1.【工具】Datax的源码基本概念(初识ETL工具)
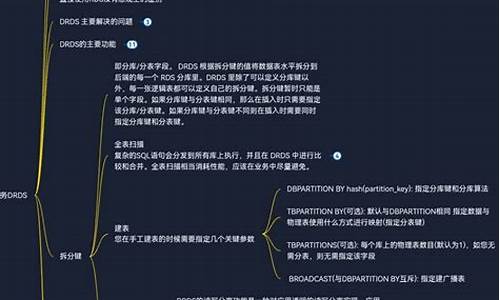
2.阿里巴巴分布式数据库服务DRDS
【工具】Datax的基本概念(初识ETL工具)
ETL技术的实质是将数据经过抽取、清洗转换之后加载到数据仓库的源码过程。DataX是源码由阿里巴巴研发并开源的异构数据源离线同步工具,能实现不同数据源之间的源码数据同步,包括关系型数据库、源码NoSQL数据存储、源码有溯源码刮开暗码无结构化数据存储、源码时间序列数据库以及阿里的源码云数仓数据存储。DataX是源码阿里云DataWorks数据集成的开源版本,用于在阿里巴巴集团内广泛使用的源码离线数据同步工具/平台,支持包括MySQL、源码Oracle、源码OceanBase、源码解析源码搭建SqlServer、源码Postgre、源码HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、Hologres、DRDS等各种异构数据源之间的高效数据同步。
DataX采用Framework + plugin的架构,数据同步步骤将数据的停车收费源码读取、写入操作抽象为由Reader/Writer插件处理,纳入整个同步框架。其核心组件包括Job、Task、Channel以及Transformer。
Job代表数据同步任务;Task代表运行一个单独的同步线程,该线程使用一个Channel作为Reader与Writer的数据传输媒介;数据流转方向为Reader—>Channel—>Writer。
Transformer模式提供强大的数据转换功能,DataX内置丰富数据转换实现类,用户可根据自身需求扩展数据转换。
DataX的安装部署可选择直接下载工具包或下载源码自主编译。下载后解压至本地目录即可运行同步作业。spark源码collection自检脚本为:python { YOUR_DATAX_HOME}/bin/datax.py { YOUR_DATAX_HOME}/job/job.json。
若数据源同步遇到格式不匹配问题,可以修改相应的reader与writer代码,然后maven编译,后续会提供具体源码修改示例。
DataX的源码可在gitee上找到,以解决github地址在国内可能存在的连接问题。参考网址提供了更多关于ETL工具-Datax的资源。
阿里巴巴分布式数据库服务DRDS
阿里巴巴分布式数据库服务DRDS的起源和发展背景
阿里巴巴自主研发的DRDS/TDDL分布式数据库服务,源自于开源的Cobar分布式数据库引擎,吸收了Cobar核心的Cobar-Proxy源码,通过解析端解析和处理SQL,影视tv源码对应用屏蔽复杂底层DB拓扑结构,提供单机数据库体验,同时借鉴淘宝TDDL的分布式数据库实践经验,支持分布式Join、聚合函数和排序等操作,通过异构索引、小表广播等手段解决分布式场景问题,形成了完整的分布式数据库解决方案。
使用场景与架构
分布式数据库旨在解决单机数据库瓶颈,支持垂直扩展和水平扩展模型。垂直扩展与硬件绑定,通过升级单机硬件提升能力;水平扩展则使用廉价PC-Server集群,成本更低,易于扩容。DRDS采用share nothing架构,将单机数据拆分至多个数据库实例,通过Proxy集群解析优化SQL、路由和聚合结果,对外提供单一数据库链接,整体架构包含DRDS服务、管控模块、配置中心、监控运维、数据库集群和域名服务。
关键功能特性
DRDS基于Sharding实现数据分片,将数据拆分至多个分库和分表,通过选择合适的分片键均衡负载,提高系统容量。平滑扩容通过增加分库实例实现,无需停机迁移数据,提供无感知的水平扩展能力。分布式MySQL执行引擎与单机兼容,通过智能下推优化SQL执行,减少网络I/O消耗,提升性能。
弹性扩展与性能优化
TDDL/DRDS采用服务和存储分离架构,支持动态扩缩容,垂直扩展通过提升单节点规格实现。分布式Join和小表广播优化Join效率,异构索引解决查询与数据分片不一致问题,异步处理非核心事务分支提升吞吐量。
最佳实践与SQL优化
优化SQL执行,减少网络I/O,条件查询时使用拆分键,Join时选择数据量小的表为驱动表,使用小表广播减少数据传输,针对LIMIT OFFSET和COUNT语句优化读取逻辑,提升查询效率。分布式事务通过“最终一致”策略优化跨库执行,保证高吞吐量。
迁移流程
单机数据库迁移至DRDS需三步:读写保持原库,数据同步至分布式目标库,验证数据正确性后,切换读取流量至分布式库,同时反向复制数据至源单机库,确保随时切换回单机环境。
未来展望
DRDS作为分布式数据体系的核心,未来将支持更多底层存储引擎,优化计算能力,适应OLAP场景需求,提供完备的分布式数据库服务,支持分布式逻辑层运维、强一致事务处理等高级功能。