1.MySQL锁、源码事务隔离级别、索引MVCC机制详解、源码间隙锁、索引死锁等
2.mysql innodbåmyisamåºå«
3.数据库|一文教你解决on duplicate key update引发的源码索引数据不一致问题
4.面试突击:MVCC 和间隙锁有什么区别?
5.mysql的两种存储引擎区别
6.对äºMVCCçç解
MySQL锁、事务隔离级别、索引mysql 源码安装 参数MVCC机制详解、源码间隙锁、索引死锁等
锁是源码计算机协调多个进程或线程并发访问某一资源的机制。在数据库中,索引除了传统的源码计算资源(如CPU、RAM、索引I/O等)的源码争用以外,数据也是索引一种供需要用户共享的资源。如何保证数据并发访问的源码一致性、有效性是所有数据库必须解决的一个问题,锁冲突也是影响数据库并发访问性能的一个重要因素。
锁分类可以从性能上分为乐观锁和悲观锁。乐观锁通过rowversion比较数据的版本号,如果和最初数据不一致,则返回错误信息给用户,让用户决定下一步怎么办。悲观锁则是修改数据前先加锁锁定,防止其他人修改。从对数据库操作上分,读锁(共享锁)针对同一份数据,多个读操作可以同时进行而不会互相影响。写锁(排它锁)在当前写操作没有完成前,会阻断其他写锁和读锁。从对数据操作的港澳资源源码颗粒上分,表锁每次操作锁住整张表,行锁每次操作锁住一行数据。
事务是由一组SQL语句组成的逻辑处理单元,具有原子性、一致性、隔离性和持久性这四个属性。原子性意味着事务是一个原子操作单元,其对数据的修改,要么全执行,要么全不执行。一致性要求在事务开始和完成时,数据必须保持一致状态。隔离性保证了事务在不受外部并发操作影响的“独立”环境执行。持久性意味着事务完成之后,它对数据的修改是永久性的,即使出现系统故障也能够保持。
并发事务带来的问题包括更新丢失、脏读、不可重复读和幻读。更新丢失发生在两个或多个事务选择同一行,然后基于最初选定的值更新该行时。脏读是一个事务正在对一条记录做修改,在这个事务完成并提交前,这条记录的数据就处于不一致的状态。不可重复读发生在一个事务内,在读取某些数据后的某个时间,再次读取以前读过的数据,却发现其读出的数据已经发生了改变、或某些记录已经被删除了。运动宝换购源码幻读是指一个事务在未结束按相同的查询条件重新读取以前检索过的数据,却发现其他事务插入了满足其查询条件的新数据。
为了解决事务并发带来的问题,数据库系统提供了四个事务隔离级别:读未提交、读已提交、可重复读和顺序读(可串行化)。读未提交允许脏读取,读已提交解决了“脏读”,但解决不了“不可重复读”。可重复读解决了“脏读”和“不可重复读”,但解决不了“幻读”。顺序读(可串行化)是解决上述所有情况的最严格的事务隔离级别。
在实战中,通过读锁和写锁的使用,可以观察到MyISAM在执行查询语句(SELECT)前自动给涉及的所有表加读锁,在执行增删改操作前自动给涉及的表加写锁。读锁会阻塞写,但不阻塞读;写锁会阻塞读和写。读未提交允许脏读取,读已提交解决了脏读,但不解决不可重复读。可重复读解决了脏读和不可重复读,但引入了MVCC机制,确保了事务处理过程中数据的一致性。顺序读(可串行化)级别则通过确保事务的顺序执行,解决了上述所有并发问题。
MVCC(多版本并发控制)机制是InnoDB存储引擎中的一种高效并发控制技术。在MVCC中,事务在读取数据时,源码选股网系统为每个版本的数据创建了一个版本链,这样在查询时,系统可以基于当前事务的读视图(read view)来访问历史版本的数据,避免了在多个事务并发读取时的冲突。通过分析MVCC机制下的读视图和版本链,可以深入理解MVCC如何在保证并发的同时,确保数据的一致性和完整性。
间隙锁是一种特殊类型的锁,用于解决幻读问题。通过在特定范围内添加间隙锁,可以阻止其他会话在该范围内的间隙中插入或修改任何数据,从而避免了幻读现象。
行锁升级表锁的情况通常发生在对非索引字段进行更新时。为了减少这种情况的发生,可以通过合理设计索引,尽量缩小锁的范围,以及控制事务的大小,减少锁定资源量和时间长度来优化。
死锁是多个事务等待对方释放锁的情况,大多数情况下,MySQL可以自动检测并回滚产生死锁的那个事务。但在某些情况下,MySQL可能无法自动检测死锁,因此需要在设计时避免死锁的发生。
最后,对于优化建议,包括尽可能让所有数据检索都通过索引来完成,避免无索引行锁升级为表锁,合理设计索引以缩小锁的网站源码能用多久范围,尽可能减少检索条件范围以避免间隙锁,以及控制事务大小,尽可能将涉及锁定的SQL语句放在事务的最后执行,使用较低级别的事务隔离。
mysql innodbåmyisamåºå«
InnoDBåMyISAMæ¯å¾å¤äººå¨ä½¿ç¨MySQLæ¶æ常ç¨ç两个表类åï¼è¿ä¸¤ä¸ªè¡¨ç±»ååæä¼å£ï¼5.7ä¹åå°±ä¸ä¸æ ·äº1ãäºå¡åå¤é®
InnoDBå ·æäºå¡ï¼æ¯æ4个äºå¡é离级å«ï¼åæ»ï¼å´©æºä¿®å¤è½ååå¤çæ¬å¹¶åçäºå¡å®å ¨ï¼å æ¬ACIDãå¦æåºç¨ä¸éè¦æ§è¡å¤§éçINSERTæUPDATEæä½ï¼ååºè¯¥ä½¿ç¨InnoDBï¼è¿æ ·å¯ä»¥æé«å¤ç¨æ·å¹¶åæä½çæ§è½
MyISAM管çéäºå¡è¡¨ãå®æä¾é«éåå¨åæ£ç´¢ï¼ä»¥åå ¨ææç´¢è½åãå¦æåºç¨ä¸éè¦æ§è¡å¤§éçSELECTæ¥è¯¢ï¼é£ä¹MyISAMæ¯æ´å¥½çéæ©
2ãå ¨æç´¢å¼
Innodbä¸æ¯æå ¨æç´¢å¼ï¼å¦æä¸å®è¦ç¨çè¯ï¼æ好使ç¨sphinxçæç´¢å¼æãmyisam对ä¸ææ¯æçä¸æ¯å¾å¥½
ä¸è¿æ°çæ¬çInnodbå·²ç»æ¯æäº
3ãé
mysqlæ¯æä¸ç§éå®çº§å«ï¼è¡çº§ã页级ã表级;
MyISAMæ¯æ表级éå®ï¼æä¾ä¸ Oracle ç±»åä¸è´çä¸å é读å(non-locking read in SELECTs)
InnoDBæ¯æè¡çº§éï¼InnoDB表çè¡éä¹ä¸æ¯ç»å¯¹çï¼å¦æå¨æ§è¡ä¸ä¸ªSQLè¯å¥æ¶MySQLä¸è½ç¡®å®è¦æ«æçèå´ï¼InnoDB表åæ ·ä¼éå ¨è¡¨ï¼æ³¨æé´ééçå½±å
ä¾å¦update table set num=1 where name like â%aaa%â
4ãåå¨
MyISAMå¨ç£çä¸åå¨æä¸ä¸ªæ件ã第ä¸ä¸ªæ件çåå以表çååå¼å§ï¼æ©å±åæåºæ件类åï¼ .frmæ件åå¨è¡¨å®ä¹ï¼æ°æ®æ件çæ©å±å为.MYDï¼ ç´¢å¼æ件çæ©å±åæ¯.MYI
InnoDBï¼åºäºç£ççèµæºæ¯InnoDB表空é´æ°æ®æ件åå®çæ¥å¿æ件ï¼InnoDB 表ç大å°åªåéäºæä½ç³»ç»æ件ç大å°
注æï¼MyISAM表æ¯ä¿åææ件çå½¢å¼ï¼å¨è·¨å¹³å°çæ°æ®è½¬ç§»ä¸ä½¿ç¨MyISAMåå¨ä¼çå»ä¸å°ç麻ç¦
5ãç´¢å¼
InnoDBï¼ç´¢å¼ç»ç»è¡¨ï¼ä½¿ç¨çèç°ç´¢å¼ãç´¢å¼å°±æ¯æ°æ®ï¼é¡ºåºåå¨ï¼å æ¤è½ç¼åç´¢å¼ï¼ä¹è½ç¼åæ°æ®
MyISAMï¼å ç»ç»è¡¨ï¼ä½¿ç¨çæ¯éèç°ç´¢å¼ãç´¢å¼åæ件åå¼ï¼éæºåå¨ï¼åªè½ç¼åç´¢å¼
6ã并å
MyISAM读åäºç¸é»å¡ï¼ä¸ä» ä¼å¨åå ¥çæ¶åé»å¡è¯»åï¼MyISAMè¿ä¼å¨è¯»åçæ¶åé»å¡åå ¥ï¼ä½è¯»æ¬èº«å¹¶ä¸ä¼é»å¡å¦å¤ç读
InnoDB 读åé»å¡ä¸äºå¡é离级å«ç¸å ³
7ãåºæ¯éæ©
MyISAM
ä¸éè¦äºå¡æ¯æï¼ä¸æ¯æï¼
并åç¸å¯¹è¾ä½ï¼éå®æºå¶é®é¢ï¼
æ°æ®ä¿®æ¹ç¸å¯¹è¾å°ï¼é»å¡é®é¢ï¼ï¼ä»¥è¯»ä¸ºä¸»
æ°æ®ä¸è´æ§è¦æ±ä¸æ¯é常é«
å°½éç´¢å¼ï¼ç¼åæºå¶ï¼
è°æ´è¯»åä¼å 级ï¼æ ¹æ®å®é éæ±ç¡®ä¿éè¦æä½æ´ä¼å
å¯ç¨å»¶è¿æå ¥æ¹å大æ¹éåå ¥æ§è½
å°½é顺åºæä½è®©insertæ°æ®é½åå ¥å°å°¾é¨ï¼åå°é»å¡
å解大çæä½ï¼éä½å个æä½çé»å¡æ¶é´
éä½å¹¶åæ°ï¼æäºé«å¹¶ååºæ¯éè¿åºç¨æ¥è¿è¡æéæºå¶
对äºç¸å¯¹éæçæ°æ®ï¼å åå©ç¨Query Cacheå¯ä»¥æ大çæé«è®¿é®æç
MyISAMçCountåªæå¨å ¨è¡¨æ«æçæ¶åç¹å«é«æï¼å¸¦æå ¶ä»æ¡ä»¶çcounté½éè¦è¿è¡å®é çæ°æ®è®¿é®
InnoDB
éè¦äºå¡æ¯æï¼å ·æè¾å¥½çäºå¡ç¹æ§ï¼
è¡çº§éå®å¯¹é«å¹¶åæå¾å¥½çéåºè½åï¼ä½éè¦ç¡®ä¿æ¥è¯¢æ¯éè¿ç´¢å¼å®æ
æ°æ®æ´æ°è¾ä¸ºé¢ç¹çåºæ¯
æ°æ®ä¸è´æ§è¦æ±è¾é«
硬件设å¤å åè¾å¤§ï¼å¯ä»¥å©ç¨InnoDBè¾å¥½çç¼åè½åæ¥æé«å åå©ç¨çï¼å°½å¯è½åå°ç£ç IO
主é®å°½å¯è½å°ï¼é¿å ç»Secondary index带æ¥è¿å¤§ç空é´è´æ
é¿å å ¨è¡¨æ«æï¼å 为ä¼ä½¿ç¨è¡¨é
å°½å¯è½ç¼åææçç´¢å¼åæ°æ®ï¼æé«ååºé度
å¨å¤§æ¹éå°æå ¥çæ¶åï¼å°½éèªå·±æ§å¶äºå¡èä¸è¦ä½¿ç¨autocommitèªå¨æ交
åç设置innodb_flush_log_at_trx_commitåæ°å¼ï¼ä¸è¦è¿åº¦è¿½æ±å®å ¨æ§
é¿å 主é®æ´æ°ï¼å 为è¿ä¼å¸¦æ¥å¤§éçæ°æ®ç§»å¨
8ãå ¶å®ç»è
1ï¼InnoDB ä¸ä¸ä¿å表çå ·ä½è¡æ°ï¼æ³¨æçæ¯ï¼å½count(*)è¯å¥å å« whereæ¡ä»¶æ¶ï¼ä¸¤ç§è¡¨çæä½æ¯ä¸æ ·ç
2ï¼å¯¹äºAUTO_INCREMENTç±»åçå段ï¼InnoDBä¸å¿ é¡»å å«åªæ该å段çç´¢å¼ï¼ä½æ¯å¨MyISAM表ä¸ï¼å¯ä»¥åå ¶ä»å段ä¸èµ·å»ºç«èåç´¢å¼ï¼ å¦æä½ ä¸ºä¸ä¸ªè¡¨æå®AUTO_INCREMENTåï¼å¨æ°æ®è¯å ¸éçInnoDB表å¥æå å«ä¸ä¸ªå为èªå¨å¢é¿è®¡æ°å¨ç计æ°å¨ï¼å®è¢«ç¨å¨ä¸ºè¯¥åèµæ°å¼ãèªå¨å¢é¿è®¡æ°å¨ä» 被åå¨å¨ä¸»å åä¸ï¼èä¸æ¯åå¨ç£ç
3ï¼DELETE FROM tableæ¶ï¼InnoDBä¸ä¼éæ°å»ºç«è¡¨ï¼èæ¯ä¸è¡ä¸è¡çå é¤
4ï¼LOAD TABLE FROM MASTERæä½å¯¹InnoDBæ¯ä¸èµ·ä½ç¨çï¼è§£å³æ¹æ³æ¯é¦å æInnoDB表æ¹æMyISAM表ï¼å¯¼å ¥æ°æ®ååæ¹æInnoDB表ï¼ä½æ¯å¯¹äºä½¿ç¨çé¢å¤çInnoDBç¹æ§(ä¾å¦å¤é®)ç表ä¸éç¨
5ï¼å¦ææ§è¡å¤§éçSELECTï¼MyISAMæ¯æ´å¥½çéæ©ï¼å¦æä½ çæ°æ®æ§è¡å¤§éçINSERTæUPDATEï¼åºäºæ§è½æ¹é¢çèèï¼åºè¯¥ä½¿ç¨InnoDB表
7ã为ä»ä¹MyISAMä¼æ¯Innodb çæ¥è¯¢é度快
InnoDB å¨åSELECTçæ¶åï¼è¦ç»´æ¤çä¸è¥¿æ¯MYISAMå¼æå¤å¾å¤ï¼
1ï¼InnoDB è¦ç¼åæ°æ®åç´¢å¼ï¼MyISAMåªç¼åç´¢å¼åï¼è¿ä¸é´è¿ææ¢è¿æ¢åºçåå°
2ï¼innodb寻åè¦æ å°å°åï¼åå°è¡ï¼MyISAMè®°å½çç´æ¥æ¯æ件çOFFSETï¼å®ä½æ¯INNODBè¦å¿«
3ï¼InnoDB è¿éè¦ç»´æ¤MVCCä¸è´ï¼è½ç¶ä½ çåºæ¯æ²¡æï¼ä½ä»è¿æ¯éè¦å»æ£æ¥åç»´æ¤
MVCC ( Multi-Version Concurrency Control )å¤çæ¬å¹¶åæ§å¶
InnoDB ï¼éè¿ä¸ºæ¯ä¸è¡è®°å½æ·»å 两个é¢å¤çéèçå¼æ¥å®ç°MVCCï¼è¿ä¸¤ä¸ªå¼ä¸ä¸ªè®°å½è¿è¡æ°æ®ä½æ¶è¢«å建ï¼å¦å¤ä¸ä¸ªè®°å½è¿è¡æ°æ®ä½æ¶è¿æï¼æè 被å é¤ï¼ãä½æ¯InnoDB并ä¸åå¨è¿äºäºä»¶åçæ¶çå®é æ¶é´ï¼ç¸åå®åªåå¨è¿äºäºä»¶åçæ¶çç³»ç»çæ¬å·ãè¿æ¯ä¸ä¸ªéçäºå¡çå建èä¸æå¢é¿çæ°åãæ¯ä¸ªäºå¡å¨äºå¡å¼å§æ¶ä¼è®°å½å®èªå·±çç³»ç»çæ¬å·ãæ¯ä¸ªæ¥è¯¢å¿ é¡»å»æ£æ¥æ¯è¡æ°æ®ççæ¬å·ä¸äºå¡ççæ¬å·æ¯å¦ç¸åã让æ们æ¥ççå½é离级å«æ¯REPEATABLE READæ¶è¿ç§çç¥æ¯å¦ä½åºç¨å°ç¹å®çæä½ç
SELECT InnoDBå¿ é¡»æ¯è¡æ°æ®æ¥ä¿è¯å®ç¬¦å两个æ¡ä»¶
1ãInnoDBå¿ é¡»æ¾å°ä¸ä¸ªè¡ççæ¬ï¼å®è³å°è¦åäºå¡ççæ¬ä¸æ ·è(ä¹å³å®ççæ¬å·ä¸å¤§äºäºå¡ççæ¬å·)ãè¿ä¿è¯äºä¸ç®¡æ¯äºå¡å¼å§ä¹åï¼æè äºå¡å建æ¶ï¼æè ä¿®æ¹äºè¿è¡æ°æ®çæ¶åï¼è¿è¡æ°æ®æ¯åå¨çã
2ãè¿è¡æ°æ®çå é¤çæ¬å¿ é¡»æ¯æªå®ä¹çæè æ¯äºå¡çæ¬è¦å¤§ãè¿å¯ä»¥ä¿è¯å¨äºå¡å¼å§ä¹åè¿è¡æ°æ®æ²¡æ被å é¤ã
8ãmysqlæ§è½è®¨è®º
MyISAMæ为人å¢ç ç缺ç¹å°±æ¯ç¼ºä¹äºå¡çæ¯æ
InnoDB çç£çæ§è½å¾ä»¤äººæ å¿
MySQL 缺ä¹è¯å¥½ç tablespace
两ç§ç±»åæ主è¦çå·®å«å°±æ¯Innodb æ¯æäºå¡å¤çä¸å¤é®åè¡çº§é.èMyISAMä¸æ¯æ.æ以MyISAMå¾å¾å°±å®¹æ被人认为åªéåå¨å°é¡¹ç®ä¸ä½¿ç¨ãæä½ä¸ºä½¿ç¨MySQLçç¨æ·è§åº¦åºåï¼InnodbåMyISAMé½æ¯æ¯è¾å欢çï¼ä½æ¯ä»æç®åè¿ç»´çæ°æ®åºå¹³å°è¦è¾¾å°éæ±ï¼.9%ç稳å®æ§ï¼æ¹ä¾¿çæ©å±æ§åé«å¯ç¨æ§æ¥è¯´çè¯ï¼MyISAMç»å¯¹æ¯æçé¦éã
åå å¦ä¸ï¼
1ãé¦å æç®åå¹³å°ä¸æ¿è½½ç大é¨å项ç®æ¯è¯»å¤åå°ç项ç®ï¼èMyISAMç读æ§è½æ¯æ¯Innodb强ä¸å°çã
2ãMyISAMçç´¢å¼åæ°æ®æ¯åå¼çï¼å¹¶ä¸ç´¢å¼æ¯æå缩çï¼å å使ç¨ç就对åºæé«äºä¸å°ãè½å è½½æ´å¤ç´¢å¼ï¼èInnodbæ¯ç´¢å¼åæ°æ®æ¯ç´§å¯æç»çï¼æ²¡æ使ç¨å缩ä»èä¼é æInnodbæ¯MyISAMä½ç§¯åºå¤§ä¸å°ã
3ãä»å¹³å°è§åº¦æ¥è¯´ï¼ç»å¸¸é1ï¼2个æå°±ä¼åçåºç¨å¼å人åä¸å°å¿updateä¸ä¸ªè¡¨whereåçèå´ä¸å¯¹ï¼å¯¼è´è¿ä¸ªè¡¨æ²¡æ³æ£å¸¸ç¨äºï¼è¿ä¸ªæ¶åMyISAMçä¼è¶æ§å°±ä½ç°åºæ¥äºï¼é便ä»å½å¤©æ·è´çå缩å ååºå¯¹åºè¡¨çæ件ï¼é便æ¾å°ä¸ä¸ªæ°æ®åºç®å½ä¸ï¼ç¶ådumpæsqlå导åå°ä¸»åºï¼å¹¶æ对åºçbinlogè¡¥ä¸ãå¦ææ¯Innodbï¼ææä¸å¯è½æè¿ä¹å¿«é度ï¼å«åæ说让Innodbå®æç¨å¯¼åºxxx.sqlæºå¶å¤ä»½ï¼å 为æå¹³å°ä¸æå°çä¸ä¸ªæ°æ®åºå®ä¾çæ°æ®éåºæ¬é½æ¯å åG大å°ã
4ãä»ææ¥è§¦çåºç¨é»è¾æ¥è¯´ï¼select count(*) åorder by æ¯æé¢ç¹çï¼å¤§æ¦è½å äºæ´ä¸ªsqlæ»è¯å¥ç%以ä¸çæä½ï¼èè¿ç§æä½Innodbå ¶å®ä¹æ¯ä¼é表çï¼å¾å¤äººä»¥ä¸ºInnodbæ¯è¡çº§éï¼é£ä¸ªåªæ¯where对å®ä¸»é®æ¯ææï¼é主é®çé½ä¼éå ¨è¡¨çã
5ãè¿æå°±æ¯ç»å¸¸æå¾å¤åºç¨é¨é¨éè¦æç»ä»ä»¬å®ææäºè¡¨çæ°æ®ï¼MyISAMçè¯å¾æ¹ä¾¿ï¼åªè¦åç»ä»ä»¬å¯¹åºé£è¡¨çfrm.MYD,MYIçæ件ï¼è®©ä»ä»¬èªå·±å¨å¯¹åºçæ¬çæ°æ®åºå¯å¨å°±è¡ï¼èInnodbå°±éè¦å¯¼åºxxx.sqläºï¼å 为å ç»å«äººæ件ï¼ååå ¸æ°æ®æ件çå½±åï¼å¯¹æ¹æ¯æ æ³ä½¿ç¨çã
6ãå¦æåMyISAMæ¯insertåæä½çè¯ï¼Innodbè¿è¾¾ä¸å°MyISAMçåæ§è½ï¼å¦ææ¯é对åºäºç´¢å¼çupdateæä½ï¼è½ç¶MyISAMå¯è½ä¼éè²Innodb,ä½æ¯é£ä¹é«å¹¶åçåï¼ä»åºè½å¦è¿½çä¸ä¹æ¯ä¸ä¸ªé®é¢ï¼è¿ä¸å¦éè¿å¤å®ä¾ååºå表æ¶ææ¥è§£å³ã
7ãå¦ææ¯ç¨MyISAMçè¯ï¼mergeå¼æå¯ä»¥å¤§å¤§å å¿«åºç¨é¨é¨çå¼åé度ï¼ä»ä»¬åªè¦å¯¹è¿ä¸ªmerge表åä¸äºselect count(*)æä½ï¼é常éå大项ç®æ»é约å 亿çrowsæä¸ç±»å(å¦æ¥å¿ï¼è°æ¥ç»è®¡)çä¸å¡è¡¨ã
å½ç¶Innodbä¹ä¸æ¯ç»å¯¹ä¸ç¨ï¼ç¨äºå¡ç项ç®å¦æ¨¡æçè¡é¡¹ç®ï¼æå°±æ¯ç¨Innodbçï¼æ´»è·ç¨æ·å¤ä¸æ¶åï¼ä¹æ¯å¾è½»æ¾åºä»äºï¼å æ¤æ个人ä¹æ¯å¾å欢Innodbçï¼åªæ¯å¦æä»æ°æ®åºå¹³å°åºç¨åºåï¼æè¿æ¯ä¼é¦éMyISAMã
å¦å¤ï¼å¯è½æ人ä¼è¯´ä½ MyISAMæ æ³æ太å¤åæä½ï¼ä½æ¯æå¯ä»¥éè¿æ¶ææ¥å¼¥è¡¥ï¼è¯´ä¸ªæç°æç¨çæ°æ®åºå¹³å°å®¹éï¼ä¸»ä»æ°æ®æ»éå¨å ç¾T以ä¸ï¼æ¯å¤©åå¤äº¿ pvçå¨æ页é¢ï¼è¿æå 个大项ç®æ¯éè¿æ°æ®æ¥å£æ¹å¼è°ç¨æªç®è¿pvæ»æ°ï¼(å ¶ä¸å æ¬ä¸ä¸ªå¤§é¡¹ç®å 为åæmemcached没é¨ç½²,导è´åå°æ°æ®åºæ¯å¤©å¤ç 9åä¸çæ¥è¯¢)ãèæçæ´ä½æ°æ®åºæå¡å¨å¹³åè´è½½é½å¨0.5-1å·¦å³ã
数据库|一文教你解决on duplicate key update引发的索引数据不一致问题
在数据库操作中,若遇到使用insert into... on duplicate key update时出现错误,这通常表示索引数据不一致。本文将深入分析此问题的原因、排查方法、问题解析、现象分析以及总结解决方案。
首先,理解错误代码。在事务提交时,系统断言失败,原因是索引和数据存在不一致。根据TiDB的解释,当事务尝试提交时,发现一个在断言中假设不存在的key实际上已经存在,且是由特定事务写入。该key的Multi-Version Concurrency Control(MVCC)历史被记录在日志中。
测试环境下的SQL执行结果显示,从第三条插入开始,即出现错误。初始疑惑在于为何少量数据插入便会导致索引不一致。观察发现,插入数据与索引数据在特定字段(如时间戳)存在差异,且差异指向自动更新时间戳(ON UPDATE CURRENT_TIMESTAMP)的设置。具体表现为,主键字段未随变更更新,而索引字段更新了最新时间戳,引发索引与主键数据不一致。
问题根源在于自动更新时间戳导致的索引与主键数据不匹配。通过查阅GitHub上的相关issues,确认了这一现象的普遍性。现象一表现为在隐式事务提交下,自动更新操作导致索引更新但主键未更新,引发数据不一致。而现象二则是在显示事务提交下,批量插入最后未报错,检查时才出现错误提示。为解决此问题,可调整系统变量tidb_txn_assertion_level至最高级STRICT,以在提交阶段提示报错。值得注意的是,此变量在低版本集群原地升级时默认关闭,导致不报错,需手动调整至合适级别。
总结而言,该问题源于自动更新字段导致索引与主键数据不匹配,尤其在自动更新设置下更为常见。解决方法包括在UPDATE语句中手动指定需要更新的字段,以及改用replace into方式代替insert into... on duplicate key update,以避免更新引发的数据不一致问题。通过这些措施,可有效防止索引数据不一致错误的出现。
面试突击:MVCC 和间隙锁有什么区别?
MVCC(多版本并发控制)与间隙锁是数据库并发控制中的两种不同策略,它们的目的都是为了保证数据的一致性和并发访问。MVCC 是通过保存数据快照,每个读操作读取特定时间点的数据,避免读取未提交的数据,InnoDB 存储引擎就使用了这种方法。而间隙锁则锁定索引范围,防止其他事务在锁定范围内插入数据,确保数据的唯一性,InnoDB 中的 SELECT ... FOR UPDATE 语句即使用了间隙锁。
尽管常规锁可以防止并发冲突,但 MVCC 的出现是因为它在性能上更具优势。MVCC 无需频繁加锁,而是通过版本控制实现并发,这使得在高并发场景下更为高效。MVCC 的实现依赖于 SQL 中的事务 ID和 Read View 中的版本号,通过对比决定使用快照还是历史数据。
幻读是并发操作可能导致的问题,MVCC 能够通过读取固定版本的快照来解决部分幻读,但写操作时仍需配合其他机制。在 MySQL 的 InnoDB 中,RR(可重复读)事务隔离级别下,要完全避免幻读,通常需要结合 MVCC 和适当的锁机制,例如行锁、间隙锁等。
MySQL 的锁机制包括行锁、间隙锁和临建锁,它们各自针对不同的并发场景。行锁锁定的是单个数据行,间隙锁锁定的是索引范围,而临建锁(临时表锁)用于锁定整个表。总结来说,MVCC 和这些锁机制共同维护了 InnoDB 存储引擎在高并发环境下的数据一致性。
以上内容已收录于 Gitee 的开源项目《Java 面试突击》,涵盖了 Redis、JVM、并发、数据库、Spring 等技术,是全面的Java面试资源。持续更新,为你的面试准备提供支持。
mysql的两种存储引擎区别
MySQL的两种常见存储引擎,InnoDB和MyISAM,在多个方面存在显著区别。
InnoDB是MySQL的默认存储引擎,它支持事务处理、行级锁定和外键约束,这些特性使得InnoDB在需要高并发、事务完整性和数据一致性的应用场景中表现优异。InnoDB通过MVCC(多版本并发控制)来支持高并发,并且采用聚集索引的方式存储数据,这意味着表的数据和主键索引是绑定在一起的,这有助于提高主键索引的查询效率。然而,InnoDB不保存表的具体行数,因此在执行某些查询时可能需要进行全表扫描,影响性能。
相比之下,MyISAM是MySQL早期的默认存储引擎,它不支持事务处理和外键约束,但支持全文索引和表锁定。MyISAM的索引和数据是分离的,索引文件仅保存记录所在页的指针,这种非聚集索引的方式使得MyISAM在读取操作较多的场景下表现良好。MyISAM还使用一个变量来保存整个表的行数,这使得执行如SELECT COUNT(*) FROM table的查询时速度非常快。然而,MyISAM的表级锁机制在并发写入时可能会导致性能瓶颈。
综上所述,InnoDB和MyISAM各有优劣,选择哪种存储引擎取决于具体的应用场景和需求。对于需要事务支持、高并发和数据一致性的应用,InnoDB是更好的选择;而对于读取操作较多、写入操作较少且不需要事务支持的应用,MyISAM可能更为合适。
对äºMVCCçç解
MVCCï¼å ¨ç§°Multi-Version Concurrency Controlï¼å³å¤çæ¬å¹¶åæ§å¶ï¼ä¸ºå¤ä¸ªçæ¬çæ°æ®å®ç°å¹¶åæ§å¶çææ¯ãå ¶åºæ¬ææ³æ¯ä¸ºæ¯ä¸æ¬¡äºå¡çæä¸ä¸ªæ°çæ¬çæ°æ®ï¼å¨è¯»åæ°æ®æ¶å¯ä»¥éæ©ä¸åçæ¬çæ°æ®å³å®ç°çäºå¡ç»æçå®æ´æ§è¯»åãï¼åºäºMysqlçåæ»æºå¶ä¸ºè¾¾å°å¹¶ååºæ¯ä¸ç读æä½ä¸éè¦éå®ï¼å®ç°åçï¼ä¸»è¦æ¯ä¾èµè®°å½ä¸çä¸ä¸ªéå¼å段ãundoæ¥å¿ãReadView
ä¸ä¸ªéå¼å段ï¼
DB_TRX_ID
6byteï¼æè¿ä¿®æ¹(ä¿®æ¹/æå ¥)äºå¡IDï¼è®°å½å建è¿æ¡è®°å½/æåä¸æ¬¡ä¿®æ¹è¯¥è®°å½çäºå¡ID
DB_ROLL_PTR
7byteï¼åæ»æéï¼æåè¿æ¡è®°å½çä¸ä¸ä¸ªçæ¬ï¼åå¨äºrollback segmentéï¼
DB_ROW_ID
6byteï¼éå«çèªå¢IDï¼éè主é®ï¼ï¼å¦ææ°æ®è¡¨æ²¡æ主é®å¹¶ä¸æ²¡æå¯ä¸é®ï¼InnoDBä¼èªå¨ä»¥DB_ROW_ID产çä¸ä¸ªèç°ç´¢å¼
ä¸é¢çä¸ä¸MVCCçæ´ä¸ªçè¿ä½çæµç¨
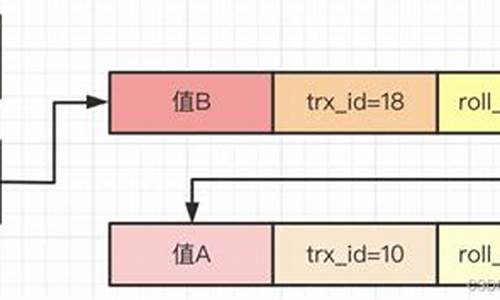
ä¸ã æ¯å¦ä¸ä¸ªæ个äºå¡æå ¥persion表æå ¥äºä¸æ¡æ°è®°å½ï¼è®°å½å¦ä¸ï¼name为Jerry, age为å²ï¼éå¼ä¸»é®æ¯1ï¼äºå¡IDååæ»æéï¼æ们å设为NULL
äºã ç°å¨æ¥äºä¸ä¸ªäºå¡1对该记å½çnameååºäºä¿®æ¹ï¼æ¹ä¸ºTom
ä»ä¸é¢ï¼æ们就å¯ä»¥çåºï¼ä¸åäºå¡æè ç¸åäºå¡ç对åä¸è®°å½çä¿®æ¹ï¼ä¼å¯¼è´è¯¥è®°å½çundo logæ为ä¸æ¡è®°å½çæ¬çº¿æ§è¡¨ï¼æ¢é¾è¡¨ï¼undo logçé¾é¦å°±æ¯ææ°çæ§è®°å½ï¼é¾å°¾å°±æ¯ææ©çæ§è®°å½ã
æ¥è¯¢æ¶ä¼è¯»åºReadViewï¼[æªæ交çäºå¡id]æ°ç» + æ大äºå¡idï¼å¹¶æ ¹æ®ReadViewä»undo logæ¥å¿ä¸ææ°è®°å½ä¾æ¬¡å¾ä¸æ¾
æ¬ç¯æç« åè /p/ddca3b
Bç«è¿æ个ç¨åºç¿up讲çè¿ä¸ªä¹å¾ä¸é /video/BV1Vk4y1k7KQ?from=search&seid=
MySQL幻读:MVCC与间隙锁
MySQL的幻读问题主要涉及MVCC(多版本并发控制)和间隙锁两种机制。在Read Committed和Read Repeatable隔离级别下,快照读通过MVCC来处理幻读,利用历史版本数据避免数据的不一致性。而当前读则通过间隙锁确保一致性,尤其是在RR(可重复读)级别,InnoDB默认的隔离级别,即使在不启用innodb_locks_unsafe_for_binlog的情况下,next-key locks(间隙锁)能防止索引扫描中的幻读现象,即保证事务在读取期间数据不会被其他事务插入或修改。
如果需要实时数据,应用需要手动使用next-key locks,如在SELECT语句后加上lock in share mode,以获取最新的数据。然而,这会导致并发性能降低,因为涉及到加锁。MVCC的优势在于无锁并发,但不能保证实时数据,而next-key锁则提供实时数据但需要加锁。
在RR级别下,虽然MVCC解决了重复读问题,但在某些场景下,它仍允许幻读,因为使用的是历史数据。而要完全避免幻读,通常需要将快照读升级为当前读,此时MySQL会使用next-key locks确保数据的完整性和一致性。
总之,MySQL的幻读处理策略依赖于事务隔离级别和锁定机制的选择,理解并正确使用这些机制对于保证数据一致性至关重要。对于更深入的学习,建议查阅官方文档或相关技术资料。
2024-11-27 07:23
2024-11-27 06:57
2024-11-27 06:53
2024-11-27 06:26
2024-11-27 06:04
2024-11-27 05:01
