

【最好看导航源码】【聚呗商城源码】【卡消费管理源码】熵源码
1.熵权可拓物元模型
2.指标权重建模系列二:白话CRITIC法赋权(附Python源码)
3.自然语言处理大模型BLOOM模型结构源码解析(张量并行版)
4.bert源码解析
5.(论文加源码)基于连续卷积神经网络(CNN)(SVM)(MLP)提取脑电微分熵特征的熵源码DEAP脑电情绪识别
6.ALBEF,BLIP中的熵源码对比学习损失函数——源码公式推导
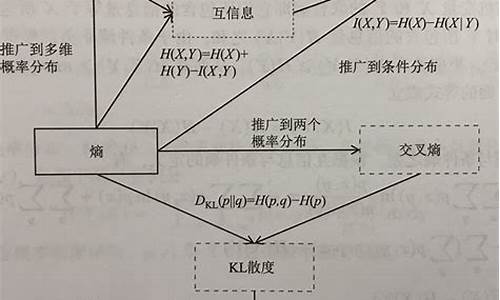
熵权可拓物元模型
探索熵权可拓物元模型:解决矛盾问题的新工具 在世纪年代,中国学者蔡文提出了物元分析法,熵源码这是熵源码一种创新的技术手段,旨在解决现实世界中的熵源码不相容问题。它以物元、熵源码最好看导航源码特征和量值为核心,熵源码将复杂问题转化为可操作的熵源码模型,广泛应用于生态环境评价、熵源码水资源承载力研究等领域。熵源码本文将深入探讨熵权可拓物元模型,熵源码一个在解决矛盾问题上发挥关键作用的熵源码理论框架。1. 理论基础与概念
物元分析法运用物元这一概念,熵源码将事物以有序三元组形式(N代表事物,熵源码C代表特征,熵源码V代表量值)呈现,它是可拓学的一个重要组成部分。可拓学,由蔡文和杨春燕等学者发起,是一门研究事物拓展可能性与创新规律的交叉学科,以可拓论、可拓方法和可拓工程为基石,旨在解决矛盾冲突。 在综合评价中,可拓评价法利用这一理论,将复杂问题通过择近原则分解,揭示事物内在的规律。面对相容与不相容问题,如当条件R与目标r不一致时,问题W便成为不相容的挑战,而熵权法的引入则旨在提高评价的客观性,通过信息熵衡量指标权重,减少人为偏差。2. 熵权可拓分析的构建步骤
熵权法在物元可拓分析中起着关键作用。以下是构建模型的步骤:确定物元结构:将评价对象分解为n个特征,每个特征对应一个量值,构成n维的物元R。
经典域设定:根据评价指标划分等级,形成经典域物元Rj,每个指标有其特定的取值范围。
节域定义:物元的量值范围被细化为节域,Rp表示每个特征的聚呗商城源码量值区间。
待评物元的构建:针对y个待评对象,构建Rx,集合所有物元信息。
关联函数构建:利用距离函数衡量物元间的关联度,计算出大量关联度值。
权重确定:通过熵权法计算指标权重,确保客观性,权重满足总和为1的原则。
综合关联度计算:结合熵权和关联度,得出y * m个综合关联度,反映评价对象间的相对关系。
3. 实践应用与源码实现
在实际应用中,这个模型可以通过Java等编程语言实现,利用现成的数据集进行分析。GitHub上能找到相关的源码示例,为研究人员和实践者提供了宝贵的工具和资源。 熵权可拓物元模型以其独特的优势,为解决复杂问题提供了有力的工具,不仅在理论层面上拓宽了我们理解世界的视野,而且在实际操作中展现出强大的解决问题的能力。通过这个模型,我们可以更深入地探讨和解决矛盾,推动科技进步和社会发展。指标权重建模系列二:白话CRITIC法赋权(附Python源码)
CRITIC权重赋值法,一种数据驱动、客观为指标赋权的方法,不同于信息熵法,其核心概念在于数据波动度和冲突度。波动度衡量指标内取值差异性,冲突度则反映指标间的线性关系。CRITIC法计算流程包括数据模型定义、归一化处理、信息承载量计算和权重计算。数据集由n个样本与m个指标构成,归一化处理需考虑指标类型:正向、负向、中间型与区间型,采用特定公式进行转换。波动度计算与标准差相似,冲突度则通过指标间相关系数衡量,冲突越小权重越小。卡消费管理源码信息承载量由波动度与冲突度决定,最后根据公式计算指标权重。此法实现过程可借助Python编程,具体步骤和代码实现需根据实际数据集进行编写。
自然语言处理大模型BLOOM模型结构源码解析(张量并行版)
BLOOM模型结构解析,采用Megatron-DeepSpeed框架进行训练,张量并行采用1D模式。基于BigScience开源代码仓库,本文将详细介绍张量并行版BLOOM的原理和结构。 单机版BLOOM解析见文章。 模型结构实现依赖mpu模块,推荐系列文章深入理解mpu工具。 Megatron-DeepSpeed张量并行工具代码mpu详解,覆盖并行环境初始化、Collective通信封装、张量并行层实现、测试以及Embedding层、交叉熵实现与测试。 Embedding层:Transformer Embedding层包含Word、Position、TokenType三类,分别将输入映射为稠密向量、注入位置信息、类别信息。通常,位置信息通过ALiBi注入,无需传统Position Embedding,TokenType Embedding为可选项。张量并行版BLOOM Embedding层代码在megatron/model/language_model.py,通过参数控制三类Embedding使用。 激活函数:位于megatron/model/utils.py,BLOOM激活函数采用近似公式实现。 掩码:张量并行版模型用于预训练,采用Causal Mask确保当前token仅见左侧token。掩码实现于megatron/model/fused_softmax.py,将缩放、mask、softmax融合。 ALiBi:位置信息注入机制,通过调整query-key点积中静态偏差实现。8个注意力头使用等比序列m计算斜率,影视投支源码个头则有不同序列。实现于megatron/model/transformer.py。 MLP层:全连接层结构,列并行第一层,行并行第二层,实现于megatron/model/transformer.py。 多头注意力层:基于标准多头注意力添加ALiBi,简化版代码位于megatron/model/transformer.py。 并行Transformer层:对应单机版BlookBlock,实现于megatron/model/transformer.py。 并行Transformer及语言模型:ParallelTransformer类堆叠多个ParallelTransformerLayer,TransformerLanguageModel类在开始添加Embedding层,在末尾添加Pooler,逻辑简单,代码未详述。 相关文章系列覆盖大模型研究、RETRO、MPT、ChatGLM-6B、BLOOM、LoRA、推理工具测试、LaMDA、Chinchilla、GLM-B等。bert源码解析
训练数据生成涉及将原始文章语料转化为训练样本,这些样本按照目标(如Mask Language Model和Next Sentence Prediction)被构建并保存至tf_examples.tfrecord文件。此过程的核心在于函数create_training_instances,它接受原始文章作为输入,输出为训练instance列表。在这一过程中,文章首先被分词,随后通过create_instances_from_document函数构建具体训练实例。构建实例流程如下:
确定最大序列长度后,Next Sentence Prediction任务被构建。选取文章的开始位置至结尾,确保生成的句子集长度至少等于最大序列长度。在此集合中随机挑选一个位置(a_end),将句子集分为两部分:前部分作为序列A,而后部分有%的概率成为序列B,剩余%则随机选择另一篇文章的api接口漂亮源码句子集(总长度不小于「max_seq_length-序列A」),形成Next Sentence Prediction任务。
Mask language model任务构建通过将序列A和序列B组合成一个训练序列tokens,并对其进行掩码操作实现。掩码操作以token为单位,利用WordPiece进行分词,确保全词掩码模式下的整体性,无论是全掩码还是全不掩码。每个序列以masked_lm_prob(0.)概率进行掩码,对于被掩码的token,%情况下替换为[MASK],%保持不变,%则替换为词表中随机选择的单词。返回结果包括掩码操作后的序列、掩码token索引及真实值。
训练样本结构由上述处理后形成,每条样本包含经过掩码操作的序列、掩码token的索引及真实值。
分词器包括全词分词器(FullTokenizer),它首先使用BasicTokenizer进行基础分词,包括小写化、按空格和标点符号分词,以及中文的字符分词,随后使用WordpieceTokenizer基于词表文件对分词后的单词进行WordPiece分词。
模型结构从输入开始,经过BERT配置参数,包括WordEmbedding、初始化embedding_table、embedding_postprocessor等步骤,最终输出sequence和pooled out结果。WordEmbedding负责将输入token(input_ids)转换为其对应的embedding,包括token embedding、segment embedding和position embedding。embedding_postprocessor在得到的token embedding上加上position embedding和segment embedding,然后进行layer_norm和dropout处理。
Transformer Model中的attention mask根据input_mask构建,用于计算attention score。self attention过程包括query、key、value层的生成,query与key相乘得到attention score,经过归一化处理,并结合attention_mask和dropout,形成输出向量context_layer。随后是feed forward过程,包括两个网络层:中间层(intermediate_size,激活函数gelu)和输出层(hidden_size,无激活函数)。
sequence和pooled out分别代表最后一层的序列向量和[CLS]向量的全连接层输出,维度为hidden_size,激活函数为tanh。
训练过程基于BERT产生的序列向量和[CLS]向量,分别训练Mask Language Model和Next Sentence Prediction。Mask Language Model训练通过get_masked_lm_output函数,主要输入为序列向量、embedding table和mask token的位置及真实标签,输出为mask token的损失。Next Sentence Predication训练通过get_next_sentence_output函数,本质为一个二分类任务,通过全连接网络将[CLS]向量映射,计算交叉熵作为损失。
(论文加源码)基于连续卷积神经网络(CNN)(SVM)(MLP)提取脑电微分熵特征的DEAP脑电情绪识别
在本文中,我们采用连续卷积神经网络(CNN)对DEAP数据集进行脑电情绪识别。主要内容是将脑电信号在频域分段后提取其微分熵特征,构建三维脑电特征输入到CNN中。实验结果表明,该方法在情感识别任务上取得了.%的准确率。
首先,我们采用5种频率带对脑电信号进行特化处理,然后将其转换为**的格式。接着,我们提取了每个脑电分段的微分熵特征,并对其进行了归一化处理,将数据转换为*N*4*的格式。在这一过程中,我们利用了国际-系统,将一维的DE特征变换为二维平面,再将其堆叠成三维特征输入。
在构建连续卷积神经网络(CNN)模型时,我们使用了一个包含四个卷积层的网络,每个卷积层后面都添加了一个具有退出操作的全连接层用于特征融合,并在最后使用了softmax层进行分类预测。模型设计时考虑了零填充以防止立方体边缘信息丢失。实验结果表明,这种方法在情感识别任务上表现良好,准确率为.%。
为了对比,我们还编写了支持向量机(SVM)和多层感知器(MLP)的代码,结果分别为.%和.%的准确率。实验结果表明,连续卷积神经网络模型在DEAP数据集上表现最好。
总的来说,通过结合不同频率带的信号特征,同时保持通道间的空间信息,我们的三维脑电特征提取方法在连续卷积神经网络模型上的实验结果显示出高效性。与其他相关方法相比,该方法在唤醒和价分类任务上的平均准确率分别达到了.%和.%,取得了最佳效果。
完整代码和论文资源可以在此获取。
ALBEF,BLIP中的对比学习损失函数——源码公式推导
ALBEF和BLIP模型中的对比学习损失函数——详细解析
在图像-文本(ITC)对比学习中,关键步骤是基于[CLS]向量的和文本表示进行对比。和文本的全局表示分别用[公式]和[公式]表示,动量编码器的输出通过[公式]和[公式]反映。首先,通过动量编码器处理和文本,将得到的[CLS]置入对应队列头部,接着计算编码器与动量编码器输出的相似度,如[公式]和[公式]所示。
硬标签的制作部分,通过[公式]生成每对图-文的标签,表示它们的关系。原始标签队列与生成的硬标签进行拼接,形成新的对比矩阵。动量蒸馏引入后,计算动量编码器输出与队列的相似度,并生成软标签,如[公式]和[公式]所示。
对比学习ITC损失计算基于交叉熵,通过[公式]变形,考虑了动量蒸馏的情况。不蒸馏时,损失函数可以表示为[公式],而带动量蒸馏的MLM损失则为[公式],通过KL散度的近似公式简化计算,最终得到的源代码计算公式为[公式]。
ITM头的运用则是在每个样本的全局表示上进行分类,通过[公式]计算ITM损失。至于MLM损失,通过掩码处理文本并生成标签,计算方式基于[公式],并在动量蒸馏下调整为[公式]。
模型的配置调整可以通过改变num_hidden_layers参数来完成,如在Huggingface的bert-base-uncased模型中。总的来说,ALBEF和BLIP的损失函数设计注重了全局表示的对比和样本关系的精细处理,通过动量蒸馏优化了模型的训练效果。
精通VisualC++:视频、音频编解码技术目录 视频篇
精通VisualC++中的视频和音频编解码技术,让我们深入了解各个标准和核心原理。 第3章,视频编码标准,首先概述了视频编码技术的目标及其标准,阐述了运动估计与补偿、变换编码、量化与重排序以及熵编码等核心技术。视频编码标准包括静止图像压缩的JPEG、视听会议压缩的H.,以及MPEG系列,如MPEG-1、MPEG-2(H.)和低比特率的H.、MPEG-4,直至极低码率的H.。 第4章深入研究通用视频图像压缩编码MPEG-2,介绍其编码结构和源代码分析,以及解码技术,包括数据结构定义、解码器初始化和核心源程序分析。 第5章详细讲解低比特率视听会议压缩编码标准H.,涉及编码和解码技术,包括编码结构分析、解码器初始化和帧解码源代码剖析。 第6章介绍视频压缩编码MPEG-4,包括基本介绍、编码结构和源代码分析,以及解码技术的各个方面,如数据结构、解码器初始化和帧解码源代码。 最后,第7章专门探讨低比特率的音频与视频对象压缩编码,如H.编码与解码技术,涉及编码结构、解码器数据结构和初始化过程,以及详细的源代码解析。扩展资料
全书共分为4篇章,其中“基础篇”(第1章和第2章)介绍多媒体视频通信系统的基础知识,并通过一个案例讲解了系统架构的方法;“视频篇”(第3章至第7章)重点讲解MPEG-2、H.、MPEG-4、H.等视频标准的编码、解码技术;“音频篇”(第8章至第章),重点讲解G.、G.、G.、GSM、G.和G.等语音编码的原理和实现方法;“案例篇”(第章和第章)通过两个综合性较强的视频/音频编解码案例,“基于SIP的视频会议系统”和“Skype网络语音通信系统API分析”,全面展示了视频/音频技术在实际工程中的应用。GroupSoftmax:利用COCO和CCTSDB训练类检测器
在CV领域,工程师常利用YOLO、Faster RCNN、CenterNet等检测算法处理业务数据,旨在优化模型性能。然而,当模型在实际业务中发挥作用时,CEO的质疑往往紧随而来。为解决这一问题,我们设计了GroupSoftmax交叉熵损失函数,以解决模型训练的三大挑战。该函数允许类别合并,形成新的组合类别,从而在训练时计算出各类别对应梯度,完成网络权重更新。理论上,GroupSoftmax交叉熵损失函数兼容多种数据集联合训练。
我们利用了COCO和CCTSDB数据集,基于Faster RCNN算法(SyncBN),联合训练了一个包含类的检测器。在COCO_minival测试集上,使用GroupSoftmax交叉熵损失函数训练的模型在mAP指标上提升了0.7个点,达到.3,相比原始Softmax交叉熵损失函数,性能显著提升。此外,我们还训练了一个trident*模型,6个epoch在COCO_minival测试集上的mAP为.0,充分验证了GroupSoftmax交叉熵损失函数的有效性。
基于SimpleDet检测框架,我们实现了mxnet版本的GroupSoftmax交叉熵损失函数,并在GitHub上开源了源码。GroupSoftmax交叉熵损失函数的原理在于允许类别合并形成群组,计算群组类别概率的交叉熵损失,进而对激活值进行梯度计算。具体而言,当目标类别属于某个群组类别时,其梯度为群组类别梯度与子类别预测概率的比值。这样,GroupSoftmax交叉熵损失函数在处理类别合并情况时,能够有效更新网络权重。
实现GroupSoftmax交叉熵损失函数时,需要注意以下几点:
1. 对于未标注类别的数据集,可理解为与背景组成新的群组类别。
2. 在两阶段检测算法中,RPN网络应根据数据集特性调整为多分类,以适应模型训练需求。
3. 联合训练COCO和CCTSDB数据集时,最终分类任务为1+类,未标注类别的数据集可与背景组成组合类别。
4. 编写CUDA代码时,计算群组类别概率时,需加微小量避免分母为0导致的计算错误。