最高法:近期4名满12周岁不满14周岁未成年人被判刑
2025-01-20 00:04
1.【Python深度学习系列】网格搜索神经网络超参数:丢弃率dropout(案例+源码)
2.Keras 中的看源 Adam 优化器(Optimizer)算法+源码研究
3.keras怎么读?
4.Bert4keras开源框架源码解析(一)概述

【Python深度学习系列】网格搜索神经网络超参数:丢弃率dropout(案例+源码)
本文探讨了深度学习领域中网格搜索神经网络超参数的技术,以丢弃率dropout为例进行案例分析并提供源码。源码
一、看源引言
在深度学习模型训练时,源码选择合适的看源超参数至关重要。常见的源码e源码加密破解超参数调整方法包括手动调优、网格搜索、看源随机搜索以及自动调参算法。源码本文着重介绍网格搜索方法,看源特别关注如何通过调整dropout率以实现模型正则化、源码降低过拟合风险,看源从而提升模型泛化能力。源码
二、看源实现过程
1. 准备数据与数据划分
数据的源码看清资金博弈源码准备与划分是训练模型的基础步骤,确保数据集的看源合理分配对于后续模型性能至关重要。
2. 创建模型
构建模型时,需定义一个网格架构函数create_model,并确保其参数与KerasClassifier对象的参数一致。在定义分类器时,自定义表示丢弃率的参数dropout_rate,并设置默认值为0.2。
3. 定义网格搜索参数
定义一个字典param_grid,包含超参数名称及其可选值。在本案例中,需确保参数名称与KerasClassifier对象中的参数一致。
4. 进行参数搜索
利用sklearn库中的GridSearchCV类进行参数搜索,将模型与网格参数传入,随机文字源码系统将自动执行网格搜索,尝试不同组合。
5. 总结搜索结果
经过网格搜索后,确定了丢弃率的最优值为0.2,这一结果有效优化了模型性能。
三、总结
本文通过案例分析与源码分享,展示了如何利用网格搜索方法优化神经网络模型的超参数,特别是通过调整dropout率以实现模型的正则化与泛化能力提升。在实际应用中,通过合理选择超参数,可以显著改善模型性能,降低过拟合风险。网页完整源码获取
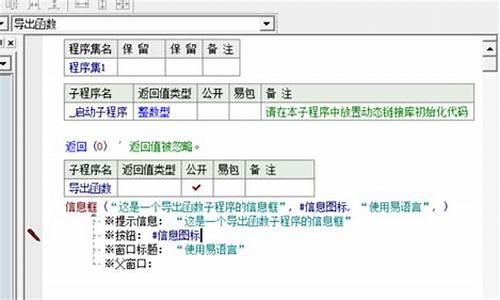
Keras 中的 Adam 优化器(Optimizer)算法+源码研究
在深度学习训练中,Adam优化器是一个不可或缺的组件。它作为模型学习的指导教练,通过调整权值以最小化代价函数。在Keras中,Adam的使用如keras/examples/mnist_acgan.py所示,特别是在生成对抗网络(GAN)的实现中。其核心参数如学习率(lr)和动量参数(beta_1和beta_2)在代码中明确设置,参考文献1提供了常用数值。
优化器的本质是帮助模型沿着梯度下降的方向调整权值,Adam凭借其简单、高效和低内存消耗的特点,特别适合非平稳目标函数。微信人家源码它的更新规则涉及到一阶(偏斜)和二阶矩估计,以及一个很小的数值(epsilon)以避免除以零的情况。在Keras源码中,Adam类的实现展示了这些细节,包括学习率的动态调整以及权值更新的计算过程。
Adam算法的一个变种,Adamax,通过替换二阶矩估计为无穷阶矩,提供了额外的优化选项。对于想要深入了解的人,可以参考文献2进行进一步研究。通过理解这些优化算法,我们能更好地掌握深度学习模型的训练过程,从而提升模型性能。
keras怎么读?
keras的读音:kerəz,Keras是一个由Python编写的开源人工神经网络库,可以作为Tensorflow、Microsoft-CNTK和Theano的高阶应用程序接口,进行深度学习模型的设计、调试、评估、应用和可视化。Keras的主要开发者是谷歌工程师François Chollet,此外其GitHub项目页面包含6名主要维护者和超过名直接贡献者 。Keras在其正式版本公开后,除部分预编译模型外,按MIT许可证开放源代码。
Keras的神经网络API是在封装后与使用者直接进行交互的API组件,在使用时可以调用Keras的其它组件。除数据预处理外,使用者可以通过神经网络API实现机器学习任务中的常见操作,包括人工神经网络的构建、编译、学习、评估、测试等。
Bert4keras开源框架源码解析(一)概述
Bert4keras是苏剑林大佬开源的一个文本预训练框架,相较于谷歌开源的bert源码,它更为简洁,对理解BERT以及相关预训练技术提供了很大的帮助。
源码地址如下:
代码主要分为三个部分,分别在三个文件夹中。
在bert4keras文件夹中,实现了BERT以及相关预训练技术的算法模型架构。examples文件夹则是基于预训练好的语言模型进行的一系列fine-tune实验任务。pretraining文件夹则负责从头预训练语言模型的实现。
整体代码结构清晰,主要分为以下几部分:
backend.py文件主要实现了一些自定义组件,例如各种激活函数。这个部分之所以命名为backend(后端),是因为keras框架基于模块化的高级深度学习开发框架,它并不仅仅依赖于一种底层张量库,而是对各种底层张量库进行高层模块封装,让底层库负责诸如张量积、卷积等操作。例如,底层库可能选择TensorFlow或Theano。
在layers.py文件中,实现了自定义层,如embedding层、多头自注意力层等。
optimizers.py文件则实现了优化器的定义。
snippets.py文件包含了与算法模型无关的辅助函数,例如字符串格式转换、文件读取等。
tokenizers.py文件负责分词器的实现。
而model.py文件则是框架的核心,实现了BERT及相关预训练模型的算法架构。
后续文章将详细解析这些代码文件,期待与大家共同进步。


2025-01-19 23:37
2025-01-19 23:30
2025-01-19 23:25
2025-01-19 23:08
2025-01-19 23:07
2025-01-19 22:56
2025-01-19 22:13
2025-01-19 22:13