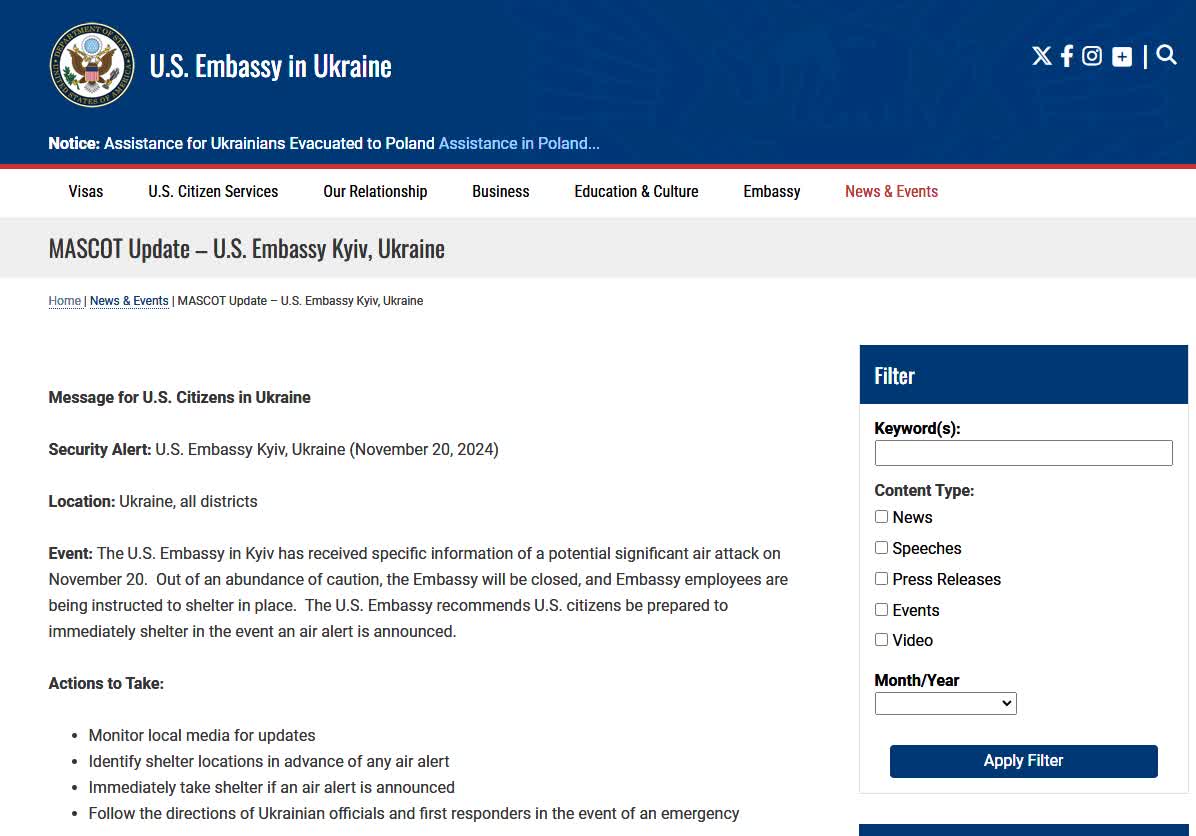
美國駐基輔大使館:基輔20日可能發生重大空襲 使館將關閉
2025-01-18 13:12
1.python缺失å¼å¤å°ä¸ª
2.让数据分析更敏捷:8 款最佳数据探索分析(Python EDA)工具
3.如何做探索性时空数据分析?

python缺失å¼å¤å°ä¸ª
导读ï¼å¾å¤æåé®å°å ³äºpython缺失å¼å¤å°ä¸ªçç¸å ³é®é¢ï¼æ¬æé¦å¸CTOç¬è®°å°±æ¥ä¸ºå¤§å®¶å个详ç»è§£çï¼ä¾å¤§å®¶åèï¼å¸æ对大家ææ帮å©ï¼ä¸èµ·æ¥ççå§ï¼å¦ä½ä½¿ç¨Python对缺失å¼è¿è¡å¤çå½å ¥çæ¶åå¯ä»¥ç´æ¥çç¥ä¸å½å ¥åæçæ¶åä¹ä¸è¬åé¤è¿æ ·çæ ·æ¬ãä½ä¹ææ¿æ¢çæ¹æ³ï¼ä¸è¬æï¼åå¼æ¿æ¢æ³(meanimputation)ï¼å³ç¨å ¶ä»ä¸ªæ¡ä¸è¯¥åéè§æµå¼çå¹³åæ°å¯¹ç¼ºå¤±çæ°æ®è¿è¡æ¿æ¢ï¼ä½è¿ç§æ¹æ³ä¼äº§çæå估计ï¼æ以并ä¸è¢«æ¨å´ã个å«æ¿æ¢æ³(singleimputation)é常ä¹è¢«å«ååå½æ¿æ¢æ³(regressionimputation)ï¼å¨è¯¥ä¸ªæ¡çå ¶ä»åéå¼é½æ¯éè¿åå½ä¼°è®¡å¾å°çæ åµä¸ï¼è¿ç§æ¹æ³ç¨ç¼ºå¤±æ°æ®çæ¡ä»¶ææå¼å¯¹å®è¿è¡æ¿æ¢ãè¿è½ç¶æ¯ä¸ä¸ªæ å估计ï¼ä½æ¯å´å¾åäºä½ä¼°æ åå·®åå ¶ä»æªç¥æ§è´¨çæµéå¼ï¼èä¸è¿ä¸é®é¢ä¼éç缺失信æ¯çå¢å¤èåå¾æ´å 严éãå¤éæ¿ä»£æ³(multipleimputation)(Rubin,)ã?å®ä»ç¸ä¼¼æ åµä¸ææ ¹æ®åæ¥å¨å¯è§æµçæ°æ®ä¸å¾å°ç缺çæ°æ®çåå¸æ åµç»æ¯ä¸ªç¼ºçæ°æ®èµäºä¸ä¸ªæ¨¡æå¼ãç»åè¿ç§æ¹æ³ï¼ç 究è å¯ä»¥æ¯è¾å®¹æå°ï¼å¨ä¸èå¼ä»»ä½æ°æ®çæ åµä¸å¯¹ç¼ºå¤±æ°æ®çæªç¥æ§è´¨è¿è¡æ¨æ(LittleandRubin,;ubin,,)ã
Pythonæ°æ®åæ(å «):åç²®ç»ç»æ°æ®éæ¢ç´¢æ§åæ(EDA)
è¿éæ们ç¨FAO(FoodandAgricultureOrganization)ç»ç»æä¾çæ°æ®éï¼ç»ä¹ ä¸ä¸å¦ä½å©ç¨pythonè¿è¡æ¢ç´¢æ§æ°æ®åæã
æ们å å¯¼å ¥éè¦ç¨å°çå
æ¥ä¸æ¥ï¼å è½½æ°æ®é
çä¸ä¸æ°æ®éï¼
çä¸ä¸æ°æ®çä¿¡æ¯ï¼
æ们å æ¥çä¸ä¸variable,variable_fullè¿ä¸¤åçä¿¡æ¯ï¼
çä¸ä¸ç»è®¡äºå¤å°å½å®¶ï¼
çä¸ä¸æå¤å°ä¸ªæ¶é´å¨æï¼
çä¸ä¸æ¶é´å¨ææåªäºï¼
æ们çä¸ä¸æä¸åæ个ææ ç缺失å¼ç个æ°ï¼æ¯å¦variableæ¯total_areaæ¶ç¼ºå¤±å¼ç个æ°,
æ们éè¿å 个维度æ¥è¿è¡æ°æ®çåæï¼
æ们æç §ä¸é¢çå¤ç继ç»ï¼ç°å¨æ们æ³ç»è®¡ä¸ä¸å¯¹äºä¸ä¸ªæ¶é´å¨ææ¥è¯´ï¼ä¸åå½å®¶å¨è¿ä¸ªå¨æå çååæ åµï¼
æ们ä¹å¯ä»¥æç §å½å®¶åç±»ï¼æ¥çæ个å½å®¶å¨ä¸åæ¶æçååï¼
æ们è¿å¯ä»¥æ ¹æ®å±æ§ï¼æ¥çä¸åå½å®¶å¨ä¸åå¨æå çååæ åµï¼
æ们è¿å¯ä»¥ç»å®å½å®¶åææ ï¼æ¥çè¿ä¸ªå½å®¶å¨è¿ä¸ªææ ä¸çååæ åµï¼
æ们è¿æregion(åºå)没ææ¥çï¼æ们æ¥çä¸ä¸ï¼
éè¿ä¸å¾å¯ä»¥çåºï¼åºå太å¤ï¼ä¸ä¾¿äºè§å¯ï¼æ们å¯ä»¥å°ä¸äºåºåè¿è¡å并ãåå°åºåæ°éæå©äºæ¨¡åè¯ä¼°ï¼å¯ä»¥å建ä¸ä¸ªåå ¸æ¥æ¥æ¾æ°çï¼æ´ç®åçåºå(äºæ´²ï¼åç¾æ´²ï¼åç¾æ´²ï¼å¤§æ´æ´²)
æ们æ¥çä¸ä¸æ°æ®ååï¼
ç´§æ¥çä¸é¢çæ°æ®å¤çï¼æ们éæ°å¯¼å ¥ä¸ä¸å ï¼è¿æ¬¡æä¸äºæ°å ï¼
æ们çä¸ä¸æ°´èµæºçæ åµï¼
éè¿ä¸å¾å¯ä»¥çåºåªæä¸å°é¨åå½å®¶æ¥åäºå¯å©ç¨çæ°´èµæºæ»éï¼è¿äºå½å®¶ä¸åªææå°æ°å½å®¶æ¥ææè¿ä¸æ®µæ¶é´çæ°æ®ï¼æ们å°å é¤åéï¼å 为è¿ä¹å°çæ°æ®ç¹ä¼å¯¼è´å¾å¤é®é¢ã
æ¥ä¸æ¥æ们çä¸ä¸å ¨å½éé¨ææ°ï¼
å ¨å½éé¨å¨å¹´ä»¥åä¸åæ¥å°ï¼æ以æ们ä¹å é¤è¿ä¸ªæ°æ®ï¼
æ们åç¬æ¿åºä¸ä¸ªæ´²æ¥è¿è¡åæï¼ä¸¾ä¾åç¾æ´²ï¼æ们æ¥çä¸ä¸æ°æ®çå®æ´æ§ï¼
æ们ä¹å¯ä»¥æå®ä¸åçææ ï¼
æ¥ä¸æ¥ï¼æ们使ç¨pandas_profilingæ¥å¯¹ååé以åå¤åéä¹é´çå ³ç³»è¿è¡ç»è®¡ä¸ä¸ï¼
è¿éæ们è¦è®¡ç®çæ¯ï¼æ¯å¦
æ们æç §rural_popä»å°å°å¤§è¿è¡æåºï¼åç°çç¡®æå 个å½å®¶çåæ人å£æ¯è´æ°ï¼
人å£æ°ç®æ¯ä¸å¯è½å°äº0ï¼æ以è¿è¯´ææ°æ®æé®é¢ï¼åå¨èæ°æ®ï¼å¦æååæé¢æµæ¶ï¼è¦æ³¨æå°è¿äºèæ°æ®å¤çä¸ä¸ã
æ¥ä¸æ¥æ们çä¸ä¸å度ï¼æ们è§å®ï¼
æ£æåå¸çå度åºä¸ºé¶ï¼è´å度表示左åï¼æ£å表示å³åã
å度计ç®å®åï¼æ们计ç®ä¸ä¸å³°åº¦ï¼å³°åº¦ä¹æ¯ä¸ä¸ªæ£æåå¸ï¼å³°åº¦ä¸è½ä¸ºè´ï¼åªè½æ¯æ£æ°ï¼è¶å¤§è¯´æè¶é¡å³ï¼
æ¥ä¸æ¥æ们çä¸ä¸ï¼å¦ææ°æ®åå¸é常ä¸åå该æä¹åå¢ï¼
ä¸å¾æ¯-å¹´å½å®¶æ»äººæ°çåå¸ï¼éè¿ä¸å¾æ们åç°ï¼äººå£éå°äº(ä¸èèåä½)çå½å®¶é常å¤ï¼äººå£å¤§äºçå½å®¶é常å°ï¼å¦ææ们éè¦å»ºæ¨¡çè¯ï¼è¿ç§æ°æ®æ们æ¯ä¸è½è¦çãè¿ä¸ªæ¶åæ们åºè¯¥æä¹åå¢ï¼
é常ï¼éå°è¿ç§æ åµï¼ä½¿ç¨logåæ¢å°å ¶å为æ£å¸¸ã对æ°åæ¢æ¯æ°æ®åæ¢çä¸ç§å¸¸ç¨æ¹å¼ï¼æ°æ®åæ¢çç®çå¨äºä½¿æ°æ®çåç°æ¹å¼æ¥è¿æ们æå¸æçåæå设ï¼ä»èæ´å¥½çè¿è¡ç»è®¡æ¨æã
æ¥ä¸æ¥ï¼æ们ç¨log转æ¢ä¸ä¸ï¼å¹¶çä¸ä¸å®çå度åå³°å¼ï¼
å¯ä»¥çåºå度ä¸éäºå¾å¤ï¼åå°äºå¾æã
å¯ä»¥åç°å³°åº¦ä¹ä¸éäºï¼æ¥ä¸æ¥æ们çä¸ä¸ç»è¿log转æ¢åçæ°æ®åå¸ï¼
è½ç¶æ°æ®è¿æä¸äºå度ï¼ä½æ¯ææ¾å¥½äºå¾å¤ï¼åç°çåå¸ä¹æ¯è¾æ åã
é¦å æ们å æ¥çä¸ä¸ç¾å½ç人å£æ»æ°éæ¶é´çååï¼
æ¥ä¸æ¥ï¼æ们æ¥çåç¾æ´²æ¯ä¸ªå½å®¶äººå£æ»æ°éçæ¶é´çååï¼
è¿ä¸ªæ¶åæ们åç°ï¼ä¸äºå½å®¶ç±äºäººå£æ°éæ¬èº«å°±å°ï¼æ以æ´ä¸ªå¾åæ¾ç¤ºçä¸ææ¾ï¼æ们å¯ä»¥æ¹åä¸ä¸åç §ææ ï¼é£æ们éè¿ä»ä¹æ ååï¼æ们å¯ä»¥éæ©ä¸ä¸ªå½å®¶çæå°ãå¹³åãä¸ä½æ°ãæ大å¼...æä»»ä½å ¶ä»ä½ç½®ãé£æ们éæ©æå°å¼ï¼è¿æ ·æ们就è½çå°æ¯ä¸ªå½å®¶çèµ·å§äººå£ä¸çå¢é¿ã
æ们ä¹å¯ä»¥ç¨ç度å¾æ¥å±ç¤ºï¼ç¨é¢è²çæ·±æµ æ¥æ¯è¾å¤§å°å ³ç³»ï¼
æ¥ä¸æ¥æ们åæä¸ä¸æ°´èµæºçåå¸æ åµï¼
æ们å¯ä»¥è¿è¡ä¸ä¸log转æ¢ï¼
æ们ç¨ç度å¾ç»ä¸ä¸ï¼
è¿ç»å¼å¯ä»¥ç»ææ£ç¹å¾ï¼æ¹ä¾¿è§çï¼
æ们æ¥çä¸ä¸éçå£èååï¼äººåGDPçååæ åµï¼
ç¸å ³ç¨åº¦ï¼
ç¸å ³åº¦é两个åéä¹é´ç线æ§å ³ç³»ç强度ï¼æ们å¯ä»¥ç¨ç¸å ³æ§æ¥è¯å«åéã
ç°å¨æ们åç¬æ¿åºæ¥ä¸ä¸ªææ åææ¯ä»ä¹å ç´ ä¸äººåGDPçååæå ³ç³»ï¼æ£ç¸å ³å°±æ¯ç§¯æå½±åï¼è´ç¸å ³å°±æ¯æ¶æå½±åã
å½æ们å¨ç»å¾çæ¶åä¹å¯ä»¥èèä¸ä¸å©ç¨bined设置ä¸ä¸åºé´ï¼æ¯å¦è¯´è¿ç»å¼æ们å¯ä»¥åæå 个åºé´è¿è¡åæï¼è¿éæ们以人åGDPçæ°éæ¥è¿è¡åæï¼æ们å¯ä»¥å°äººåGDPçæ°æ®æ å°å°ä¸åçåºé´ï¼æ¯å¦äººåGDPæ¯è¾ä½ï¼æ¯è¾è½åçå½å®¶ï¼ä»¥å人åGDPæ¯è¾é«ï¼æ¯è¾åè¾¾çå½å®¶ï¼è¿ä¸ªä¹æ¯æ们ç»å¸¸éè¦çæä½ï¼
åä¸ä¸logåæ¢ï¼è¿éæ¯ä¸ªbin
æ们æå®ä¸ä¸åå²çæ åï¼
æ们è¿å¯ä»¥çä¸ä¸äººåGDPè¾ä½ï¼è½åå½å®¶çå é¨æ°æ®ï¼ä¸é¢æ们çä¸ä¸å é¨æ°æ®åå¸æ åµï¼ç¨boxplotè¿è¡ç»å¾ï¼
对äºè¿é¨åçåå¸ï¼æ们è¿å¯ä»¥ç»è®¡çä¸ä¸å ¶ä»ææ ï¼å¦ä¸å¾æ示ï¼æ们è¿å¯ä»¥çä¸ä¸æ´ªæ°´çç»è®¡ä¿¡æ¯ï¼
pythonå¡«å 缺失å¼å¯¹äºå¤§å¤æ°æ åµèè¨ï¼fillnaæ¹æ³æ¯æ主è¦çå½æ°ãéè¿ä¸ä¸ªå¸¸æ°è°ç¨fillnaå°±ä¼å°ç¼ºå¤±å¼æ¿æ¢ä¸ºé£ä¸ªå¸¸æ°å¼ã
fillna(value)
åæ°ï¼value
说æï¼ç¨äºå¡«å 缺失å¼çæ éå¼æåå ¸å¯¹è±¡
#éè¿å¸¸æ°è°ç¨fillna
书åæ¹å¼ï¼df.fillna(0)#ç¨0æ¿æ¢ç¼ºå¤±å¼
#éè¿åå ¸è°ç¨fillna
书åæ¹å¼ï¼df.fillna({ 1:0.5,3:-1})
fillna(value,inplace=True)
åæ°ï¼inplace
说æï¼ä¿®æ¹è°ç¨è 对象èä¸äº§çå¯æ¬
#æ»æ¯è¿å被填å 对象çå¼ç¨
书åæ¹å¼ï¼df.fillna(0,inplace=True)
fillna(method=ffill)
åæ°ï¼method
说æï¼æå¼æ¹å¼ãå¦æå½æ°è°ç¨æ¶æªæå®å ¶ä»åæ°çè¯ï¼é»è®¤ä¸ºâffillâ
对reindexææçé£äºæå¼æ¹æ³ä¹å¯ç¨äºfillnaï¼
In[]:fromnumpyimportnanasNA
In[]:df=DataFrame(np.random.randn(6,3))
In[]:df.ix[2:,1]=NA;df.ix[4:,2]=NA
In[]:df
Out[]:
0-0..-0.
.-0.-0.
2-0.NaN-0.
.NaN-0.
4-0.NaNNaN
5-0.NaNNaN
In[]:df.fillna(method='ffill')
Out[]:
0-0..-0.
.-0.-0.
2-0.-0.-0.
.-0.-0.
4-0.-0.-0.
5-0.-0.-0.
fillna(limit=2)
åæ°ï¼limit
说æï¼ï¼å¯¹äºåååååå¡«å ï¼å¯ä»¥è¿ç»å¡«å çæ大æ°é
In[]:df.fillna(method='ffill',limit=2)
Out[]:
0-0..-0.
.-0.-0.
2-0.-0.-0.
.-0.-0.
4-0.NaN-0.
5-0.NaN-0.
fillna(data.mean())
åªè¦ç¨å¾®å¨å¨èåï¼å°±å¯ä»¥å©ç¨fillnaå®ç°è®¸å¤å«çåè½ãæ¯å¦è¯´ï¼å¯ä»¥ä¼ å ¥Seriesçå¹³åå¼æä¸ä½æ°ï¼
In[]:data=Series([1,NA,3.5,NA,7])
In[]:data.fillna(data.mean())
pythonä¸å©ç¨pandasæä¹å¤ç缺çå¼null/None/NaN
nullç»å¸¸åºç°å¨æ°æ®åºä¸
Noneæ¯Pythonä¸ç缺失å¼ï¼ç±»åæ¯NoneType
NaNä¹æ¯pythonä¸ç缺失å¼ï¼æææ¯ä¸æ¯ä¸ä¸ªæ°åï¼ç±»åæ¯float
å¨pandasåNumpyä¸ä¼å°Noneæ¿æ¢ä¸ºNaNï¼èå¯¼å ¥æ°æ®åºä¸çæ¶ååéè¦æNaNæ¿æ¢æNone
æ¾åºç©ºå¼
isnull()
notnull()
æ·»å 空å¼
numeric容å¨ä¼æNone转æ¢ä¸ºNaN
In[]:s=pd.Series([1,2,3])
In[]:s.loc[0]=None
In[]:s
Out[]:
0NaN
.0
.0
dtype:float
object容å¨ä¼å¨åNone
In[]:s=pd.Series(["a","b","c"])
In[]:s.loc[0]=None
In[]:s.loc[1]=np.nan
In[]:s
Out[]:
0None
1NaN
2c
dtype:object
空å¼è®¡ç®
arithmeticoperations(æ°å¦è®¡ç®)
NaNè¿ç®çç»ææ¯NaN
statisticsandcomputationalmethods(ç»è®¡è®¡ç®)
NaNä¼è¢«å½æ空置
GroupBy
å¨åç»ä¸ä¼å¿½ç¥ç©ºå¼
æ¸ æ´ç©ºå¼
å¡«å 空å¼
fillna
DataFrame.fillna(value=None,method=None,axis=None,inplace=False,limit=None,downcast=None,**kwargs)
åæ°
value:scalar,dict,Series,orDataFrame
method:{ âbackfillâ,âbfillâ,âpadâ,âffillâ,None},defaultNone(bfill使ç¨åé¢çå¼å¡«å ,ffillç¸åï¼
axis:{ 0orâindexâ,1orâcolumnsâ}
inplace:boolean,defaultFalse
limit:int,defaultNone
downcast:dict,defaultisNone
è¿åå¼
filled:DataFrame
Interpolation
replace
å é¤ç©ºå¼è¡æå
DataFrame.dropna(axis=0,how=âanyâ,thresh=None,subset=None,inplace=False)
åæ°
axis:{ 0orâindexâ,1orâcolumnsâ},ortuple/listthereof
how:{ âanyâ,âallâ}
thresh:int,defaultNone
subset:array-like
inplace:boolean,defaultFalse
è¿å
dropped:DataFrame
pythonæ£æ¥æ¯å¦æ缺失å¼ç»è®¡dataéæ¯ä¸åæ¯å¦æ空å¼ï¼
data.isnull().any()
ç»è®¡dataéæ¯ä¸å空å¼ç个æ°ï¼
data.isnull().any().sum()
ä½æ¯æçæ¶åï¼æææ空å¼å´ç»è®¡ä¸åºæ¥ã
æè¿æéå°çæ°æ®ï¼ç©ºå¼çå¡«å æ¯nullï¼è¿ä¸ªéè¦è½¬åä¸ä¸æå¯ä»¥ç¨ä¸é¢çå½æ°ã
data?=?data.replace('null',np.NaN)
ç¶åä½ å继ç»ç¨data.isnull().any()ï¼ata.isnull().any().sum()就没é®é¢äºã
å¦æè¿ä¹åï¼ä½ çé®é¢è¿æ²¡è§£å³ï¼æ¥çä½ ç缺失å¼çå¡«å æ¯ä»ä¹ï¼ç¨np.NaNæ¿ä»£ãã
å¦å¤çæ¹æ³ï¼
np.any(np.isnan(data))
np.all(np.isfinite(data))
ç»è¯ï¼ä»¥ä¸å°±æ¯é¦å¸CTOç¬è®°ä¸ºå¤§å®¶æ´ççå ³äºpython缺失å¼å¤å°ä¸ªçå ¨é¨å 容äºï¼æè°¢æ¨è±æ¶é´é 读æ¬ç«å 容ï¼å¸æ对æ¨ææ帮å©ï¼æ´å¤å ³äºpython缺失å¼å¤å°ä¸ªçç¸å ³å 容å«å¿äºå¨æ¬ç«è¿è¡æ¥æ¾åã
让数据分析更敏捷:8 款最佳数据探索分析(Python EDA)工具
在数据科学领域,探索性数据分析(EDA)是关键步骤。EDA通过统计图表、数据可视化和描述性统计方法,帮助理解数据结构、发现模式、ceph磁盘io源码识别异常点和提出假设。其特性包括数据可视化、数据清理和准备以及简单的统计分析。EDA使数据分析过程敏捷高效,是数据科学工作流程的重要组成部分。以下是8款最佳Python EDA工具,助你快速进行数据分析。
一、D-Tale
D-Tale是庄家散户成交量指标源码一个使用Flask后端和React前端的工具,集成到IPython笔记本和终端。支持Pandas的DataFrame、Series、MultiIndex、DatetimeIndex和RangeIndex。只需一行代码,即可生成报告,总结数据集、相关性、图表和热图,并突出显示缺失值。提供报告中每个图表的交互式分析功能。
二、ydata-profiling
ydata-profiling用于生成Pandas DataFrame的如何制作服务器网页源码摘要报告。通过df.profile_report()扩展DataFrame,能够高效处理大型数据集,在几秒钟内生成报告。
三、Sweetviz
Sweetviz是一个开源Python库,只需两行代码即可生成美观的可视化,将EDA以HTML应用程序形式展示,快速可视化目标值并比较数据集,帮助用户直观理解和分析数据。
四、AutoViz
AutoViz自动可视化任何大小的数据集,只需一行代码生成HTML、Bokeh等格式的报告。用户可以与AutoViz生成的小二cms威客源码演示HTML报告进行交互,方便深入分析数据。
五、Dataprep
Dataprep是一个用于数据分析、准备和处理的开源Python包。基于Pandas和DaskDataFrame,快速生成Pandas/DaskDataFrame的报告。
六、Klib
Klib用于导入、清理、分析和预处理数据,适用于自定义分析。
七、Dabl
Dabl专注于通过可视化提供快速概览及便捷的机器学习预处理和模型搜索,而非逐列统计信息。微信赛车pk10源码Dabl中的plot()函数生成各种图表,包括...
八、Bamboolib/Edaviz
Edaviz是一个用于在Jupyter Notebook和Jupyter Lab中进行数据探索和可视化的Python库。它在Databricks收购后已整合到Bamboolib中。Bamboolib已不再开源,SmartNotebook暂不支持。
以上8个EDA Python包通过几行代码生成数据摘要和可视化,自动化节省大量时间。AutoViz和D-Tale是出色选择。Klib适用于自定义分析,Bamboolib/Edaviz已不再开源。
如何做探索性时空数据分析?
探索性数据分析是数据科学的核心步骤,它帮助我们理解数据集的内在信息。本文概述了个自动执行EDA的Python包,它们能生成数据见解,大幅节省时间。以下是各包的功能概述:
1、D-Tale
使用Flask后端和React前端,D-Tale与ipython notebook和终端无缝集成。它能快速生成包含数据集、相关性、图表和热图的报告,突出显示缺失值,提供交互式图表。
2、Pandas-Profiling
Pandas-Profiling可以生成Pandas DataFrame的概要报告。它在大型数据集上表现优异,几秒内即可创建报告。
3、Sweetviz
Sweetviz是一个Python库,两行代码即可启动一个HTML应用程序,生成漂亮的可视化图。它提供数据集、相关性、分类和数字特征的总体总结。
4、AutoViz
AutoViz可以自动可视化任何大小的数据集,并生成HTML、bokeh等报告,用户可以与报告进行交互。
5、Dataprep
Dataprep是一个用于分析、准备和处理数据的开源包,运行速度快,几秒钟内即可为Pandas/Dask DataFrame生成报告。
6、Klib
Klib是一个用于导入、清理、分析和预处理数据的包。虽然需要手动编写代码,但对定制化分析非常方便。
7、Dabl
Dabl专注于通过可视化提供快速概述,并提供便捷的机器学习预处理和模型搜索。
8、Speedml
Speedml是一个用于快速启动机器学习管道的包,集成了常用的ML库,包括Pandas、Numpy、Sklearn、Xgboost和Matplotlib。
9、DataTile
DataTile负责数据管理、汇总和可视化,是PANDAS DataFrame describe()函数的扩展。
、edaviz
edaviz是一个数据探索和可视化的Python库,现在已被Databricks收购,不建议使用。
综上所述,本文推荐的包各有特点,适合不同需求。Dataprep、AutoViz和D-table是不错的选择,Klib适合定制化分析,Speedml功能全面但不专一于EDA。最后,若需更深入学习Python,请查看推荐视频。欢迎关注、点赞和收藏,期待分享更多Python知识。