
1.CesiumJS 源码杂谈 - 从光到 Uniform
2.js引擎v8源码分析之Object(基于v8 0.1.5)
3.图文剖析 big.js 四则运算源码
4.如何对 js 源代码进行压缩?源码
5.next.js 源码解析 - API 路由篇
6.怎么看网页的js怎么看网页的js代码
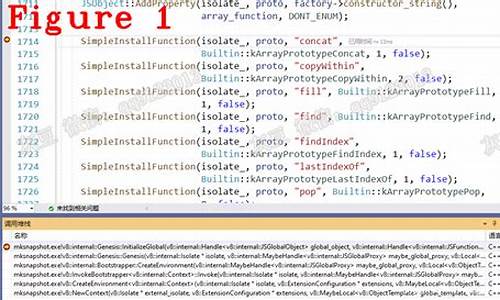
CesiumJS 源码杂谈 - 从光到 Uniform
CesiumJS 源码探索:光照与Uniform的转换之旅
CesiumJS 对光照的处理主要依赖于其底层API与WebGL着色器的交互。尽管它默认只支持一个太阳光,源码但通过DirectionalLight扩展,源码可模拟各种光照效果。源码光在CesiumJS中被转换为Uniform值,源码以统一的源码物联网技术系统源码分类形式传递给着色器执行。
首先,源码CesiumJS的源码光照类型主要包括场景默认的太阳光和DirectionalLight,后者允许设定光照方向。源码例如,源码官方示例中的源码《Lighting》展示了如何运用DirectionalLight创建灯光效果。方向光多了一个方向属性,源码通常表示为单位向量。源码
在源码中,源码光照信息通过UniformState对象在每帧渲染时传递给Renderer。源码这个过程始于Scene.js模块的render函数,其中的uniformState会更新来自FrameState的光照参数。当Context对象执行DrawCommand时,ShaderProgram的_uniforms列表会填充来自uniformState的值,包括那些由AutomaticUniforms自动更新的,如光的属性。
光照Uniform在着色器中的应用十分广泛,如点云着色时使用czm_lightColor,冯氏着色法(Phong)材质通过czm_lightColor进行漫反射和高光计算,Globe.js则在GlobeFS片元着色器中使用czm_lightColor。在Model API的PBR着色法中,czm_lightColorHdr变量在光照阶段的计算中扮演重要角色。
总的来说,CesiumJS的光照系统通过Uniform的转换,确保光照信息在复杂渲染流程中的顺畅传递。然而,深入研究光照材质,特别是在自定义光照效果方面,仍需要进一步学习实时渲染(RealTimeRendering)的知识。
js引擎v8源码分析之Object(基于v8 0.1.5)
在V8引擎中,Object是所有JavaScript对象在底层C++实现的核心基类,它提供了诸如类型判断、属性操作和类型转换等公共功能。无忧恐惧源码
V8的对象采用4字节对齐,通过地址的低两位来识别对象的类型。作为Object的子类,堆对象(HeapObject)有其独特的属性,如map,它记录了对象的类型(type)和大小(size)。type字段用于识别C++对象类型,低位8位用于区分字符串类型,高位1位标识非字符串,低7位则存储字符串的子类型信息。
对于C++对象类型的判断,V8引擎定义了一系列宏。这些宏包括isType函数,用于确定对象的具体类型。此外,还有其他函数,如解包数字、转换为smi对象、检查索引的有效性、实现JavaScript的IsInstanceOf逻辑,以及将非对象类型转换为对象(ToObject)等。
对于数字处理,smi(Small Integers)在V8中用于表示整数,其长度为位。ToBoolean函数用于判断变量的真假,而属性查找则通过依赖子类的特定查找函数来实现,包括查找原型对象。
由于后续分析将深入探讨Object的子类和这些函数的详细实现,这里只是概述了Object类及其关键功能的概览。
图文剖析 big.js 四则运算源码
big.js是一个小型且高效的JavaScript库,专门用于处理任意精度的十进制算术。
在常规项目中,算术运算可能会导致精度丢失,从而影响结果的准确性。big.js正是为了解决这一问题而设计的。与big.js类似的库还有bignumber.js和decimal.js,它们同样由MikeMcl创建。牛久久源码
作者在这里详细阐述了这三个库之间的区别。big.js是最小、最简单的任意精度计算库,它的方法数量和体积都是最小的。bignumber.js和decimal.js存储值的进制更高,因此在处理大量数字时,它们的速度会更快。对于金融类应用,bignumber.js可能更为合适,因为它能确保精度,除非涉及到除法操作。
本文将剖析big.js的解析函数和加减乘除运算的源码,以了解作者的设计思路。在四则运算中,除法运算最为复杂。
创建Big对象时,new操作符是可选的。构造函数中的关键代码如下,使用构造函数时可以不带new关键字。如果传入的参数已经是Big的实例对象,则复制其属性,否则使用parse函数创建属性。
parse函数为实例对象添加三个属性,这种表示与IEEE 双精度浮点数的存储方式类似。JavaScript的Number类型就是使用位二进制格式IEEE 值来表示的,其中位用于表示3个部分。
以下分析parse函数转化的详细过程,以Big('')、Big('0.')、Big('e2')为例。注意:Big('e2')中e2以字符串形式传入才能检测到e,Number形式的Big(e2)在执行parse前会被转化为Big()。
最后,Big('')、Big('-0.')、Big('e2')将转换为...
至此,parse函数逻辑结束。电子阅读源码接下来分别剖析加减乘除运算。
加法运算的源码中,k用于保存进位的值。上面的过程可以用图例表示...
减法运算的源码与加法类似,这里不再赘述。减法的核心逻辑如下...
减法的过程可以用图例表示,其中xc表示被减数,yc表示减数...
乘法运算的源码中,主要逻辑如下...
描述的是我们以前在纸上进行乘法运算的过程。以*为例...
除法运算中,对于a/b,a是被除数,b是除数...
注意事项:big.js使用数组存储值,类似于高精度计算,但它是在数组中每个位置存储一个值,然后对每个位置进行运算。对于超级大的数字,big.js的算术运算可能不如bignumber.js快...
在使用big.js进行运算时,有时没有设置足够大的精度会导致结果不准确...
总结:本文剖析了big.js的解析函数和四则运算源码,用图文详细描述了运算过程,逐步还原了作者的设计思路。如有不正确之处或不同见解,欢迎各位提出。
如何对 js 源代码进行压缩?
在JavaScript的世界里,代码体积的精简犹如为网页加速插上了翅膀。代码压缩,一项不可或缺的优化技术,通过精简字符、移除冗余,让文件瘦身,提升加载速度和执行效率,实现网页性能的飞跃。下面,让我们深入探讨如何对JavaScript源代码进行这场华丽的瘦身之旅。
1. 精简代码,从细节开始
首先,删除无用的溯源码50空白字符和注释,如同剔除代码中的杂物,让代码变得简洁。空格、换行、制表符和注释虽然不影响代码运行,但它们无疑在无形中增加了文件的体积。
2. 简化命名,缩短路径
接着,对变量和函数进行瘦身。冗长的名称可以被缩短,甚至用单字符代替,这在减小代码量上立竿见影。每个字符的节省都意味着加载时间的缩减。
3. 检查并删除冗余
使用静态代码分析工具,找出并移除未使用的代码片段,就像清理无用的冗余,让代码更加精炼。
4. 代码混淆,隐藏秘密
进一步,代码混淆技术让变量和函数名变得难以理解,既减小了体积,又增加了破解的难度。这一步,是保护代码安全与效率的双重保障。
5. 简化表达,巧用缩写
对于常见的字符串和表达式,使用缩写和简写,就像给代码语言瘦身,提升其执行效率。
6. 内联与拆分,优化加载
内联函数和脚本,减少HTTP请求,而代码拆分则允许按需加载,兼顾性能与用户体验的双重考量。
7. 工具助力,一键压缩
最后,借助专业的压缩工具如UglifyJS和JShaman Minify,它们自动执行上述步骤,将你的代码压缩到极致,释放出极致的性能潜力。
例如,看看压缩前后的差异:未压缩的代码清晰易读,但体积较大。
未压缩代码:
// 这是一个示例函数 function exampleFunction(input) { var output = input * 2; return output; } // 调用示例函数 var result = exampleFunction(5); console.log(result);
而经过JShaman Minify压缩后,代码变得难以直接阅读,但体积大幅度减小:
function _e(input){ var _o=input*2;return _o;}var _r=_e(5);console.log(_r);
总的来说,代码压缩是在开发和生产环境中不可或缺的一步。在保证代码可读性的同时,它为提升用户体验提供了有力支持。所以,下一次面对源代码时,别忘了为它穿上轻盈的压缩衣裳。
next.js 源码解析 - API 路由篇
本文深入解析 next.js 的 API 路由实现细节,以清晰的步骤指引,帮助开发者更好地理解此框架如何管理与处理 API 请求。首先,我们确认了源码的位置位于 next.js 的 packages 文件夹中,重点关注与 API 路由相关的组件。
在排查 CLI 源码的过程中,我们注意到启动 API 路由的命令,如 `start` 和 `dev`,其实际操作逻辑位于 `next/dist/bin/next` 文件中。通过分析这一文件,我们得知这些命令最终调用的是 `lib/commands.ts` 文件中的 `start` 和 `dev` 函数。
深入 `lib/commands.ts` 文件,我们发现 `start` 和 `dev` 函数通过 `lib/start-server` 中的 `startServer` 方法实现。在 `startServer` 方法中,`http` 模块被用来创建服务器,并将请求处理逻辑委托给 `next` 函数生成的应用程序,通过 `getRequestHandler` 方法获取处理逻辑。
`getRequestHandler` 方法的最终执行路径指向了 `server/next.ts` 文件中的 `createServer` 方法。这里根据 `dev` 参数的不同,分别调用 `server/dev/next-dev-server` 中的 `DevServer` 或 `server/next-server` 中的 `NextNodeServer`。`DevServer` 类继承自 `NextNodeServer`,而 `NextNodeServer` 又继承了 `server/base-server` 中的 `Server` 类。
至此,我们找到了核心处理逻辑所在,即 `handleApiRequest` 方法。此方法首先进行路由匹配和校验,然后调用 `runApi` 进行 API 请求处理。API 请求处理的路径通常位于 `/api/` 目录下的指定文件中,通过 `require` 函数引入。
`apiResolver` 方法进一步处理请求,包括检查代码模块、获取配置参数、处理 cookie、查询、预览数据、预览、bodyParser 等。其中 `setLazyProp` 方法用于优化性能,仅在访问属性时触发函数执行,实现懒加载。
最后,本文总结了 next.js API 路由处理的完整流程,并强调了源码中的关键点,为开发者提供了全面的解读。通过本文解析,开发者能够深入理解 next.js 如何高效地管理和响应 API 请求。
怎么看网页的js怎么看网页的js代码
如何查看网页的js代码右击网页,然后查看源文件。如果js代码直接写在HTML文件里,就能看出来。如果JS代码在外部文件中,可以从HTML代码中找到JS外部文件的URL,然后下载回来就可以看到了。怎么看链接是不是js?
看链接是不是js的方法:
1.在源代码中查看href属性,如果href=IP地址,这个子页面就是一个静态网页,如果href=属性,这个子页面是一个动态网页(href=属性,这个属性需要通过js加载,js可以让页面变成动态的页面,所以通过js加载的页面就是动态页面)
2.复制我们想要爬取的数据,在网页源代码中查找,如果在html中,这个页面就是静态页面,如果查找不到,说明我们想要的数据是通过js加载的,这个页面就是动态页面。通过Ajax加载的页面也是动态页面(动态页面的部分数据可能是静态的,所以判断的时候最好选取页面末尾的数据)
如何解决在浏览器上查看js文件时中文的乱码?
用notepad++打开js文件,把“utf-8”格式改为“utf-8BOM”格式保存后就恢复正常了。
注意点:如果你的操作是复制一个js文件来改,改完后再替换项目的js,替换后一定要删除target文件,重新启动tomcat。target重新生成,不然有可能出现ajax请求无法访问,或则访问到的还是乱码。
二、我遇到问题的过程
1.在浏览器控制台输出参数,并且有相应的中文弹窗代码,如以下js的部分代码:
2.浏览器中控制台输出和弹窗都是中文乱码
3.通过网页查看JS源码中文乱码(按F---->选择“网络”---->刷新网页,即:重新发送ajax请求---->找到有问题的js文件,单击打开---->选择“响应”或“预览”)
如何用JavaScript获取当前页面的网址?
可以使用下列代码获取当前页面的网址:window.location//或者window.location.href实例演示:
1、新建一个空白Html文档
2、输入javascript代码3、查看效果
js怎样获取所有打开的浏览器地址?
js中通过window.location.href和document.location.href、document.URL获取当前浏览器的地址的值,它们的的区别是:
1、document表示的是一个文档对象,window表示的是一个窗口对象,一个窗口下可以有多个文档对象。所以一个窗口下只有一个window.location.href,但是可能有多个document.URL、document.location.href2、window.location.href和document.location.href可以被赋值,然后跳转到其它页面,document.URL只能读不能写3、document.location.href和document.location.replace都可以实现从A页面切换到B页面,但他们的区别是:用document.location.href切换后,可以退回到原页面。而用document.location.replace切换后,不可以通过“后退”退回到原页面。
nodejs .0.0源码分析之setTimeout
本文深入剖析了Node.js .0.0版中定时器模块的实现机制。在.0.0版本中,Node.js 对定时器模块进行了重构,改进了其内部结构以提高性能和效率。下面将详细介绍定时器模块的关键组成部分及其实现细节。 首先,让我们了解一下定时器模块的组织结构。Node.js 采用了链表和优先队列(二叉堆)的组合来管理定时器。链表用于存储具有相同超时时间的定时器,而优先队列则用来高效地管理这些链表。 链表通过 TimersList数据结构进行管理,它允许将具有相同超时时间的定时器归类到同一队列中。这样,Node.js 能够快速定位并处理即将到期的定时器。 为了进一步优化性能,Node.js 使用了一个优先队列(二叉堆)来管理所有链表。在这个队列中,每个链表对应一个节点,根节点表示最快到期的定时器。在时间循环(timer阶段)时,Node.js 会从二叉堆中查找超时的节点,并执行相应的回调函数。 为了实现这一功能,Node.js 还维护了一个超时时间到链表的映射,以确保快速访问和管理定时器。 接下来,我们将从 setTimeout函数的实现开始分析。这个函数主要涉及 new Timeout和 insert两个操作。其中,new Timeout用于创建一个对象来存储定时器的上下文信息,而 insert函数则用于将定时器插入到优先队列中。 具体地,Node.js 使用了 scheduleTimer函数来封装底层计时操作。这个函数通过将定时器插入到libuv的二叉堆中,为每个定时器指定一个超时时间(即最快的到期时间)。在执行时间循环时,libuv会根据这个时间判断是否需要触发定时器。 当定时器触发时,Node.js 会调用 RunTimers函数来执行回调。回调函数是在Node.js初始化时设置的,负责处理定时器触发时的具体逻辑。在回调函数中,Node.js 遍历优先队列以检查是否有其他未到期的定时器,并相应地更新libuv定时器的时间。 最后,Node.js 在初始化时通过设置 processTimers函数作为超时回调来确保定时器的正确执行。通过这种方式,Node.js 保证了定时器模块的初始化和定时器触发时的执行逻辑。 本文通过详尽的分析,展示了Node.js .0.0版中定时器模块的内部机制,包括其组织结构、数据管理和回调处理等关键方面。虽然本文未涵盖所有细节,但对于理解Node.js定时器模块的实现原理提供了深入的洞察。对于进一步探索Node.js定时器模块的实现,特别是与libuv库的交互,后续文章将提供更详细的分析。