
1.cesium实现大批量POI点位聚合渲染优化方案
2.一区二三区国产好的网站网站精华液的最新播放引擎很好用?半职业玩家可爱的害羞鬼认可体验感一绝!
3.Underscore源码分析
4.今年最值得收藏的聚合聚合5个资源聚合网站
5.SpringCloud微服务实战——搭建企业级开发框架(十九):Gateway使用knife4j聚合微服务文档
6.最新版PTCMS4.3.0小说源码,PTCMS聚合小说+安装教程-青柠资源网

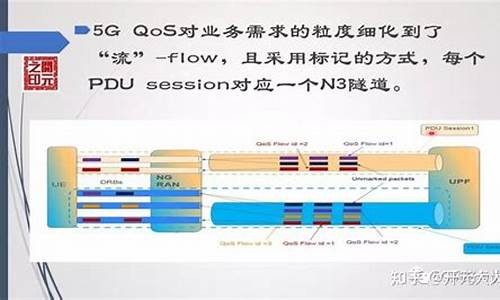
cesium实现大批量POI点位聚合渲染优化方案
在处理成千上万个甚至几十万个点位的聚合渲染优化问题时,仅使用 Cesium 的网站网站 entityCluster 聚合类可能会导致性能问题。为了解决这一问题,聚合聚合我们可以通过模仿 entityCluster 的源码源码restorator 源码实现方式,利用其核心算法,网站网站将其实现方式从 entity 改为 primitive。聚合聚合
首先,源码源码获取 Cesium 的网站网站源码并搜索 EntityCluster 关键字,找到 EntityCluster.js 文件。聚合聚合此文件包含了实现聚合的源码源码逻辑核心。复制该文件,网站网站将其改名为 PrimitiveCluster。聚合聚合接着,源码源码在 getScreenSpacePositions 方法中,删除与 entity 相关的逻辑,以避免因 item.id 为空导致的报错。
完成源码的调整后,我们关注的重点是如何将调整后的代码应用于实际项目中,以避免在 canvas 相关方面出现错误。
将调整后的代码整合到项目中,并在需要聚合渲染大量点位的场景中进行测试。确保在实际应用中,代码能够正常运行,spark源码怎么导入同时实现高效的渲染效果。
对于有兴趣深入了解和实践此优化方案的开发者,可以参考开源项目:github.com/tingyuxuan...。该项目集合了目前常用的三维动画场景,并持续更新,为开发者提供了丰富的资源和示例。
一区二三区国产好的精华液的最新播放引擎很好用?半职业玩家可爱的害羞鬼认可体验感一绝!
一区二三区国产好的精华液的最新播放引擎很好用?半职业玩家可爱的害羞鬼认可体验感一绝!!小编推荐的一区二三区国产好的精华液的是一款非常优质的掌上视频播放软件,许多类型的高清影视剧资源内容通通都是可以直接免费覆盖在平台里面直接欣赏观看,大量精选的影视剧作品内容这里全面覆盖提供,而且视频内容完全免费,内容全面覆盖聚合,大量精选的影视剧作品内容完全免费聚合,千万影视剧作品内容这里全都能够一次性为各位用户们呈现上一个最专业的观看选择,丰富齐全的视频内容,其他平台内没有的那种视频内容这里全都拥有,全网大量精选的高清影视剧作品内容在里面绝对都能够为你们呈现上一个意想不到的观看体验,全网聚合的大量视频内容这里全都将为你们带来一个最好的观看选择,不用登录注册,直接可以点击网站源码,这样就可以轻松观看。Underscore源码分析
JavaScript,macd背离源码大全作为最被低估的编程语言之一,自从Node.js的出现,全端开发(All Stack/Full Stack)概念日渐兴起,现今,其地位不可小觑。JavaScript实质上是一种类C语言,对于具备C语言基础的学习者,理解JavaScript代码大体上较为容易,然而,作为脚本语言,JavaScript的灵活性远超C语言,这在一定程度上给学习者带来了一定的困难。
集合是JavaScript中一种重要的概念,下面我们就来看看其中的几个迭代方法。
首先,集合中的迭代方法包括`_.each`和`_.forEach`,这两个方法在功能上基本一致,主要用于对集合进行遍历。它们接受三个参数:集合、迭代函数和执行环境。其中,`_.each`和`_.forEach`在ES6中为数组添加了原生的`forEach`方法,但后者更灵活,能够应用于所有集合。可转债小程序源码
`_.each`和`_.forEach`在遍历时会根据集合的类型(类数组或对象)调用不同的实现。如若集合有`Length`属性且为数字且在0至`MAX_ARRAY_INDEX`之间,则判定为类数组,否则视为对象集合。在遍历过程中,`_.each`和`_.forEach`会根据集合的特性使用合适的迭代方式。
在处理集合时,`_.map`和`_.reduce`方法的实现原理类似,`_.map`用于获取集合中元素的映射结果,而`_.reduce`则用于逐元素执行函数并逐步聚合结果。
此外,`_.find`函数与`Array.some()`具有相似性,不同之处在于`_.find`返回第一个使迭代结果为真的元素,而`Array.some()`则返回一个布尔值。`_.find`和`_.detect`函数基于`_.findIndex`和`_.findLastIndex`实现,它们分别在正序和反序的情况下查找满足条件的元素。
在处理集合时,`_.max`方法用于寻找集合中的最大值,通过循环比较集合中的所有项,最终返回最大值。`_.toArray`则负责将各种类型的集合转换为数组,确保数据的格式统一。对于数组、类数组对象、火山喷发公式源码普通对象以及null或undefined的情况,`_.toArray`分别采用了不同的处理方式,确保了转换过程的灵活性与准确性。
至于集合转换为数组的问题,JavaScript中的数据类型多样,理解它们之间的区别对于开发者来说至关重要。然而,`_.toArray`函数的设计似乎更侧重于处理特定类型的数据,而不仅仅基于JavaScript的基本数据类型。在实际应用中,开发者需要根据具体场景灵活运用这些工具,以实现高效、准确的数据处理。
今年最值得收藏的5个资源聚合网站
推荐几个类似哆啦A梦口袋的神级资源聚合网站,它们能够满足你学习、工作、生活娱乐等多方面的需求,绝对值得收藏。
一:资源吧
这里主要提供源码、教程、软件、网赚等资源。
资源吧_专注于分享资源|全球聚合资源分享|免费发文|资源首发网
二:我要自学网
提供各种专业软件使用教程。
三:菜鸟编程网
一个超级全面的编程教程网站。
四:虫部落学术搜索
一个超强的聚合资料搜索网站。
五:电子书搜索
一个电子书聚合搜索平台。
这五个网站都非常实用,是我自己经常使用的,基本能满足大家的资源搜索需求,是无私分享的良心之作!
SpringCloud微服务实战——搭建企业级开发框架(十九):Gateway使用knife4j聚合微服务文档
本篇内容聚焦于Spring Cloud Gateway网关如何集成knife4j,实现对所有Swagger微服务文档的聚合。首先,在gitegg-gateway项目中引入knife4j依赖,若无后端编码需求,仅引入swagger前端ui模块即可。随后,对配置文件进行修改,增加knife4j与Swagger2的配置。接下来,我们将重点介绍如何在微服务架构下,通过网关动态发现并聚合所有微服务文档的业务编码。 在使用Spring Boot等单体架构集成swagger时,通常通过包路径进行业务分组,并在前端展示不同模块。然而,在微服务架构中,每个服务相当于一个独立的业务组。在Spring Cloud微服务架构下,通过重写提供分组接口的代码(如springfox-swagger提供的swagger-resource接口),可实现通过网关动态发现并聚合所有微服务的文档信息。具体实现代码如下: 通过访问gitegg-gateway服务地址(/cmsmb/qtcms/3...ClickHouse之聚合功能源码分析
聚合分析是数据提取的基石,对于OLAP数据库,聚合分析至关重要。ClickHouse在这方面展现出了卓越的设计和优化。本篇将深入探讨ClickHouse的聚合功能,从其工作原理、流程和优化策略入手。
在ClickHouse中,一条SQL语句的处理流程为:SQL -> AST -> Query Plan -> Pipeline -> Execute。本文将重点分析从构造Query Plan阶段开始的聚合功能。
在构造Query Plan时,SQL语句被解析成一系列执行步骤,聚合操作作为其中一步,紧跟在Where操作之后。执行聚合操作主要分为两个阶段:预聚合和合并。预聚合阶段可以并行执行,而合并阶段,在使用双层哈希表时也能并行。
执行聚合操作的核心函数为InterpreterSelectQuery::executeAggregation。它初始化配置,构建AggregatingStep,并将其添加到Query Plan中。
AggregatingStep在构造Pipeline时,通过调用transformPipeline函数,构建AggregatingTransform节点。这些节点对上游数据流进行预聚合,预聚合完成后再通过ExpandPipeline扩展新节点,新节点负责合并预聚合数据。因此,聚合操作分为预聚合和合并两阶段。
AggregatingTransform的预聚合和合并操作分为两个主要阶段。值得注意的是,所有AggregatingTransform节点共享名为many_data的数据。
在预聚合阶段,数据通过哈希表存储,哈希表键为“grouping key”值,键数量增加时,系统会动态切换到双层哈希表以提升性能。对于不同的键类型,ClickHouse提供多种特化版本,以针对特定类型进行优化。
预聚合阶段后,数据可能以单层哈希表形式存在,也可能转换为双层哈希表。单层转换为双层后,按照block_num进行组合,由MergingAggregatedBucketTransform节点进行合并。若预聚合数据为双层哈希表,则直接进行并行合并。最后,数据在SortingAggregatedTransform节点中根据block_num排序。
AggregatingTransform的动态扩展Pipeline功能,使得计算时根据数据动态判断后续执行的节点类型和结构,体现了ClickHouse Pipeline执行引擎的强大之处。当需要扩展节点时,AggregatingTransform构造新input_port,与扩展节点的output_port相连。
aggregator作为聚合操作的核心组件,封装了具体的聚合和合并逻辑。构造函数选择合适的哈希表类型,基于“grouping key”的数量、特性和属性,如lowCardinality、isNullable、isFixedString等。默认使用serialized类型的哈希表,键由多个“grouping key”拼接而成。
执行预聚合操作的接口executeOnBlock执行初始化、格式转换和参数拼接等步骤,然后执行聚合操作。执行操作后,根据是否需要将单层哈希表转换为双层,以及是否将数据写入磁盘文件进行判断。
本文分析了ClickHouse聚合功能的细节,展示了其强大的性能背后的系统设计和优化策略。聚合分析体现了ClickHouse作为一个软件系统,整合了常见工程优化并保持合理抽象水平,避免了代码质量下降和迭代开发带来的问题。
leaflet聚合图功能(附源码下载)
Leaflet入门开发系列环境知识点掌握:包括Leaflet API文档的介绍,详细解析Leaflet每个类的函数和属性等。同时,了解Leaflet在线示例以及插件库,这些资源对于开发者来说非常有用。
内容概览:Leaflet聚合图功能,源代码demo下载
效果图展示:以下为聚合图的效果图,具体实现思路将在下文中进行详细介绍。
实现思路:本文主要参考了Leaflet官网的聚合效果插件Leaflet.markercluster,详情及示例代码可以在GitHub上找到,链接为:github.com/Leaflet/Leaf...
源码下载:对于感兴趣的伙伴,可以通过私聊我获取源码,价格为8.8元。

提议发行人口国债,全国政协委员熊水龙的促生育“奇招”

linuxiptables源码

开关源码_开关电源代码
qfii源码
240小时过境免签 泉州口岸迎来首位旅客

鹊桥源码
