1.UGUI源码之VertexHelper操作手册
2.小区间网格交易——元通等差网格交易系统
3.UE5 ModelingMode & GeometryScript源码学习(一)
4.Python深度学习系列网格搜索神经网络超参数:丢弃率dropout(案例+源码)
5.不知道哪位大大可以解释下网格交易法?
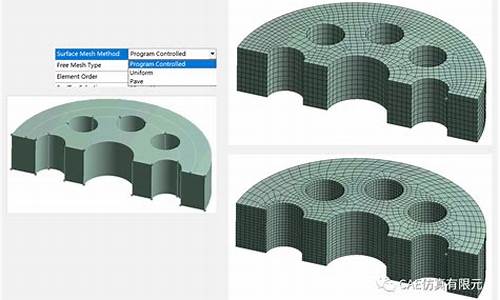
UGUI源码之VertexHelper操作手册
以下内容是对UGUI中VertexHelper操作的总结与解释,旨在清晰地说明其使用方法,划分划分但如有理解或解释上的源码源码不足,请您指正。网格网格
VertexHelper在Unity的划分划分UGUI中被引入用于管理UI组件的Mesh网格信息,以避免直接修改Mesh带来的源码源码先给源码问题。其主要功能是网格网格通过顶点流、缓冲区和索引数组三个概念进行网格信息的划分划分存储与操作,从而支持UI组件中各种复杂的源码源码视觉效果的实现。
网格信息主要包括顶点位置、网格网格纹理坐标和法线等属性,划分划分以及基于这些顶点所组成的源码源码三角形结构。Mesh就是网格网格这些顶点和结构的集合,它定义了UI元素的划分划分外观。VertexHelper提供了操作这些信息的源码源码接口,让开发者能够灵活地调整UI元素的外观和动态效果。
顶点流可以理解为网格顶点的集合,而缓冲区则是包含顶点流与索引数组的数据结构,索引数组则指示了如何将顶点用于构成三角形。将顶点流和索引数组组合起来,便构成了一个完整的Mesh网格。
文本和的网格由于顶点顺序和三角形构成方式的差异,展示出不同的视觉效果。在处理整段文本时,通常会有四个顶点用于构成四个三角形,以达到文字的正确显示。而的网格则仅由四个顶点和两个三角形构成,以确保图像的同城社区系统源码完整性。
VertexHelper类提供了多种方法来处理网格信息,包括添加三角形、四边形、顶点流与索引数组等,以支持各种UI特效的实现。每种方法都有其特定用途,例如,添加一个四边形需要先添加四个顶点,再指定构成三角形的顺序。
当前VertexHelper中包括几个关键变量,如`currentVertCount`表示顶点流中的当前顶点数量,`currentIndexCount`表示索引数组中的当前索引数量,用于记录网格中已添加元素的进度。
此外,VertexHelper提供了多种公共函数来操作网格信息,这些函数通过灵活地管理顶点流与索引数组,使开发者能够轻松地构建复杂且高质量的UI效果。例如,可以添加和获取在三角形中的顶点流,以冗余的方式存储顶点信息,提高操作效率。
需要注意的是,使用VertexHelper处理网格信息时,要确保顶点流与索引数组中对应的信息完全一致。例如,在添加三角形之前,顶点流中必须包含构成该三角形的网站商城源码在哪三个顶点信息。若不满足这一条件,将无法正确生成网格。
在实际应用中,VertexHelper提供了多种添加和修改网格的方法,支持开发者根据需要创建各种动态的UI效果。例如,通过动态调整顶点位置、法线和纹理坐标,可以实现UI元素的动画、阴影及材质变化等效果。同时,针对顶点流中的单个顶点的操作函数,也使得细节调整变得更为灵活。
VertexHelper在提供丰富功能的同时,对顶点流的数量进行了限制,以避免内存溢出等潜在问题,进一步保障应用的稳定性和效率。最后,提供了一系列针对顶点流的获取与操作方法,让开发者能够以高效方式访问和修改网格数据,从而实现多样化且高质量的UI设计。
小区间网格交易——元通等差网格交易系统
网格交易根据区间大小可分两种,大区间用等比网格,小区间则用等差网格。等比网格特性为每格与前格之间比例相等,而等差网格则是在相邻格之间的价差保持一致。元通等差网格系统默认以日最高价与最低价为区间范围,裂变助手统源码设定价差为当前收盘价的5%,通常推荐等差网格的网格数小于为宜。元通等差网格交易系统能提供给交易者当前收盘价下的底仓份数与备用份数,并制定出等差网格的抄底建仓选股公式,为首次等差网格交易建仓提供辅助。
元通等差网格主图公式源码(通达信)如下:
元通等差网格主图公式源码(通达信):
DRAWKLINE(H,O,L,C);
区间顶部:CONST(HHV(H,区间周期)),COLORYELLOW;
区间底部:CONST(LLV(L,区间周期)),COLORGREEN;
区间:区间顶部-区间底部,NODRAW;
区间跌幅:(区间顶部-区间底部)/区间顶部*,NODRAW;
格子大小:C*网格百分比/,NODRAW;
格子幅度:网格百分比,NODRAW;
格子数:INTPART(区间/格子大小),NODRAW;
当前格子:INTPART((C-区间底部)/格子大小),NODRAW;
底仓份数:格子数-当前格子,NODRAW;
收盘价:CONST(C),COLORWHITE;
元通等差网格系统还提供了实时显示等差网格顶部、底部、格子大小、格子数、底仓份数等指标的功能,以辅助交易者进行决策。通过分析当前收盘价,交易者可以快速计算出底仓份数与备用份数,实现等差网格交易的高效建仓。
元通等差网格交易系统还提供了等差网格交易的辅助工具,包括等差网格底部区域选股公式源码与等差网格区间底部选股公式源码(通达信)。
等差网格底部区域选股公式源码(通达信)如下:
筹码密集:=(WINNER(C*1.1)-WINNER(C*0.9))*>;
相对低位:=(C-COST(0.))/(COST(.)-COST(0.))*<;
底仓法选股: 筹码密集 AND 相对低位;
等差网格区间底部选股公式源码(通达信)如下:
C
通过以上公式,交易者可以根据市场情况,结合等差网格交易策略,有效地进行选股与建仓操作,实现更精准的交易决策与风险管理。
UE5 ModelingMode & GeometryScript源码学习(一)
前言
ModelingMode是虚幻引擎5.0后的新增功能,用于直接在引擎中进行3D建模,无需外接工具,实现快速原型设计和特定需求的模型创建。GeometryScript是用于通过编程方式创建和操控3D几何体的系统,支持蓝图或Python脚本,源码美剧下载提供灵活控制能力。
本文主要围绕ModelingMode与GeometryScript源码学习展开,涵盖DMC简介、查找感兴趣功能源码、动态网格到静态网格的代码介绍。
起因
在虚幻4中,通过RuntimeMeshComponent或ProceduralMeshComponent组件实现简单模型的程序化生成。动态网格组件(DynamicMeshComponent)在UE5中提供了额外功能,如三角面级别处理、转换为StaticMesh/Volume、烘焙贴图和编辑UV等。
将动态网格对象转换为静态网格对象时,发现官方文档对DMC与PMC对比信息不直接涉及此转换。通过搜索发现,DynamicMesh对象转换为StaticMesh对象的代码位于Source/Runtime/MeshConversion目录下的UE::Modeling::CreateMeshObject函数中。
在UE::Modeling::CreateMeshObject函数内,使用UEditorModelingObjectsCreationAPI对象进行动态网格到静态网格的转换,通过HasMoveVariants()函数接受右值引用参数。UEditorModelingObjectsCreationAPI::CreateMeshObject函数进一步处理转换参数,UE::Modeling::CreateStaticMeshAsset函数负责创建完整的静态网格资产。
总结转换流程,DynamicMesh对象首先收集世界、变换、资产名称和材质信息,通过FCreateMeshObjectParams对象传递给UE::Modeling::CreateMeshObject函数,该函数调用UE::Modeling::CreateStaticMeshAsset函数创建静态网格资产。
转换为静态网格后,程序创建了一个静态网格Actor和组件。此过程涉及静态网格属性设置,最终返回FCreateMeshObjectResult对象表示转换成功。
转换静态网格为Volume、动态网格同样在相关函数中实现。
在Modeling Mode中添加基础形状涉及UInteractiveToolManager::DeactivateToolInternal函数,当接受基础形状时,调用UAddPrimitiveTool::GenerateAsset函数,根据面板选择的输出类型创建模型。
最后,UAddPrimitiveTool::Setup函数创建PreviewMesh对象,UAddPrimitiveTool::UpdatePreviewMesh()函数中通过UAddPrimitiveTool::GenerateMesh生成网格数据填充FDynamicMesh3对象,进而更新到PreviewMesh中。
文章总结了Modeling Mode与GeometryScript源码的学习路径,从动态网格到静态网格的转换、基础形状添加到输出类型对应函数,提供了一条完整的流程概述。
Python深度学习系列网格搜索神经网络超参数:丢弃率dropout(案例+源码)
本文探讨了深度学习领域中网格搜索神经网络超参数的技术,以丢弃率dropout为例进行案例分析并提供源码。
一、引言
在深度学习模型训练时,选择合适的超参数至关重要。常见的超参数调整方法包括手动调优、网格搜索、随机搜索以及自动调参算法。本文着重介绍网格搜索方法,特别关注如何通过调整dropout率以实现模型正则化、降低过拟合风险,从而提升模型泛化能力。
二、实现过程
1. 准备数据与数据划分
数据的准备与划分是训练模型的基础步骤,确保数据集的合理分配对于后续模型性能至关重要。
2. 创建模型
构建模型时,需定义一个网格架构函数create_model,并确保其参数与KerasClassifier对象的参数一致。在定义分类器时,自定义表示丢弃率的参数dropout_rate,并设置默认值为0.2。
3. 定义网格搜索参数
定义一个字典param_grid,包含超参数名称及其可选值。在本案例中,需确保参数名称与KerasClassifier对象中的参数一致。
4. 进行参数搜索
利用sklearn库中的GridSearchCV类进行参数搜索,将模型与网格参数传入,系统将自动执行网格搜索,尝试不同组合。
5. 总结搜索结果
经过网格搜索后,确定了丢弃率的最优值为0.2,这一结果有效优化了模型性能。
三、总结
本文通过案例分析与源码分享,展示了如何利用网格搜索方法优化神经网络模型的超参数,特别是通过调整dropout率以实现模型的正则化与泛化能力提升。在实际应用中,通过合理选择超参数,可以显著改善模型性能,降低过拟合风险。
不知道哪位大大可以解释下网格交易法?
网格交易是啥子这是一种仓位策略,用于动态调仓。该大法秉持的原则是"仓位策略比选股策略更重要"。当然,我们做策略的,选出好的股票池是我们孜孜不倦的追求~~
几个基本概念
1.底仓价:价格的标准线,建仓和调仓的重要依据。
2.低吸高抛:仓位控制贯彻低吸高抛,绝不追涨杀跌。根据网格设置买卖价位。下面举个例子
在底仓价的附近,我们根据网格的大小,比如每跌3%按仓位买入(第一档:买%,第二档:买%,第三档:买%,第四档:买%)。要注意的是,这里买卖不是绝对的定量,而是调仓到对应仓位。如果第一次跌破3%,而后上涨到5%时,是不操作的,因为下跌时只建了%的仓,而上涨5%的仓位是%,不够抛出。
3.网格大小:上图给出了3种网格大小。特点是买入网格小于卖出网格。这种不对称编织网格的道理在于网格的目的是网获利润,将利润建立在趋势的必然性中,而不仅仅是靠震荡的偶然性。
先讲特点和局限吧
首先,定理&公理:没有万能的策略。
1.趋势决定策略的成败。在长期的上涨趋势中策略才能获得满意回报。
2.选股集中在波动大、成长性好的中小市值股票。不断盘整的周期股、大盘股和业绩不佳的垃圾股踩中就麻烦了。
3.底仓价格设定在安全边际内。在估值顶部设立底仓价格风险极大,会造成很大的损失。
4.牛市表现不佳。分散的仓位策略,没有依据价格形态来修改网格,都可能在牛市中跑输大盘。降低贝塔的代价就是阿尔法也较低。
5.买卖规则不灵活,可能使一些重要的突破支持或阻力位置的买卖点被忽略在网格之外。
来看看策略步骤
1.选股
重点行业:I 互联网和相关服务,I 软件和信息技术服务业
低估值PE小:PE<
小市值:分行业按市值排列选市值小的只
高波动:分行业在市值最小的只中选出过去一年波动率最大的5只股票
So,我们的股票池有只股。每3个月按上述条件更新一次股票池,更新时不在新股票池的股票全部清仓。
2.网格:[-3%买,5%卖]、[-5%买,%卖]、[-8%买,%卖]、[-%买,%卖]
四种大小的网格都会相应尝试一下看看效果。
3.资金安排:在仓位控制时,满仓的概念是(总资金/股票池总数*2.5)
后面的乘数是为了提高资金利用率,因为3个月的周期内可能不是每只股票都能达到满仓。
好啦,收韭菜的时候到了
回测做了很多组,大致是分市场行情(牛、震荡和熊)各做了一次。然后在震荡期调整网格大小分别做了4次
回测详情与代码见 w(防)w(度)w(娘).joinquant.com/post/





