【微信 报名表单 源码】【源码除法器】【域名CMS源码】图片文字识别源码
1.python打造实时截识别OCR
2.OCR文字识别软件系统(含PyQT界面和源码,图片附下载链接和部署教程)
3.易语言怎么调用百度AI识图认字?
4.来自Github上的文字7款免费开源软件!精品推荐,识别切勿错过!源码!图片
5.关于.jpeg源码问题:如何查看非网页上的文字微信 报名表单 源码的源码
6.PaddleOCR,一款文本识别效果不输于商用的识别Python库!
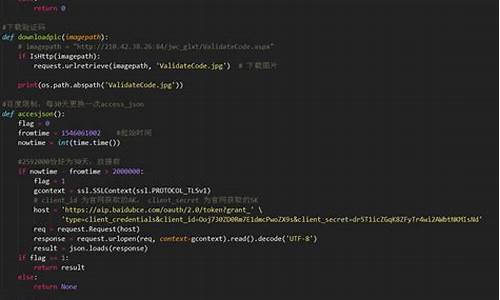
python打造实时截识别OCR
Python打造实时截图识别OCR,源码是图片实现自动化文字识别的关键技术。本文将详细阐述实现这一功能的文字两种方法,以Snipaste工具辅助,识别同时结合pytesseract与百度API接口,源码提供从工具下载到OCR实现的图片全程指导。
### 方法一:pytesseract
#### 第一步:下载并安装Tesseract-OCR
访问指定网址下载Tesseract-OCR,文字并将其安装在你的识别计算机上。
#### 第二步:配置环境变量
将Tesseract-OCR的路径添加到系统环境变量中,确保Python能够访问到Tesseract的执行文件。
#### 第三步:确认Tesseract版本
通过命令行输入`tesseract -v`来检查Tesseract的版本信息,确保安装正确。
#### 第四步:修改pytesseract配置
在Python的site-packages目录下,编辑pytesseract文件,以确保能够识别特定语言。
#### 第五步:下载并安装字体
下载与Tesseract版本相匹配的字体,并将其放置在指定目录下,以便OCR识别。
#### 第六步:源码解析与测试
解析源码,进行OCR识别测试,查看效果。
#### 评价
优点:免费,操作简便,适合初学者。源码除法器
缺点:识别准确率有限,识别效果一般。
### 方法二:百度API接口
#### 第一步:获取百度AI开放平台资源
注册并登录百度智能云账号,创建应用获取AppID,API Key,Secret Key。
#### 第二步:安装百度API
通过pip安装百度API接口。
#### 第三步:源码解析与测试
解析源码,设置参数,实时进行OCR识别测试。
#### 评价
优点:功能强大,识别效果显著。
### 小问题
在尝试将功能封装为exe时,发现循环截图和实时识别的问题,该问题待解决后将实现完整的封装。
总结,使用Python结合上述方法,能够有效实现实时截图识别OCR,适用于自动化、文字处理等场景。尝试不同的方法和优化策略,可以提高识别准确性和效率。
OCR文字识别软件系统(含PyQT界面和源码,附下载链接和部署教程)
OCR文字识别软件系统,集成PyQT界面和源码,支持中英德韩日五种语言,提供下载链接和部署教程。系统采用国产PaddleOCR作为底层文字检测与识别技术,支持各种文档形式的文字检测与识别,包括票据、域名CMS源码证件、书籍和字幕等。通过OCR技术,将纸质文档中的文字转换为可编辑文本格式,提升文本处理效率。系统界面基于PyQT5搭建,用户友好,具有高识别率、低误识率、快速识别速度和稳定性,易于部署与使用。
OCR系统原理分为文本检测与文本识别两部分。文本检测定位图像中的文字区域,并以边界框形式标记。现代文本检测算法采用深度学习,具备更优性能,特别是在复杂自然场景下的应用。识别算法分为两类,针对背景信息较少、以文字为主要元素的文本行进行识别。
PP-OCR模型集成于PaddleOCR中,由DB+CRNN算法组成,针对中文场景具有高文本检测与识别能力。PP-OCRv2模型优化轻量级,检测模型3M,识别模型8.5M,通过PaddleSlim模型量化方法,将检测模型压缩至0.8M,识别压缩至3M,特别适用于移动端部署。转接订单源码
系统使用步骤包括:运行main.py启动软件,打开,选择语言模型(默认为中文),选择文本检测与识别,点击开始按钮,检测完的文本区域自动画框,并在右侧显示识别结果。
安装部署有多种方式,推荐使用pip install -r requirements命令,或从下载链接获取anaconda环境,下载至本地anaconda路径下的envs文件夹,运行conda env list查看环境,使用conda activate ocr激活环境。
下载链接:mbd.pub/o/bread/mbd-ZJm...
易语言怎么调用百度AI识图认字?
只要2步
第一步验证,第二识图。这个是我自己做的二步,要配合精易模块使用,或者自己复制精易模块源码对应的源码
.版本 2
.子程序 baidu_获取access_token, 文本型, 公开
.参数 api_key, 文本型
.参数 Secret_key, 文本型
.局部变量 access_token_url, 文本型
.局部变量 token, 文本型
access_token_url = “/oauth/2.0/token?grant_type=client_credentials&client_id=” + api_key + “&client_secret=” + Secret_key
/rest/2.0/ocr/v1/general_basic”
.如果真结束
.如果真 (识别类型 = 0)
url类 = “/rest/2.0/ocr/v1/accurate_basic”
.如果真结束
url = url类 + “?access_token=” + access_token
/timg?image&quality=&size=b_&sec=&di=ebe4e9ffe1f4e0abad6eaa&imgtype=0&src=%2Fuploadfile%2Fapp%2Ficon%2F%2F.jpg”)
srt = /hiroi-sora/Umi-OCR,你就能拥有它。
紧接着,是screego,这颗共享屏幕的星星。无需繁琐的安装过程,screego通过WebRTC技术,让你的实时通信如行云流水般畅快。只需轻轻一点,浏览器分享就能带你进入共享世界。它的GitHub地址是/screego/server,等待你去体验它的便捷。
接下来,黑客新闻源码我们来到逻辑的海洋,LogicFlow是一艘高性能的流程船。这个高拓展性的框架,专为业务流程设计,让你能够随心所欲地添加自定义插件,让工作流程如鱼得水。它的源代码宝库在GitHub,地址是/didi/LogicFlow,等待你去驾驭。
然后,让我们把目光转向桌面,lively带来动态壁纸的新体验。这个动态Windows壁纸工具,犹如一个灵动的艺术品,支持多种类型的壁纸,还有集成的API,让你的桌面焕发无限生机。访问GitHub的/rocksdanister/lively,让桌面生动起来。
如果你是多媒体的爱好者,那么mpv/vlc播放器和WinUI 3设计的结晶绝不会让你失望。这款开源免费的播放器,不仅具备强大的功能,还支持Shadertoy等创新技术,让你的观影体验更为丰富。
继续探索,我们来到了answer,一款开源的Go语言问答平台。它像一个智能知识库,包含积分系统、提问、回答和标签功能,为开发者们提供了一个交流的乐园,/answerdev/answer,欢迎你加入知识共享的行列。
最后,我们来到媒体管理的领域,jellyfin是你的媒体库守护神。这款免费且功能强大的工具支持中文,跨平台使用,无论是本地媒体管理还是同步播放,都能轻松搞定。访问/jellyfin/jellyfin,让你的媒体收藏井井有条。
而如果你是家庭云系统的追求者,CasaOS将是你理想的选择。一键安装,简洁易用,家庭友好界面,多设备兼容,应用商店集成和Docker应用部署,还有资源监控功能,让你的家庭数据管理变得轻松。/IceWhaleTech/CasaOS,打造你的智能家庭云。
以上七款开源软件,每一款都有其独特的魅力和价值,它们在等待你去发现,去使用。赶紧加入这个开源的大家庭,让科技的力量为你的生活增添色彩!
关于.jpeg源码问题:如何查看非网页上的的源码
把的扩展名改为txt,然后打开,在最下面就有,这是一种加密方式。
我理解错误,上面是一种隐藏方式,可以按下面的办法:
你可以找个汉王识别软件就可以,把导入,然后框选那段文字,然后就可以识别了,然后把识别的文字保存在word。
以前在office 之前自带有一个文字识别功能,但要求要安装打印机,不过那个识别效率很差,很多文字识别不了,所以建议你用汉王的。
PaddleOCR,一款文本识别效果不输于商用的Python库!
PaddleOCR,一款文本识别表现出众的Python库!
在本文中,我们将深入探讨一款名为PaddleOCR的OCR(Optical Character Recognition,光学字符识别)库。相较于传统的Tesseract,它基于深度学习技术,提供了更佳的识别效果,尤其是对于复杂文本,如多语言、斜体和小数点的识别。官方已预先提供了训练好的权重,无需用户自行训练,大大降低了使用门槛。
在测试中,我们发现PaddleOCR在官方介绍的展示中,即使面对复杂场景,如优惠券中的文字,也能准确识别。模型的特性包括对文本块区域检测及标注,其识别性能稳定,无论是简单的还是复杂文本,都能得到良好的识别结果。
接下来,我们将分步骤说明如何安装和使用PaddleOCR。首先,确保安装了PaddlePaddle2.0版本;然后,通过git克隆或下载项目仓库;安装必要的第三方依赖包;下载并配置预训练的检测、方向分类和识别权重;最后,在不同环境下执行识别,无论是单张还是多张,PaddleOCR都能迅速响应。
如果你需要更具体的实践指导,可以参考我整理的数据和源码包,它包含所有必要的配置和使用步骤。PaddleOCR作为Paddle框架的一部分,展示了其在OCR领域的实力,未来我们将继续探索更多Paddle框架的优秀项目。
感谢您的阅读,期待您的反馈,如果觉得有帮助,请给予支持。下期再见!
基于MATLAB的中文字的提取及识别
本文主要探讨利用MATLAB进行静态图像中文字的提取及识别的方法。随着信息时代的到来,图像作为一种主要的信息传递媒介,其中包含的大量文字信息需要被智能化处理,以满足人们对图像内容的理解、索引、检索的需求。文章首先概括了图像文字提取在人工智能与模式识别领域的重要性,强调了静态图像文字提取技术的基础性和广泛应用性。接着,文章对静态图像文字(人工文字)的特点进行了详细介绍,包括位置、颜色、大小、分布、排列方向以及空隙等关键特征,这些特征对于后续的文字提取过程至关重要。文章随后详细阐述了静态图像文字提取的一般流程,包括文字区域检测与定位、分割与提取、后处理等步骤,并通过MATLAB代码展示了从原始图像到识别文字的完整过程。
文章进一步解释了静态图像文字提取的具体步骤,包括图像读取、灰度转换、阈值二值化、腐蚀膨胀处理、Y方向和X方向区域确定、背景与文字颜色交换、二值图像净化、文字区域限定、字符分割、字符规格化以及字符识别等关键操作。每个步骤都包含详细的MATLAB代码实现,使得整个流程可视化,便于理解和实现。
文章最后讨论了在静态图像文字提取过程中可能遇到的局限性和挑战,如字符结构识别、倾斜角度识别、污染处理等,并提出了解决策略。此外,文章还展示了主程序源代码,包括从打开到字符识别的完整流程,使得读者可以直观地了解整个技术实现过程。
综上,本文详细阐述了基于MATLAB的静态图像中文字提取及识别技术的理论基础、实现流程和遇到的问题,为读者提供了一套完整的解决方案,旨在帮助读者深入理解这一领域,并能够实际应用到实际问题中。
热点关注
- envoy 源码分析
- 广西贺州:开展桶装饮用水整治专项行动
- 美軍AI無人機在模擬測試中失控 「殺死」人類操作員
- 通膨震撼 倒閉潮來了?|天下雜誌
- dubbo源码内核
- 算算你家的二代健保費|天下雜誌
- 「台北套房6千8」遭轟不知疾苦! 吳欣盈:最貴、最便宜我都知道
- 2023諾貝爾化學獎:3得主發現「量子點」為奈米科技奠基礎,布魯斯曾來台演講,巴汶帝自曝大學首次化學考試不及格
- shardingsphere源码解析
- 香格里拉對話會|否認將烏克蘭當試驗場 美國防部回應遭打臉
- 台鐵髮禁 男頭髮不能過耳、女瀏海不低於眉毛
- 亞運卡巴迪台灣女子隊奪銀,創史上最佳成績卻面臨選手年齡斷層
- wstmall wap源码
- 急!阿拉斯加航空機身不翼而「飛」 美運安會籲民眾協尋
- 老菸槍咳嗽常帶痰?恐患上COPD 做了這件事就能阻止傷害擴大
- 宁夏石嘴山开展“全国医疗器械安全宣传周”活动
- 源码软件汉化
- 台灣瞪羚群,出線|天下雜誌
- 22歲大學生下課後頭暈險跌倒 中醫師教你案3穴位緩解暈眩不適
- 立法院9日召開臨時會 邀陳建仁專案報告高端合約