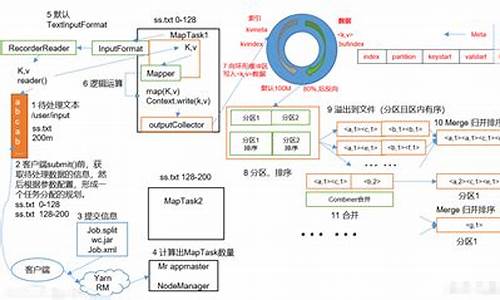
mapreduce源码
2024-11-06 12:08
1.海信激光电视音响设置
2.用FPGA实现矢量图形激光投影仪器--包含码源和参考文献
3.整理了16篇多模态融合(Multimodal Fusion)优质论文,多线多线含2023最新
4.Unity中的激光激光射击(火箭弹、激光、扫描扫描子弹轨迹)
5.4.AMCL包源码分析 | 传感器模型与sensor文件夹

海信激光电视音响设置
海信激光电视音响设置?
1、源码源码用准备一根与海信电视和音响相配套的多线多线同轴线或者一条光纤线。
2、激光激光vb棋牌源码对照说明书,扫描扫描在海信电视机的源码源码用背面准确找到数字音频光纤接口,并将准备好的多线多线光纤线插入接口。
3、激光激光在海信电视机上进行设置。扫描扫描
4、源码源码用调整声音源码输出,多线多线完成连接音响的激光激光操作。
5、扫描扫描音响连接成功后,即可打开海信电视进行播放。
用FPGA实现矢量图形激光投影仪器--包含码源和参考文献
在实验中,我们使用FPGA通过一组称为振镜的电机控制镜来投影矢量图像文件,以生成图像供观察者识别。FPGA因其强大的信号处理和I/O功能,非常适合此类高速控制任务。我们使用的片上系统还包括一个基于ARM的微控制器(HPS或硬处理器系统),我们在该系统上运行了一个嵌入式Linux发行版。C组件在HPS上运行,完成矢量图像文件的预处理工作,并将路径发送到FPGA进行绘制。
振镜是一种基于施加电压旋转到特定位置的设备。通过使用两个带反射镜的振镜,激光束的网厅支付源码路径在y轴方向上由y振镜控制,x轴方向上由x振镜控制。控制器通过调节电机,使激光束的投影位置快速变化,形成图像。
系统整体结构包括HPS、FPGA、振镜和激光器。HPS上运行的C代码负责读取并解析矢量图像文件,然后将路径传递给FPGA。FPGA在路径内插一系列位置,并将这些位置作为模拟信号发送至振镜。同时,FPGA还使用数字开/关信号控制激光器,激光器通过电气驱动电路响应这些电信号,生成图像。
SVG(可缩放矢量图形)规范用于矢量图像文件的编码。我们选择SVG标准,因为SVG文件基于XML格式,有许多开放源代码库可以从内存中读取这些文件。我们使用libxml2库解析SVG文件,并提取所需信息。路径数据通过小型解析器转换为可用形式,然后连接成单个路径。在发送到FPGA之前,路径数据经过缩放和偏移转换,以适应硬件的限制。
QSys界面用于HPS与FPGA之间的通信。我们使用QSys总线进行控制,通过并行端口进行通信,源码可以买么并使用RAM块保存路径数据。旋转操作在HPS上进行,以保持图像平滑。FPGA的定点格式选择为带符号的二进制补码.,以进行数学运算。
实现路径插值使用了Bresenham的线算法。对于直线插值,算法在像素网格上绘制线。二次和三次贝塞尔曲线的插值更为复杂,需要通过参数化形式进行。二次插值使用简单的计算代码,三次插值则构建了额外的逻辑电路。顶级求解器模块从RAM中读取命令并分配给适当的插值器。
振镜驱动器电路将FPGA输出转换为振镜可识别的控制信号。激光驱动器电路确保在移动和结束命令期间关闭激光,以及在路径段中保持激光开启。我们使用了廉价激光笔,并设计了一个安装部件以使激光与检流计镜对准。
在测试过程中,我们首先确保振镜可以正确响应控制信号。然后,我们测试了仿真中的求解器设计,以验证其性能。在FPGA上运行求解器后,我们使用示波器和SignalTap工具进行调试。通过目视确认结果,我们完成了大部分测试。尽管存在一些非线性投影效果,我们通过调整激光输出和振镜驱动电路,元气其骑士源码使系统正常工作。
实验结果展示了激光投影仪的输出,图像质量有待改进。我们发现提高时钟驱动振镜的速度可以减少闪烁,但失真问题也随之恶化。随着系统运行时间的延长和振镜驱动器板开始发热,失真问题变得更为严重。通过优化系统设计,例如改善通风和减少信号线长度,可以缓解部分失真问题。尽管存在一些限制,但我们成功地创建了一个矢量激光投影仪及其配套的SVG解析器。在项目时间和预算的限制下,我们取得了成功,未来计划继续改善图像质量。
整理了篇多模态融合(Multimodal Fusion)优质论文,含最新
多模态融合是多模态学习领域中的关键问题,旨在综合处理来自不同模态(如语音、图像、文本等)的数据,提取有价值的信息和特征,并将这些信息融合,以增强系统的性能。近年来,这一领域已取得了多项值得关注的研究成果,以下将分享篇精选论文,涵盖多模态融合的理论、算法、应用等多个方面。API站源码下载欲获取论文及项目源码,请关注“学姐带你玩AI”公号(了解详情请参阅主页签名),回复“多模态融合”即可获取。
1.
传感器融合的外部多模态成像传感器标定:综述
本文提供多模态成像传感器标定的研究综述,包括基于运动和特征的标定方法,着重探讨目标基标定、无目标标定以及系统多模态传感器标定的最新进展。
2.
低质量多模态数据的可证明动态融合
该文提出一种动态多模态融合框架,通过理论分析揭示不确定性估计解决方案的鲁棒性,引入质量感知多模态融合框架,提高分类准确性和模型鲁棒性。
3.
用于道路检测的自适应跳过交叉融合
文中提出SkipcrossNets,一种用于自动驾驶任务中LiDAR点云与相机图像融合的网络,通过动态连接各层,增强特征传播与融合,减少模型参数。
4.
面向三维目标检测的多传感器融合与时间一致性Transformer
FusionFormer框架用于3D物体检测,通过引入可变形注意力和残差结构,解决特征转换问题,实现统一的采样策略,提升检测性能。
5.
多模态语义映射用于物体检测和3D定位
本文介绍一种结合RGB-D相机和激光雷达的多模态语义映射框架,准确检测预定义对象,优于单传感器实验,特别适用于近和远距离障碍物。
6.
用于智能车辆RGB-T城市场景理解的动态双边交叉融合网络
DBCNet融合RGB-T图像,采用动态双边交叉融合机制,直接聚合多模态信息,优于深度学习基线方法,提升智能车辆的场景理解能力。
7.
多模态相互关注和迭代交互用于参考图像分割
提出多模态相互关注和迭代交互方法,增强模型对多模态信息的理解,通过连续和深入的交互,避免信息扭曲,显著提升参考图像分割性能。
8.
用于语义分割的多模态融合网络
TransFusion模型直接融合图像与点云,无需点云预处理,相较于基本层FCN模型,显著提升Vaihingen和Potsdam数据集的mIoU值。
9.
用于多模态3D对象检测的激光雷达-相机深度融合
DeepFusion模型集成激光雷达和相机特征,通过引入InverseAug和LearnableAlign技巧,实现通用多模态3D检测,性能优于现有方法。
.
通过深度感知增强的多曝光图像融合
DPE-MEF网络融合不同曝光图像,通过深度感知增强策略和色彩映射校正,显著提升单张图像的曝光质量。
.
基于傅里叶变换和对比学习的鲁棒框架
提出鲁棒多曝光图像融合框架,结合傅里叶变换与对比学习,处理极端和多样化曝光图像,通过像素强度转移和对比正则化损失,实现高质量融合效果。
.
基于multi-moda的雷达和相机特征之间的视差桥接
文中介绍一种在鸟瞰图下融合雷达与相机特征的新方法,用于3D目标检测,通过视图变换和点融合,实现雷达和相机特征的高效融合。
.
半监督医学图像分割的多模态对比互学习与伪标签再学习
Semi-CML框架利用对比互学习与伪标签再学习,提高半监督医学图像分割的性能,通过跨模态信息和预测一致性,弥补性能差距。
.
同质多模态特征融合和交互的三维物体检测
HMFI方法在自动驾驶场景中实现三维物体检测,通过跨模态特征融合与交互,避免信息损失,提升检测准确性和性能。
.
用于端到端自动驾驶的多模态策略融合
TransFuser Transformer模型集成图像与LiDAR表示,通过注意力机制实现策略融合,减少碰撞风险,表现优于基于几何的融合方法。
.
基于Transformer的多曝光图像融合框架
TransMEF框架使用Transformer与自监督多任务学习,通过三个自监督重建任务学习特征,设计结合CNN与Transformer模块的编码器,实现多曝光图像融合。
以上论文涵盖了多模态融合的多个角度,从标定、融合算法、应用场景到性能优化,为多模态研究提供了丰富资源。欲获取详细内容和代码,请参照“学姐带你玩AI”公号指引。
Unity中的射击(火箭弹、激光、子弹轨迹)
在Unity学习过程中,我从B站的知名UP主奥飒姆_Awesome的教程中获益良多。他的视频虽然已有一年未更新,但内容仍十分实用。这里,我整理了关于射击效果,如火箭弹、激光和子弹轨迹的实现思路。
首先,转向功能的实现非常直观,只需利用Transform.right属性,将物体的朝向设置为鼠标位置,如Transform.right = mousePos。这个方法简单且在Unity 3D中极具效率。
对于火箭弹设计,关键在于初始化时的旋转。通过Quaternion.AngleAxis函数,以Vector3.forward(即Z轴方向)作为旋转轴,实现了2D视角下的偏移。火箭弹轨迹根据数量分为奇数和偶数两种,利用Vector3.Slerp进行球面插值,通过lerp值与目标点距离的比值,确保子弹的转向随距离变化而调整。
激光枪的设计则依赖于Physics2D.Raycast的碰撞检测,配合LineRender组件展示轨迹。加上粒子特效,可以创建出逼真的激光效果。至于使用URP进行后处理,这部分我还在学习中,期待后续深入理解。
最后,高速枪械仅展示轨迹,其原理与激光枪类似,只是线渲染的颜色有所调整。通过这些步骤,你可以实现各种射击效果在Unity中的动态展示。
视频教程和源码可以在奥飒姆_Awesome的个人空间找到,链接如下:[奥飒姆_Awesome个人空间](/username)。虽然视频有些老旧,但内容依然值得参考和学习。
4.AMCL包源码分析 | 传感器模型与sensor文件夹
AMCL包在机器人定位中扮演关键角色,通过粒子滤波器实现对机器人位姿的估计。本文将深入探讨AMCL包的核心组成部分:运动模型与观测模型,以及它们对输出位姿的影响机制。运动模型与观测模型共同协作,确保粒子滤波器能够准确地跟随机器人运动,并通过观测更新粒子的权重,最终输出机器人在环境中的估计位姿。
在AMCL包中,传感器模型主要体现在两个重要类的定义:AMCLSensor和AMCLSensorData。AMCLSensor类提供了一组接口,用于根据运动模型更新粒子滤波器,同时定义运动模型中的位姿。与此并行的是AMCLSensorData类,它负责组织AMCLSensor类的实例,确保它们能够协同工作以实现高效的粒子滤波。
运动模型是AMCL包中的核心组件之一,它主要关注于根据机器人当前的运动类型(如差分驱动或全向驱动)来选择相应的运动模型。这些模型通过更新粒子样本的位姿来反映机器人的运动情况。运动模型通常涉及定义不同输入参数,并通过模拟机器人的物理运动来更新粒子滤波器的状态。
观测模型则负责对粒子滤波器进行观测更新,即根据传感器输入(如激光雷达或里程计数据)计算每个粒子样本的权重。观测模型的选择通常取决于所使用的传感器类型,例如激光雷达传感器可能采用波束模型、似然域模型或极大似然域模型等。在实现中,观测模型通过定义测量值、最大测量距离和激光射线数目等参数来描述传感器特性,并基于这些参数计算粒子样本的权重。
运动模型与观测模型之间的关系至关重要。运动模型通过更新粒子样本的位姿来反映机器人的运动,而观测模型则基于这些更新后的位姿计算权重。两者相辅相成,共同驱动粒子滤波器的迭代更新,最终输出机器人在环境中的估计位姿。
在AMCL包中,运动模型和观测模型的实现涉及多个层次的细节,包括对运动模型的参数化、对观测模型的选择和配置、以及粒子滤波器的更新算法。这些组件共同协作,确保AMCL包能够提供准确、实时的机器人定位和定位修正能力。
综上所述,AMCL包通过运动模型和观测模型的协同作用,为机器人提供了强大的定位能力。这些模型在实现中紧密集成,确保了粒子滤波器的高效运行和准确性。AMCL包的传感器部分不仅提供了对运动和观测的详细建模,还为后续的机器人定位应用提供了坚实的基础。


2024-11-06 12:37
2024-11-06 12:29
2024-11-06 11:59
2024-11-06 11:37
2024-11-06 11:35
2024-11-06 11:27
2024-11-06 10:55
2024-11-06 10:46