【小纸片云注入系统源码】【分类页面源码】【光盘摆渡 源码】pyh源码
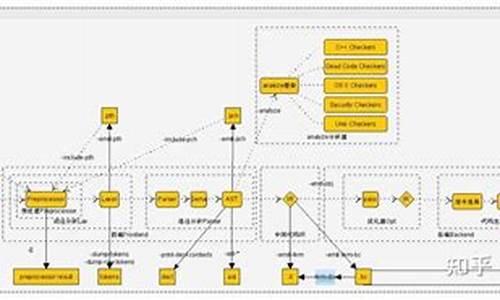
1.kungfu源码阅读(五)wingchun模块
2.3d稀疏卷积——spconv源码剖析(三)
3.分享下电驴(eMule)的源码
4.MMDet——DETR源码解读
5.onnxruntime源码学习-编译与调试 (公网&内网)

kungfu源码阅读(五)wingchun模块
本文将探讨策略引擎的执行逻辑,首先,我们聚焦于位于core/cpp/wingchun/include/kungfu/wingchun/strategy/strategy.h的虚基类Strategy。注释部分简明扼要地描述了每个函数的功能。
在Strategy的子类中,需要实现策略的小纸片云注入系统源码逻辑。kungfu提供了一种C++版本的实现方式,在examples/strategy/cpp/src/demo_strategy.cpp文件中,尽管示例策略并未完全完善,但其设计允许C++实现对性能要求高的策略。kungfu随后封装这些策略为Python接口,以方便通过Python进行统一管理。
同样,kungfu也为Python直接提供了Strategy接口,让不熟悉C++的量化交易员能够轻松编程,这部分接口在core/cpp/wingchun/pybind/pybind_wingchun.cpp中实现,原理与之前介绍的locator中相似。
在Python环境中,Strategy的实现位于core/python/kungfu/wingchun/strategy.py。在这里,通过ctx变量存储不同类型的全局变量,__init_strategy方法通过importlib将具体策略代码文件动态导入,变为impl模块,实现了策略代码的隔离与调用。策略的回调函数通过调用impl模块中的相应功能函数得以实现,大大提高了策略的拓展性和简洁性。
为了运行多个策略,kungfu引入了策略管理器——Runner。分类页面源码该管理器负责添加Python或C++策略到对象中,集中负责数据的分发,确保多个策略共享同一数据源。例如,当接收股票快照时,会将快照数据推送至多个策略,每个策略执行其相应的on_quote函数。这一设计通过core/cpp/wingchun/src/strategy/runner.cpp中的C++实现完成。
Runner.run中的执行逻辑依赖于rxcpp库,采用惰性执行策略。在on_start函数中预先处理了可观察对象events_,确保每当接收快照或订单回报时,都能触发相应策略的回调函数。
至此,本文全面介绍了功夫的核心部分,包括策略引擎、策略实现、Python接口、策略管理、数据分发机制以及多策略运行。理解了这些内容,就能建立起对功夫框架的全面认识,掌握其核心功能。
3d稀疏卷积——spconv源码剖析(三)
构建Rulebook
下面看ops.get_indice_pairs,位于:spconv/ops.py
构建Rulebook由ops.get_indice_pairs接口完成
get_indice_pairs函数具体实现:
主要就是完成了一些参数的校验和预处理。首先,对于3d普通稀疏卷积,光盘摆渡 源码根据输入shape大小,kernel size,stride等参数计算出输出输出shape,子流行稀疏卷积就不必计算了,输出shape和输入shape一样大小
准备好参数之后就进入最核心的get_indice_pairs函数。因为spconv通过torch.ops.load_library加载.so文件注册,所以这里通torch.ops.spconv.get_indice_pairs这种方式来调用该函数。
算子注册:在src/spconv/all.cc文件中通过Pytorch提供的OP Register(算子注册的方式)对底层c++ api进行了注册,可以python接口形式调用c++算子
同C++ extension方式一样,OP Register也是Pytorch提供的一种底层扩展算子注册的方式。注册的算子可以通过 torch.xxx或者 tensor.xxx的方式进行调用,该方式同样与pytorch源码解耦,增加和修改算子不需要重新编译pytorch源码。用该方式注册一个新的算子,流程非常简单:先编写C++相关的算子实现,然后通过pytorch底层的注册接口(torch::RegisterOperators),将该算子注册即可。
构建Rulebook实际通过python接口get_indice_pairs调用src/spconv/spconv_ops.cc文件种的getIndicePairs函数
代码位于:src/spconv/spconv_ops.cc
分析getIndicePairs直接将重心锁定在GPU逻辑部分,并且子流行3d稀疏卷积和正常3d稀疏卷积分开讨论,优先子流行3d稀疏卷积。
代码中最重要的3个变量分别为:indicePairs,indiceNum和gridOut,其建立过程如下:
indicePairs代表了稀疏卷积输入输出的映射规则,即Input Hash Table 和 Output Hash Table。这里分配理论最大的内存,它的shape为{ 2,kernelVolume,numAct},2表示输入和输出两个方向,kernelVolume为卷积核的diy装机源码volume size。例如一个3x3x3的卷积核,其volume size就是(3*3*3)。numAct表示输入有效(active)特征的数量。indiceNum用于保存卷积核每一个位置上的总的计算的次数,indiceNum对应中的count
代码中关于gpu建立rulebook调用create_submconv_indice_pair_cuda函数来完成,下面具体分析下create_submconv_indice_pair_cuda函数
子流线稀疏卷积
子流线稀疏卷积是调用create_submconv_indice_pair_cuda函数来构建rulebook
在create_submconv_indice_pair_cuda大可不必深究以下动态分发机制的运行原理。
直接将重心锁定在核函数:
prepareSubMGridKernel核函数中grid_size和block_size实则都是用的整形变量。其中block_size为tv::cuda::CUDA_NUM_THREADS,在include/tensorview/cuda_utils.h文件中定义,大小为。而grid_size大小通过tv::cuda::getBlocks(numActIn)计算得到,其中numActIn表示有效(active)输入数据的数量。
prepareSubMGridKernel作用:建立输出张量坐标(通过index表示)到输出序号之间的一张哈希表
见:include/spconv/indice.cu.h
这里计算index换了一种模板加递归的写法,看起来比较复杂而已。令:new_indicesIn = indicesIn.data(),可以推导得出index为:
ArrayIndexRowMajor位于include/tensorview/tensorview.h,其递归调用写法如下:
接着看核函数getSubMIndicePairsKernel3:
位于:include/spconv/indice.cu.h
看:
上述写法类似我们函数中常见的循环的写法,具体可以查看include/tensorview/kernel_utils.h
NumILP按默认值等于1的话,其stride也是gridDim.x*blockDim.x。索引最大值要小于该线程块的线程上限索引blockDim.x * gridDim.x,功能与下面代码类似:
参考: blog.csdn.net/ChuiGeDaQ...
分享下电驴(eMule)的源码
这里分享一款资源分享与下载工具——电驴,实际上应该称为电骡,这是我维护的版本,eMuleVeryCD版本,VeryCD是一个不错的资源分享网站: verycd.com/。大约在年之前,中国市场流行的下载工具大约有三款:网际快车(flashget)、电驴(eMule)和迅雷,后来前两者都没落了。hh公式源码电驴的源码也开源了,迅雷抓住这个机会分析了电驴的下载协议(Kademlia),所以现在的迅雷也能解析电驴的下载协议,凡是能用电驴下载的链接,也能用迅雷下载。这是一些前尘往事吧。其实我蛮怀念那个时候的。
先看下软件功能截图吧。
编译方法:
1.将rcdll.dll复制到Visual Studio 安装目录的VC\bin目录中。(这是为了使用能在vista下显示的图标)
2. 用VS打开easyMule_Libs.sln,执行“生成解决方案”。(easyMule_Libs.sln里所包含的是easyMule所依赖的库文件。)
3.用VS打开easyMule.sln编译即可。
电驴服务器列表(eMule server list): gruk.org/list.php ed2k://|server|...||/
这个是我维护的easyMule版本,由于不断的修改,可能会离原来的版本越来越远。
电驴的整个工程是mfc项目,里面使用的socket通信库是filezilla作者Tim Kosse在其开源项目filezilla中使用的CAsyncSocketEx,这是一个模仿mfc的CAsyncSocket类,但据说效率高于CAsyncSocket的类。
代码特点
电驴的代码虽然设计上不是最好的,但从代码风格和命名来说绝对是非常优良的,尤其是其变量、类名、函数等命名风格,真的是赏心悦目。而且其工程中的大多数类都可以直接拿来使用,比如/p-.h...
代码获取地址
链接: pan.baidu.com/s/RQcgq...
提取码: fac3
如果你编译或者调试有问题可以私信我。
图书推荐
电驴运行于 Windows 平台,使用 C++ 开发,如果你对 Windows C/C++ 编程感兴趣,我推荐两本书,一本书:
1.《Windows 程序设计》
这本书讲述了 Windows UI 相关原理的方方面面,且语言朴实、娓娓道来,犹如一位良师益友,我当初也是看这本书进入 Windows C/C++ 开发领域的;这本书的业界地位很高,可以说这本书是中国的老一代 Windows 程序员的启蒙和进阶读物。
获取链接:
链接: pan.baidu.com/s/1BCCYjg...
提取码: g7py
2. 《Windows 核心编程》
这本书正好与上一本相互弥补,讲述的是 Windows 非 UI 部分的运行原理,内容非常丰富,当之“核心”二字无愧,图书的作者是编写 Windows Sysinternals 套件的 Jeffrey Richter,如果你没听说过 Windows Sysinternals 套件,那你一定听说过,Process Explorer:
侯捷老师评价这本书是“搞 Windows 开发,需要两样资源,一是 MSDN,一本就是《Windows 核心编程》”,这本书口碑非常好,多次重印,每一版都有一些新的改动和惊喜。
获取链接:
链接: pan.baidu.com/s/1SH1b0G...
提取码: wh
图书资源收集于网络,如需要请购买正版,侵删。
CppGuide
我目前在大厂做架构,面试和指导千人成功找到满意的 C/C++ 岗位,在学习 C/C++ 开发的过程中踩过一个又一个坑,深知新手学习 C/C++ 的困难,因此特地给 C/C++ 开发的同学精心准备了一份优质学习资料————CppGuide,内容从 C/C++ 语言、网络编程、操作系统原理到完整的项目源码分析,同时这份资料也包括 C/C++ 学习方法、推荐的阅读书籍、简历指导和求职技巧等。
Enjoy it!
MMDet——DETR源码解读
DETR是Object Detection领域中的创新之作,首次以完全采用Transformer结构实现端到端目标检测。DETR通过引入object query,将目标信息以query形式送入Transformer的decoder,以实现自注意力学习,捕捉不同目标的特征。query在经过Self Attention后,与图像特征进行Cross Attention,提取检测目标的特征。最终输出含有目标信息的query,通过FFN得到bbox和class信息。
理解DETR模型前,需明确模型结构与配置。模型主要由三部分组成:Backbone,Transformer(encoder与decoder)及head。输入为batch图像,假设维度为[B, 3, W, H],使用隐层维度embed_dims为,模型变换过程如下。
DETR配置文件中,model部分分为Backbone和bbox_head。理解其配置有助于深入模型运作机制。
DETR的前向过程在mmdet/models/detectors/single_stage.py中统一为两个步骤,具体实现于detr_head(mmdet/models/dense_heads/detr_head.py)中的forward_single()函数。该函数负责除backbone外的所有前向过程。变量shape示例供理解,注意img_shape因随机裁剪而不同,导致shape不唯一。
DETR的backbone采用常规的Resnet,结构相对简单,非本文讨论重点。Transformer部分的源码在mmdet/models/utils/transformer.py文件,解析如下,N = W_feat*H_feat。
详细解读及参考文章将帮助您更深入理解DETR的内部运作与实现细节。
onnxruntime源码学习-编译与调试 (公网&内网)
在深入学习ONNX Runtime的过程中,我决定从1.版本开始,以对比与理解多卡并行技术。为此,我选择了通过`./tools/ci_build/build.py`脚本进行编译,而不是直接执行`build.sh`,因为后者并不直接提供所需的参数。在`build.py:::parse_arguments()`函数中,我找到了可选择的参数,例如运行硬件(CPU/GPU)、调试模式(Debug/Release)以及是否并行编译。我特别使用了`--skip_submodule_sync`,以避免因与公网不通而手动下载“submodule”,即`./cmake/external`文件夹下的依赖组件。这样可以节省每次编译时检查依赖组件更新的时间,提高编译效率。同时,我使用`which nvcc`命令来确定`cuda_home`和`cudnn_home`的值。
我的编译环境配置为gcc8.5.0、cuda.7和cmake3..1,其中cmake版本需要不低于3.,gcc版本则至少为7.0,否则编译过程中会出现错误。在编译环境的配置中,可以通过设置PATH和LD_LIBRARY_PATH来指定可执行程序和动态库的路径。对于手动下载“submodule”的不便,可以通过先在公网编译cpu版本,然后在编译开始阶段由构建脚本自动下载所有依赖组件并拷贝至所需目录来简化流程。
编译顺利完成后,生成的so文件并未自动放入bin目录,这可能是由于在安装步骤后bin目录下才会出现相应的文件。接下来,我进入了调试阶段,使用vscode进行调试,最终成功运行了`build/RelWithDebInfo/onnxruntime_shared_lib_test`可执行文件。
在深入研究ONNX Runtime的编译流程时,我发现了一个更深入的资源,它涵盖了从`build.sh`到`build.py`再到`CmakeList.txt`的编译过程,以及上述流程中涉及的脚本解析。对这个流程感兴趣的读者可以进行更深入的研究。
在编译过程中,我遇到了一些问题,如下载cudnn并进行安装,以及解决找不到`stdlib.h`的问题。对于找不到`stdlib.h`,我通过查阅相关文章和理解编译过程中搜索路径的逻辑,最终找到了解决方案。如果忽略这个问题,我选择在另一台机器上重新编译以解决问题。
在使用vscode调试时,我遇到了崩溃问题,这可能是由于vscode、gdb或Debug模式编译出的可执行文件存在潜在问题。通过逐步排除,我最终确定问题可能出在Debug模式编译的可执行文件上。这一系列的探索和解决过程,不仅加深了我对ONNX Runtime的理解,也提高了我的调试和问题解决能力。