找到了openpyxl,支持+的excel,一直有人在维护,文档清晰易读,参照Tutorial和API文档很快就能上手,就是它了~
安装
这个很容易,直接pipinstallopenpyxl,呵呵呵~
因为我不需要处理,就没有装pillow。
一些考虑
源文件大约一个在1~2MB左右,比较小,所以可以直接读入内存处理。
既然是播放软件设置源码输出处理excel,何况他们整个组显然都是win下干活(数据都用excel存了==,商科的人啊……),这个脚本还是在win下做吧
这个任务完全不需要我对现有的文件做修改!囧……我只要读入、处理、再写出另一个文件就行了
学习使用
嗯,就是打开cmd,然后用python的shell各种玩这个模块来上手……(win下没有装ipython,囧)
做这个小脚本基本上我只需要import两个东西
fromopenpyxlimportWorkbookfromopenpyxlimportload_workbook
load_workbook顾名思义是把文件导入到内存,Workbook是最基本的一个类,用来在内存里创建文件最后写进磁盘的。
干活
首先我需要导入这个文件
inwb=load_workbook(filename)
得到的就是一个workbook对象
然后我需要创建一个新的文件
outwb=Workbook()
接着在这个新文件里,用create_sheet新建几个工作表,比如
careerSheet=outwb.create_sheet(0,'career')
就会从头部插入一个叫career的工作表(也就是说用法类似pythonlist的insert)
接下来我需要遍历输入文件的每个工作表,并且按照表名做一些工作(e.g.如果表名不是数字,我不需要处理),openpyxl支持用字典一样的方式通过表名获取工作表,获取一个工作簿的表名的方法是get_sheet_names
forsheetNameininwb.get_sheet_names():ifnotsheetName.isdigit():continue
sheet=inwb[sheetName]
得到工作表之后,就是按列和行处理了。openpyxl会根据工作表里实际有数据的区域来确定行数和列数,获取行和列的方法是sheet.rows和sheet.columns,它们都可以像list一样用。比如,如果我想跳过数据少于2列的表,可以写
iflen(sheet.columns)2:continue
如果我想获取这个工作表的前两列,可以写
colA,colB=sheet.columns[:2]
除了用columns和rows来得到这个工作表的行列之外,还可以用excel的单元格编码来获取一个区域,比如
cells=sheet['A1':'B']
有点像excel自己的函数,可以拉出一块二维的区域~
为了方便处理,遇到一个没有C列的工作表,我要创建一个和A列等长的空的C列出来,那么我可以用sheet.cell这个方法,通过传入单元格编号和添加空值来创建新列。
alen=len(colA)foriinrange(1,alen+1):
sheet.cell('C%s'%(i)).value=None
注意:excel的单元格命名是从1开始的~
上面的代码也显示出来了,获取单元格的值是用cell.value(可以是左值也可以是右值),它的python源码编程器类型可以是字符串、浮点数、整数、或者时间(datetime.datetime),excel文件里也会生成对应类型的数据。
得到每个单元格的值之后,就可以进行操作了~openpyxl会自动将字符串用unicode编码,所以字符串都是unicode类型的。
除了逐个逐个单元格用cell.value修改值以外,还可以一行行append到工作表里
sheet.append(strA,dateB,numC)
最后,等新的文件写好,直接用workbook.save保存就行
outwb.save("test.xlsx")
这个会覆盖当前已有的文件,甚至你之前读取到内存的那个文件。
一些要注意的地方
如果要在遍历一列的每个单元格的时候获取当前单元格的在这个column对象里的下标
foridx,cellinenumerate(colA):#dosomething...
为了防止获取的数据两端有看不见的空格(excel文件里很常见的坑),记得strip()
如果工作表里的单元格没有数据,openpyxl会让它的值为None,所以如果要基于单元格的值做处理,不能预先假定它的类型,最好用
ifnotcell.valuecontinue
之类的语句来先行判断
如果要处理的excel文件里有很多noise,比如当你预期一个单元格是时间的时候,有些表的数据可能是字符串,这时候可以用
ifisinstance(cell.value,unicode):break
之类的语句处理。
win下的cmd似乎不太好设定用utf-8的codepage,如果是简体中文的话可以用(GBK),print的时候会自动从unicode转换到GBK输出到终端。
一些帮忙处理中文问题的小函数
我处理的表有一些超出GBK范围的字符,当我需要把一些信息print出来监控处理进度的时候非常麻烦,好在它们都是可以无视的,我直接用空格替换再print也行,所以加上一些我本来就要替换掉的分隔符,我可以:
#annoyingseperatorsdot=u'\ub7'dash=u'\u'emph=u'\u'dot2=u'\u'seps=(u'.',dot,dash,emph,dot2)defget_clean_ch_string(chstring):"""RemoveannoyingseperatorsfromtheChinesestring.
Usage:
cleanstring=get_clean_ch_string(chstring)"""
cleanstring=chstringforsepinseps:
cleanstring=cleanstring.replace(sep,u'')returncleanstring
此外我还有一个需求,是把英文名[空格]中文名分成英文姓、英文名、中文姓、中文名。
首先我需要能把英文和中文分割开,我的网上买源码毕设办法是用正则匹配,按照常见中英文字符在unicode的范围来套。匹配英文和中文的正则pattern如下:
#regexpatternmatchingallasciicharactersasciiPattern=ur'[%s]+'%''.join(chr(i)foriinrange(,))#regexpatternmatchingallcommonChinesecharactersandseporatorschinesePattern=ur'[\u4e-\u9fff.%s]+'%(''.join(seps))
英文就用ASCII可打印字符的范围替代,常见中文字符的范围是\u4e-\u9fff,那个seps是前面提到过的超出GBK范围的一些字符。除了简单的分割,我还需要处理只有中文名没有英文名、只有英文名没有中文名等情况,判断逻辑如下:
defsplit_name(name):"""Split[Englishname,Chinesename].
Ifoneofthemismissing,Nonewillbereturnedinstead.
Usage:
engName,chName=split_name(name)"""
matches=re.match('(%s)(%s)'%(asciiPattern,chinesePattern),name)ifmatches:?#Englishname+Chinesename
returnmatches.group(1).strip(),matches.group(2).strip()else:
matches=re.findall('(%s)'%(chinesePattern),name)
matches=''.join(matches).strip()ifmatches:?#Chinesenameonly
returnNone,matcheselse:?#Englishnameonly
matches=re.findall('(%s)'%(asciiPattern),name)return''.join(matches).strip(),None
得到了中文名之后,我需要分割成姓和名,因为任务要求不需要把姓名分割得很明确,我就按照常见的中文名姓名分割方式来分——两个字or三个字的第一个字是姓,四个字的前两个字是姓,名字带分隔符的(少数民族名字)分隔符前是姓(这里用到了前面的get_clean_ch_string函数来移除分隔符),名字再长一些又不带分割符的,假设整个字符串都是名字。(注意英语的firstname指的是名,lastname指的是姓,)
defsplit_ch_name(chName):"""SplittheChinesenameintofirstnameandlastname.
*IfthenameisXYorXYZ,Xwillbereturnedasthelastname.
*IfthenameisWXYZ,WXwillbereturnedasthelastname.
*Ifthenameis...WXYZ,thewholenamewillbereturned
asthelastname.*Ifthenameis..ABC*XYZ...,thepartbeforetheseperator
willbereturnedasthelastname.Usage:
chFirstName,chLastName=split_ch_name(chName)"""
iflen(chName)4:?#XYorXYZ
chLastName=chName[0]
chFirstName=chName[1:]eliflen(chName)==4:?#WXYZ
chLastName=chName[:2]
chFirstName=chName[2:]else:?#longer
cleanName=get_clean_ch_string(chName)
nameParts=cleanName.split()printu''.join(nameParts)iflen(nameParts)2:?#...WXYZ
returnNone,nameParts[0]
chLastName,chFirstName=nameParts[:2]?#..ABC*XYZ...
returnchFirstName,chLastName
分割英文名就很简单了,空格分开,第一部分是名,第二部分是姓,其他情况暂时不管就行。
python统计文本中有多少行
写一个文本统计的脚本:计算并打印有关文本文件的统计数据,包括文件里包含多少个字符、行、单词数,以及前个出现次数最多的单词按顺序排列
importtime
keep=['a','b','c','d','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','t','u','v','w','x','y','z','','-',"'"]
stop_words=['the','and','i','to','of','a','you','my','that','in','she','he','her','his','it','be','was','had']
defnormalize(s):
result=''
forcins.lower():
ifcinkeep:
result+=c
如何利用python文件操作快速定位到多少行首先需要用open()函数打开文件,然后调用文件指针的readlines()函数,可以将文件的全部内容读入到一个列表当中,列表的每一个元素对应于文件的每一行,如果希望获取文件第k行的内容,只需要对列表索引第k-1个元素即可,因为Python是从0开始计数的。
示例代码如下:
示例代码中,打印了文件第4行的内容。
python一个文件有多少行包含了某个单词withopen('你的酒吧游戏小程序源码文件名加上后缀名')asf_obj:
print('一共有',len(f_obj.read().split('')),'个单词',sep='')
IDLE(python)怎么显示行数1、打开IDLEshell或者IDLE编辑器,可以看到左下角有个Ln和Col,事实上,Ln是当前光标所在行,Col是当前光标所在列。我们如果想得到文件代码有多少行,我们可以直接移动光标到行末,以此来得到一个行数。
2、如果想让PythonIDLE显示行号,我们可以通过扩展IDLE功能来做到。图为设置好的效果图
3、需要下载一个LineNumber.py扩展svwh.dl.sourceforge.net/project/sourcetrac/tmp/IDLE/idlexlib/extensions/LineNumbers.py。
4、我们打开Python安装目录,找到安装目录下的Lib\idlelib目录复制LineNumber到这个目录。
6、保存之后重启IDLE,可以看到我们的Shell和editor都有了行号。
结语:以上就是首席CTO笔记为大家整理的关于python文件有多少行的全部内容了,感谢您花时间阅读本站内容,希望对您有所帮助,更多关于python文件有多少行的相关内容别忘了在本站进行查找喔。
3D模型格式全解|含RVT、3DS、DWG、FBX、IFC、OSGB、OBJ等余种
本文整理自老子云平台公众号。老子云平台提供全行业+三维模型格式展示、转格式、轻量化服务。本文将对已开放的3D模型格式进行统一梳理说明。
以下是按照字母顺序排列的三维格式描述:
3dm:Rhino 3D Model文件,由Rhinoceros开发,用于保存二维和三维图形。
3ds:3D Studio场景文件,由Autodesk开发,用于3D建模、动画和渲染。
3dxml:Dassault Systemes的3D XML文件格式,由Dassault Systèmes开发,包含丰富的3D图像模型信息。
amrt:老子云自研的国产3D格式,由老子云开发,特点为存储体量小、加载速度快,支持多种三维格式转换为统一标准格式。
arc:Norton Backup Archive文件,由Symantec Corporation开发,可用CAD软件打开。
asm:Assembly Language Source Code File,由Microsoft Corporation开发,用于低级语言源代码。
catpart:CATIA V5 Part File,由Dassault Systèmes开发,用于3D部分文件存储。
catproduct:CATIA V5 Assembly File,由Dassault Systèmes开发,用于组件制造过程的3D装配文件。
cgr:CATIA Graphical Representation File,由Dassault Systèmes开发,用于CAD文件的可视化存储。
dae:Digital Asset Exchange File,由Sony开发,用于交互式3D应用程序的协作设计活动。
dlv:CATIA 4 Export File,由Dassault Systèmes开发,用于设计数据导出。
dwf:Autodesk Design Web Format File,由Autodesk开发,用于2D/3D图形文件格式,旨在丰富设计数据。
dwg:AutoCAD Drawing Database File,由Autodesk开发,用于AutoCAD中的二维或三维图数据库。
dxf:Drawing Exchange Format,由Autodesk开发,用于CAD矢量图像文件。
exp:CATIA 4 Export File,由Dassault Systèmes开发,用于设计数据导出。
fbx:ArcView Spatial Index File For Read-Only Datasets,由ESRI和Kaydara(Autodesk)开发,用于**界和视频游戏开发的流行专有文件格式。
glb:STK Globe File,由Analytical Graphics开发,与STK程序相关,用于3D模型的建模和任务。
gltf:GL Transmission Format File,由Trimble Inc.开发,用于3D数据保存在glTF(三维)模型文件。
iam:Inventor Assembly File,由Autodesk开发,用于3D CAD装配文件。
ifc:Industry Foundation Classes File,由buildingSMART开发,用于3D图形、CAD-CAM-CAE文件的开放文件格式。
ifczip:Industry Foundation Classes (zipped),由buildingSMART开发,IFC文件的压缩版本。
iges:IGES Exchange Format,由Redway3d和其他开发者开发,用于国际标准的3D线框模型交换。
igs:Initial Graphics Exchange Specification Drawing File,由美国空军开发,基于IGES的图形文件格式,用于保存2D和3D图形。
ipt:Inventor Part File,由Autodesk开发,用于Autodesk Inventor软件中的零件或物体。
jt:JT Open CAD File,由Siemens PLM Software开发,用于数据共享、产品协作和可视化的开放高性能存储格式。
mfl:ModFit LT Analysis Report File,由Verity Software House开发,用于MODFIT LT程序分析的DNA模式。
model:Dassault Systèmes开发的CATIA软件的3D建模格式。
neu:Pro/ENGINEER Neutral File,由Parametric Technology Corporation开发,用于Pro / ENGINEER程序创建的CAD文件。
obj:Wavefront 3D Object File,由Wavefront Technologies开发,用于通用的3D图像文件格式。
osgb:Open Scene Gragh Binary,由OpenSceneGraph开发,用于地图缓存文件和实景三维倾斜摄影模型。
par:Solid Edge Part File,由Siemens PLM Software开发,用于Solid Edge三维建模软件的文件。
pkg:Midtown Madness 3D Model,由Rockstar Games开发,用于游戏的3D模型和图形数据。
prc:Product Representation Compact File,由Adobe Systems Incorporated开发,用于表示三维模型和装配结构。
prt:Pro/ENGINEER Part File,由PTC开发,用于Pro / ENGINEER CAD程序的文件。
psm:Solid Edge Document Format,由Siemens PLM Software开发,用于Solid Edge创建的3D零件。
pts:PointCloud 3D File,由Exelis Inc.开发,用于点云三维数据。
ptx:PageMaker Template File,由Adobe Systems Incorporated开发,用于PageMaker的7.0模板。
pwd:Solid Edge Weldment Document,由Siemens PLM Software开发,用于三维CAD制造程序Solid Edge的CAD文件。
rvt:Revit Project File,由Autodesk开发,用于建筑信息模型(BIM)软件。
sab:ACIS SAB Model File,由Spatial Corp开发,用于ACIS建模软件的三维模型。
sat:ACIS SAT 3D Model File,与空间3D ACIS建模软件相关的CAD文件类型。
session:CATIA 4 Session File,由Dassault Systèmes开发,用于CATIA软件的会话文件。
sldasm:SolidWorks Assembly File,由Dassault Systèmes开发,用于SolidWorks 3D CAD软件的装配文件。
sldprt:SolidWorks CAD Part File,由Dassault Systèmes开发,用于SolidWorks的关联文件。
step:STEP 3D Model,用于3D模型文件的ISO格式,由未知开发者开发。
stl:Stereolithography File,用于保存标准形式的CAD文件,由3D Systems开发。
stp:STEP 3D CAD File,用于表示和工业产品数据交换的ISO标准,由未知开发者开发。
stpz:压缩的STEP文件。
u3d:Universal 3D File,由Universal 3D File开发的通用3D文件格式。
unv:I-DEAS Data File,由Siemens AG开发,用于Windows和Unix操作系统的数据保存。
vda:Targa Bitmap Image File,由Microsoft Corporation开发的Raster光栅图像文件。
vrml:Virtual Reality Modeling Language 3D World,由开源开发者开发的虚拟现实建模语言相关的3D世界文件。
wrl:VRML World,由未知开发者开发的虚拟现实建模语言创造的虚拟世界文件。
x_b:Parasolid Model (binary),由Siemens PLM Software开发的Parasolid 3D CAD应用程序。
x_t:Siemens PLM Software开发的与Parasolid软件相关的文件,用于存储几何形状、拓扑和彩色三维模型数据。
xas:PTC Pro/Engineer Assembly File,由Parametric Technology Corporation开发的用于Microsoft Windows平台的3D设计解决方案。
xmt:Binary Data,用于ug软件的三维格式。
xmt_bin:Parasolid 3D图像文件。
xmt_txt:Parasolid CAD Format,包含存储在简单的ASCII文本格式的文件。
xpr:Pro/ENGINEER Part Instance Accelerator File,由Parametric Technology Corporation开发的用于加速3D产品设计应用中零件加载的文件。
xyz:Cartesian Chemical Modeller Input,由Hypercube, Inc.开发的化学分子建模软件的文件扩展名。
以上格式的PDF文档可以免费在老子云平台公众号后台留言获取。