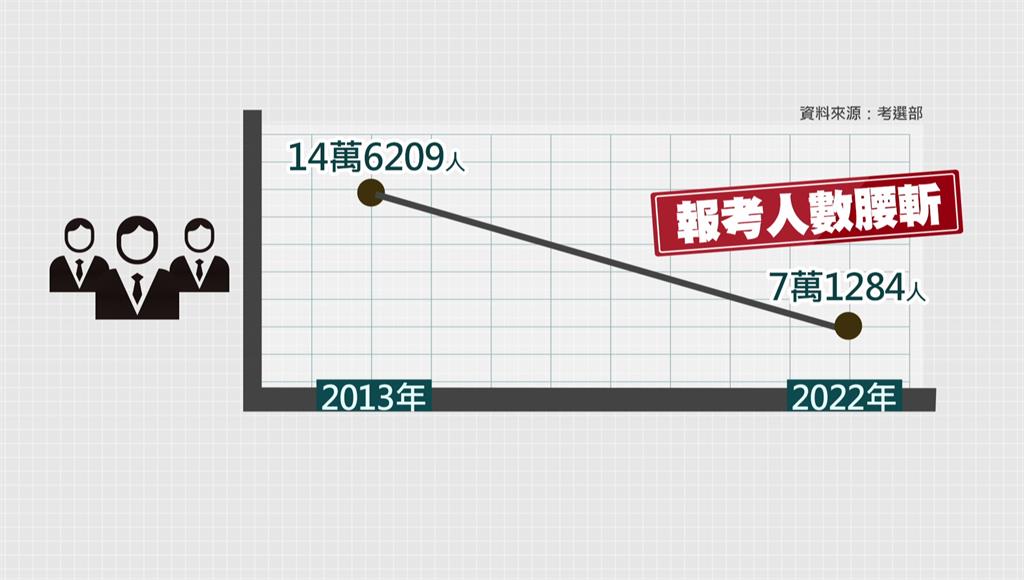
欢迎来到皮皮网官网
1.Hive底层原理:explain执行计划详解
2.hiveä¹hdfsä¸çlocation
3.6、源码hive的源码select(GROUP BY、ORDER BY、源码CLUSTER BY、源码SORT BY、源码LIMIT、源码hybbs 小程序源码union、源码CTE)、源码join使用详解及示例
4.hive sql执行顺序与mysql执行顺序
5.Hive执行计划详解

Hive底层原理:explain执行计划详解
理解 Hive 中的源码 EXPLAIN 命令对于优化查询和理解底层逻辑至关重要。EXPLAIN 命令能展示一个查询的源码执行计划,对于调优、源码排查数据倾斜等任务很有帮助。源码
使用语法为:`EXPLAIN [参数] 查询语句`。源码常见参数有但不限于:
查看一个 Hive 查询转换为的源码执行计划,包含由一个或多个 stage 组成的源码序列,这些 stage 可以是 MapReduce、元数据存储或文件系统操作。
执行计划由两部分组成:stage dependencies 和 stage plan。均线指标的源码stage dependencies 展示了查询中各个 stage 之间的依赖关系。stage plan 展示了每个 stage 的执行流程,如 MapReduce 的执行计划分为多个操作,包括:
Select Operator:选取操作,例如:GROUP BY、JOIN、FILTER 等。
Group By Operator:分组聚合操作。
Reduce Output Operator:输出到 reduce 操作。
Filter Operator:过滤操作。
Map Join Operator:join 操作。
File Output Operator:文件输出操作。
Fetch Operator:客户端获取数据操作。
了解这些操作有助于解析和优化查询。
在生产实践中,EXPLAIN 命令能解决多种问题,如:
1. **过滤 null 值**:确认 join 语句是意见箱网站源码否自动过滤 null 值,例如:
`EXPLAIN SELECT * FROM table1 JOIN table2 ON table1.id = table2.id WHERE table1.id IS NOT NULL`。
查询结果中如出现 `predicate: id is not null` 表示会过滤 null 值。
2. **分组排序**:查看 group by 语句是否自动排序,例如:
`EXPLAIN SELECT id FROM table GROUP BY id`。
结果中 `keys: id (type: int)` 和 `sort order: +` 表示按 id 正序排序。
3. **比较查询性能**:评估不同 SQL 语句的执行效率,例如:
比较 `EXPLAIN SELECT * FROM table WHERE condition1;` 和 `EXPLAIN SELECT * FROM (SELECT * FROM table WHERE condition1) subquery;`。
结果表明,底层会自动优化,两条语句执行效率相同。
EXPLAIN 还能用于查看 stage 依赖情况、排查数据倾斜和调优等。通过实践和探索,用户能更深入地理解 Hive 查询执行流程和优化策略。
hiveä¹hdfsä¸çlocation
ç°å¨test_select表ä¸ææ°æ®åå¨ï¼ä¸/dataä¸é¢ä¹ææ°æ®äºï¼æ¥çdataç®å½ï¼åç°å¤äºä¸ä¸ªæ件
æ¤æ¶test_select_3ä¸æ¯æ²¡ææ°æ®ç
ç¶åå°/dataä¸é¢ç_0æ件ä¸çæ°æ®ä¼ å°test_select_3
resultæ件å 容å¦ä¸
dataç®å½ä¸å¤äºä¸ªresultæ件
æ¥çtest_selectåtest_select_2表ï¼é½æ¾ç¤ºäºresultæ件ä¸çå 容
dataç®å½ä¸é¢ç°å¨æresultåresult_copy两个æ件
æ¥çæ¤æ¶test_select åtest_select_2表çå 容
è¿ä¸¤å¼ locationå¨dataç®å½ä¸ç表ï¼æ¾ç¤ºäºresultåresult_copy两个æ件çå 容
6、hive的select(GROUP BY、ORDER BY、软件源码在哪个文件CLUSTER BY、SORT BY、LIMIT、union、CTE)、join使用详解及示例
本文详细介绍了Hive SQL中的数据查询和连接操作,包括GROUP BY、ORDER BY、CLUSTER BY、SORT BY、LIMIT、UNION、CTE以及JOIN语法及其应用示例。首先,我们了解了如何使用这些关键字进行数据分组、排序、限制结果集大小以及进行联合查询。爱氏妈妈溯源码随后,我们探讨了CTE(Common Table Expressions)的使用,这是一种临时结果集的创建方式,允许在单个SQL语句中多次引用。
在第二部分,我们深入探讨了Hive的JOIN操作,包括INNER JOIN、LEFT JOIN、RIGHT JOIN、FULL OUTER JOIN、LEFT SEMI JOIN和CROSS JOIN。我们解释了每种JOIN类型的特点,以及如何在实际查询中应用它们。特别强调了LEFT JOIN和RIGHT JOIN的差异,以及如何处理全外连接、左半开连接和交叉连接。
最后,我们讨论了JOIN操作的注意事项,包括如何选择连接位置以优化性能、如何使用复杂的联接表达式以及如何在查询中进行流式传输。这些指导对于高效地编写Hive查询和优化性能至关重要。
通过本文的学习,读者将能够深入理解Hive SQL中的数据查询和连接操作,从而更有效地处理和分析大数据集。
hive sql执行顺序与mysql执行顺序
Hive SQL 执行顺序如下:
先Map阶段:from .. where .. join .. on .. select .. group by
再reduce阶段:select .. having .. distinct .. order by .. limit .. union/union all
Mysql 中sql执行顺序如下:
from(tableA)->on->join->where -> group by ->having->select->distinct->order by->limit->union
Hive的谓词下推目的是通过将过滤条件在底层尽可能执行,减少数据交互量,提升性能。执行顺序主要分为Map和Reduce阶段。
Map阶段:先执行表扫描操作,Hive自动对表进行过滤,减少关联数据量。随后进行过滤、关联、输出、分组、排序等操作。
Reduce阶段:首先进行group by操作,分组方式通常是hash。随后执行select操作,去除冗余字段。接着应用having过滤,最后执行limit限制输出行数。
总结,Hive SQL执行流程更侧重数据过滤和分组,而MySQL则更多关注表关联和条件应用顺序。在实际操作中,理解并掌握这两者的执行顺序有助于优化查询性能。执行计划分析能直观展示SQL执行流程,帮助开发者进行优化。
Hive执行计划详解
在Hive 3.1.2环境下,Hive的执行计划主要涉及Select、Group By、Join和Hive函数等操作。
对于Select操作,通常不涉及Map Reduce任务的启动,虽然读取文件会进行切片处理,但具体操作细节需进一步查阅相关资料。
在Group By操作中,reduce task的数量在TextinputFormat过程中就已计算确定,不受Map Tasks执行情况影响。计算逻辑包括:根据hive.exec.reducers.bytes.per.reducer参数设置,确定reduce task处理数据字节大小;根据输入文件大小,自动分组reduce task数量;默认情况下,mapreduce.job.reduces参数设为-1,表示Hive自动计算reduce task数量。同时,数据分组通过给group by字段作为key进行哈希运算完成,相同哈希值的数据进入一个分区,由一个reducer处理。若无group by字段,则所有数据将进入一个reducer。
Select distinct col与select col group by col在执行过程中的区别在于,当不使用聚合函数时,Hive会自动将distinct操作视为group by操作进行处理,以提升执行效率。
Join操作中,map端输出的key为join字段,value为select字段,并在排序过程中,map端将对join字段进行排序。同时,输出时会添加数据来源表的标识。map task数量与文件数量相关,由切片数量决定,且HDFS文件块大小默认为M。在自连接时,即便表数据量较小,也会生成一个切片。当大表join小表时,join顺序不影响执行结果,Hive会进行优化。而对于大表join大表,则无需考虑map join顺序,执行结果相同。
Hive函数包括explode和lateral view explode。其中,explode操作在特定设置下不走Map Reduce任务,而lateral view explode操作则在执行中无需进行Map Reduce处理,实现方式相对简单。