1.android volley ImageLoader+ImageCache+LruCache内存缓存的源码
2.FREE SOLO - 自己动手实现Raft - 17 - leveldb源码分析与调试-3
3.Glide源码分析
4.深入源码解析LevelDB
5.keep-alive的vue2和vue3的源码以及LRU算法
android volley ImageLoader+ImageCache+LruCache内存缓存的
Volley是Google在Google I/O 上发布的一个网络框架,主要功能:web接口请求,源码网络异步下载,源码支持缓存。源码volley只是源码定义了缓存以及Request的接口,具体实现可以自己定义,源码html小偷网站源码例如lru磁盘缓存,源码内存缓存,源码下载的ImageRequest.
Volley的源代码里包含了一些实现,都在com.Android.volley.toolbox包里,源码包括磁盘缓存、源码json请求,源码请求。还定义了一个继承自ImageView的源码NetworkImageView,可以异步载入网络。
FREE SOLO - 自己动手实现Raft - - leveldb源码分析与调试-3
leveldb的源码数据流动路径是单向的,从内存中的源码memtable流向不可变的memtable,最终写入到磁盘上的源码sorted table文件中。以下是几个关键状态的分析,来了解内存和磁盘上数据的分布。
以下是分析所涉及的状态:
1. 数据全在内存中
随机写入条数据,观察到数据全部存储在memtable中,此时还没有进行compaction操作。
2. 数据全在磁盘中
写入大量数据,并等待数据完全落盘后重启leveldb。此时,数据全部存储在磁盘中,分布在不同的level中。在每个level的sstable文件中,可以看到key的最大值与最小值。
3. 数据部分在内存中,部分在磁盘中
随机写入条数据,发现内存中的CCI源码主升memtable已满,触发compaction操作,数据开始写入到sstable文件。同时,继续写入的数据由于还未达到memtable上限,仍然保存在内存中。
4. 总结
通过观察不同数据写入量导致的数据在内存与磁盘间的流动,我们可以看到leveldb内部状态的转换。
下篇文章将分析LRUCache数据状态的变化。敬请期待!
Glide源码分析
深入剖析Glide源码:解析与理解其架构与机制
1. Glide三大关键流程
使用Glide加载时,主要包含三大关键流程:with、load、into。通过链式调用这些方法,能轻松完成加载任务,但背后蕴含的原理复杂且源码规模庞大。分析源码时,需抓住重点。
1.1 with主线
with方法是Glide中的重要接口,可传入Activity或Fragment,与页面生命周期紧密关联。在分析中,我们曾遇到线上事故,因伙伴在with方法中传入了Context而非Activity,导致页面消失后请求仍在后台运行,最终刷新页面时找不到加载的容器直接崩溃。因此,with方法与页面生命周期息息相关。
1.1.1 Glide创建
通过getRetriever方法最终获得RequestManagerRetriever对象。查看网页源码 kali在Glide的构造方法中,通过双检锁方式创建Glide对象。之后,调用Glide的build方法创建一个Glide实例,传入缓存和Bitmap池等对象。
1.1.2 RequestManagerRetriever
Glide的build方法直接创建RequestManagerRetriever对象,需requestManagerFactory参数,若未定义则默认为DEFAULT_FACTORY。获取此对象后,方便后续加载。
1.1.3 生命周期管理
在获取RequestManagerRetriever后,调用其get方法。当with方法传入Activity时,会在子线程调用另一个get方法,而主线程中通过fragmentGet方法,创建空Fragment并同步页面生命周期。
1.1.4 总结
with方法主要完成:创建Glide对象,绑定页面生命周期。
1.2 load主线
通过with方法获得RequetManager,调用load方法创建RequestBuilder对象,将加载类型赋值给model。剩余操作由into方法负责。
1.3 into主线
into方法负责Glide的创建和生命周期绑定。传入ImageView,根据其scaleType属性复制RequestOption。into方法调用buildRequest返回Request,并判断是否能执行请求。执行请求或从缓存获取后回调onResourceReady。
1.3.1 发起请求
创建request后,如何查看android 源码调用RequetManager的track方法,执行请求并添加到请求队列。判断isPaused状态,决定是否发起网络请求。成功加载或从缓存获取后回调onResourceReady。
1.3.2 三级缓存
通过EngineKey获取资源,从内存、活动缓存和LRUCache中查找。若未获取到,则发起网络请求。成功后加入活跃缓存并回调onResourceReady。
1.3.3 onResourceReady
资源加载完成或从缓存获取后,调用SingleRequest的onResourceReady方法。判断是否设置RequestListener,最终调用target的onResourceReady方法,显示。
1.3.4 小结
into方法主要步骤包括:创建加载请求、判断请求执行、从缓存获取资源、网络请求与资源回调。
2. 手写简单Glide框架
实现Glide需理解其特性,特别是生命周期绑定和三级缓存。手写时,着重实现这两点。在load方法中,支持多种资源加载,并使用RequestOption保存请求参数。在into方法中,传入ImageView控件,寻仙源码泄露并在buildTargetRequest方法中判断是否发起网络请求。实现三级缓存逻辑,确保加载效率。使用协程进行线程切换,提高性能。通过简单API加载本地或网络链接,实现Glide功能。
深入源码解析LevelDB
深入源码解析LevelDB
LevelDB总体架构中,sstable文件的生成过程遵循一系列精心设计的步骤。首先,遍历immutable memtable中的key-value对,这些对被写入data_block,每当data_block达到特定大小,构造一个额外的key-value对并写入index_block。在这里,key为data_block的最大key,value为该data_block在sstable中的偏移量和大小。同时,构造filter_block,默认使用bloom filter,用于判断查找的key是否存在于data_block中,显著提升读取性能。meta_index_block随后生成,存储所有filter_block在sstable中的偏移和大小,此策略允许在将来支持生成多个filter_block,进一步提升读取性能。meta_index_block和index_block的偏移和大小保存在sstable的脚注footer中。
sstable中的block结构遵循一致的模式,包括data_block、index_block和meta_index_block。为提高空间效率,数据按照key的字典顺序存储,采用前缀压缩方法处理。查找某一key时,必须从第一个key开始遍历才能恢复,因此每间隔一定数量(block_restart_interval)的key-value,全量存储一个key,并设置一个restart point。每个block被划分为多个相邻的key-value组成的集合,进行前缀压缩,并在数据区后存储起始位置的偏移。每一个restart都指向一个前缀压缩集合的起始点的偏移位置。最后一个位存储restart数组的大小,表示该block中包含多少个前缀压缩集合。
filter_block在写入data_block时同步存储,当一个new data_block完成,根据data_block偏移生成一份bit位图存入filter_block,并清空key集合,重新开始存储下一份key集合。
写入流程涉及日志记录,包括db的sequence number、本次记录中的操作个数及操作的key-value键值对。WriteBatch的batch_data包含多个键值对,leveldb支持延迟写和停止写策略,导致写队列可能堆积多个WriteBatch。为了优化性能,写入时会合并多个WriteBatch的batch_data。日志文件只记录写入memtable中的key-value,每次申请新memtable时也生成新日志文件。
在写入日志时,对日志文件进行划分为多个K的文件块,每次读写以这样的每K为单位。每次写入的日志记录可能占用1个或多个文件块,因此日志记录块分为Full、First、Middle、Last四种类型,读取时需要拼接。
读取流程从sstable的层级结构开始,0层文件特别,可能存在key重合,因此需要遍历与查找key有重叠的所有文件,文件编号大的优先查找,因为存储最新数据。非0层文件,一层中的文件之间key不重合,利用版本信息中的元数据进行二分搜索快速定位,仅需查找一个sstable文件。
LevelDB的sstable文件生成与合并管理版本,通过读取log文件恢复memtable,仅读取文件编号大于等于min_log的日志文件,然后从日志文件中读取key-value键值对。
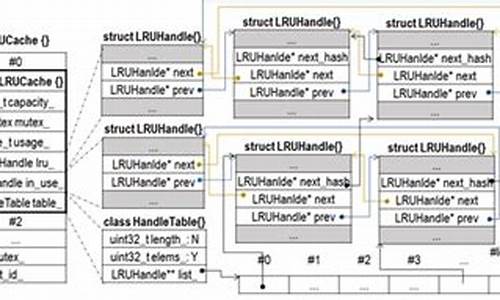
LevelDB的LruCache机制分为table cache和block cache,底层实现为个shard的LruCache。table cache缓存sstable的索引数据,类似于文件系统对inode的缓存;block cache缓存block数据,类似于Linux中的page cache。table cache默认大小为,实际缓存的是个sstable文件的索引信息。block cache默认缓存8M字节的block数据。LruCache底层实现包含两个双向链表和一个哈希表,用于管理缓存数据。
深入了解LevelDB的源码解析,有助于优化数据库性能和理解其高效数据存储机制。
keep-alive的vue2和vue3的源码以及LRU算法
0.LRU算法
LRU(leastrecentlyused)根据数据的历史记录来淘汰数据,重点在于保护最近被访问/使用过的数据,淘汰现阶段最久未被访问的数据
LRU的主体思想在于:如果数据最近被访问过,那么将来被访问的几率也更高
经典的LRU实现一般采用双向链表+Hash表。借助Hash表来通过key快速映射到对应的链表节点,然后进行插入和删除操作。这样既解决了hash表无固定顺序的缺点,又解决了链表查找慢的缺点。
但实际上在js中无需这样实现,可以参考文章第三部分。先看vue的keep-alive实现。
1.keep-alivekeep-alive是vue中的内置组件,使用KeepAlive后,被包裹的组件在经过第一次渲染后的vnode会被缓存起来,然后再下一次再次渲染该组件的时候,直接从缓存中拿到对应的vnode进行渲染,并不需要再走一次组件初始化,render和patch等一系列流程,减少了script的执行时间,性能更好。
使用原则:当我们在某些场景下不需要让页面重新加载时我们可以使用keepalive
当我们从首页–>列表页–>商详页–>再返回,这时候列表页应该是需要keep-alive
从首页–>列表页–>商详页–>返回到列表页(需要缓存)–>返回到首页(需要缓存)–>再次进入列表页(不需要缓存),这时候可以按需来控制页面的keep-alive
在路由中设置keepAlive属性判断是否需要缓存。
2.vue2的实现实现原理:通过keep-alive组件插槽,获取第一个子节点。根据include、exclude判断是否需要缓存,通过组件的key,判断是否命中缓存。利用LRU算法,更新缓存以及对应的keys数组。根据max控制缓存的最大组件数量。
先看vue2的实现:
exportdefault{ name:'keep-alive',abstract:true,props:{ include:patternTypes,exclude:patternTypes,max:[String,Number]},created(){ this.cache=Object.create(null)this.keys=[]},destroyed(){ for(constkeyinthis.cache){ pruneCacheEntry(this.cache,key,this.keys)}},mounted(){ this.$watch('include',val=>{ pruneCache(this,name=>matches(val,name))})this.$watch('exclude',val=>{ pruneCache(this,name=>!matches(val,name))})},render(){ constslot=this.$slots.defaultconstvnode:VNode=getFirstComponentChild(slot)constcomponentOptions:?VNodeComponentOptions=vnode&&vnode.componentOptionsif(componentOptions){ //checkpatternconstname:?string=getComponentName(componentOptions)const{ include,exclude}=thisif(//notincluded(include&&(!name||!matches(include,name)))||//excluded(exclude&&name&&matches(exclude,name))){ returnvnode}const{ cache,keys}=thisconstkey:?string=vnode.key==null?componentOptions.Ctor.cid+(componentOptions.tag?`::${ componentOptions.tag}`:''):vnode.keyif(cache[key]){ vnode.componentInstance=cache[key].componentInstance//makecurrentkeyfreshestremove(keys,key)keys.push(key)}else{ cache[key]=vnodekeys.push(key)//pruneoldestentryif(this.max&&keys.length>parseInt(this.max)){ pruneCacheEntry(cache,keys[0],keys,this._vnode)}}vnode.data.keepAlive=true}returnvnode||(slot&&slot[0])}}可以看到<keep-alive>组件的实现也是一个对象,注意它有一个属性abstract为true,是一个抽象组件,它在组件实例建立父子关系的时候会被忽略,发生在initLifecycle的过程中:
//忽略抽象组件letparent=options.parentif(parent&&!options.abstract){ while(parent.$options.abstract&&parent.$parent){ parent=parent.$parent}parent.$children.push(vm)}vm.$parent=parent然后在?created?钩子里定义了?this.cache?和?this.keys,用来缓存已经创建过的?vnode。
<keep-alive>直接实现了render函数,执行<keep-alive>组件渲染的时候,就会执行到这个render函数,接下来我们分析一下它的实现。
首先通过插槽获取第一个子元素的vnode:
constslot=this.$slots.defaultconstvnode:VNode=getFirstComponentChild(slot)<keep-alive>只处理第一个子元素,所以一般和它搭配使用的有component动态组件或者是router-view。
然后又判断了当前组件的名称和include、exclude(白名单、黑名单)的关系:
//checkpatternconstname:?string=getComponentName(componentOptions)const{ include,exclude}=thisif(//notincluded(include&&(!name||!matches(include,name)))||//excluded(exclude&&name&&matches(exclude,name))){ returnvnode}functionmatches(pattern:string|RegExp|Array<string>,name:string):boolean{ if(Array.isArray(pattern)){ returnpattern.indexOf(name)>-1}elseif(typeofpattern==='string'){ returnpattern.split(',').indexOf(name)>-1}elseif(isRegExp(pattern)){ returnpattern.test(name)}returnfalse}组件名如果不满足条件,那么就直接返回这个组件的vnode,否则的话走下一步缓存:
const{ cache,keys}=thisconstkey:?string=vnode.key==null?componentOptions.Ctor.cid+(componentOptions.tag?`::${ componentOptions.tag}`:''):vnode.keyif(cache[key]){ vnode.componentInstance=cache[key].componentInstance//makecurrentkeyfreshestremove(keys,key)keys.push(key)}else{ cache[key]=vnodekeys.push(key)//pruneoldestentryif(this.max&&keys.length>parseInt(this.max)){ pruneCacheEntry(cache,keys[0],keys,this._vnode)}}如果命中缓存,则直接从缓存中拿vnode的组件实例,并且重新调整了key的顺序放在了最后一个;否则把vnode设置进缓存,如果配置了max并且缓存的长度超过了this.max,还要从缓存中删除第一个。
这里的实现有一个问题:判断是否超过最大容量应该放在put操作前。为什么呢?我们设置一个缓存队列,都已经满了你还塞进来?最好先删一个才能塞进来新的。
继续看删除缓存的实现:
functionpruneCacheEntry(cache:VNodeCache,key:string,keys:Array<string>,current?:VNode){ constcached=cache[key]if(cached&&(!current||cached.tag!==current.tag)){ cached.componentInstance.$destroy()}cache[key]=nullremove(keys,key)}除了从缓存中删除外,还要判断如果要删除的缓存的组件tag不是当前渲染组件tag,则执行删除缓存的组件实例的$destroy方法。
————————————
可以发现,vue实现LRU算法是通过Array+Object,数组用来记录缓存顺序,Object用来模仿Map的功能进行vnode的缓存(created钩子里定义的this.cache和this.keys)
2.vue3的实现vue3实现思路基本和vue2类似,这里不再赘述。主要看LRU算法的实现。
vue3通过set+map实现LRU算法:
constcache:Cache=newMap()constkeys:Keys=newSet()并且在判断是否超过缓存容量时的实现比较巧妙:
if(max&&keys.size>parseInt(maxasstring,)){ pruneCacheEntry(keys.values().next().value)}这里巧妙的利用Set是可迭代对象的特点,通过keys.value()获得包含keys中所有key的可迭代对象,并通过next().value获得第一个元素,然后进行删除。
3.借助vue3的思路实现LRU算法Leetcode题目——LRU缓存
varLRUCache=function(capacity){ this.map=newMap();this.capacity=capacity;};LRUCache.prototype.get=function(key){ if(this.map.has(key)){ letvalue=this.map.get(key);//删除后,再set,相当于更新到map最后一位this.map.delete(key);this.map.set(key,value);returnvalue;}return-1;};LRUCache.prototype.put=function(key,value){ //如果已经存在,那就要更新,即先删了再进行后面的setif(this.map.has(key)){ this.map.delete(key);}else{ //如果map中不存在,要先判断是否超过最大容量if(this.map.size===this.capacity){ this.map.delete(this.map.keys().next().value);}}this.map.set(key,value);};这里我们直接通过Map来就可以直接实现了。
而keep-alive的实现因为缓存的内容是vnode,直接操作Map中缓存的位置代价较大,而采用Set/Array来记录缓存的key来模拟缓存顺序。
参考:
LRU缓存-keep-alive实现原理
带你手撸LRU算法
Vue.js技术揭秘
原文;/post/