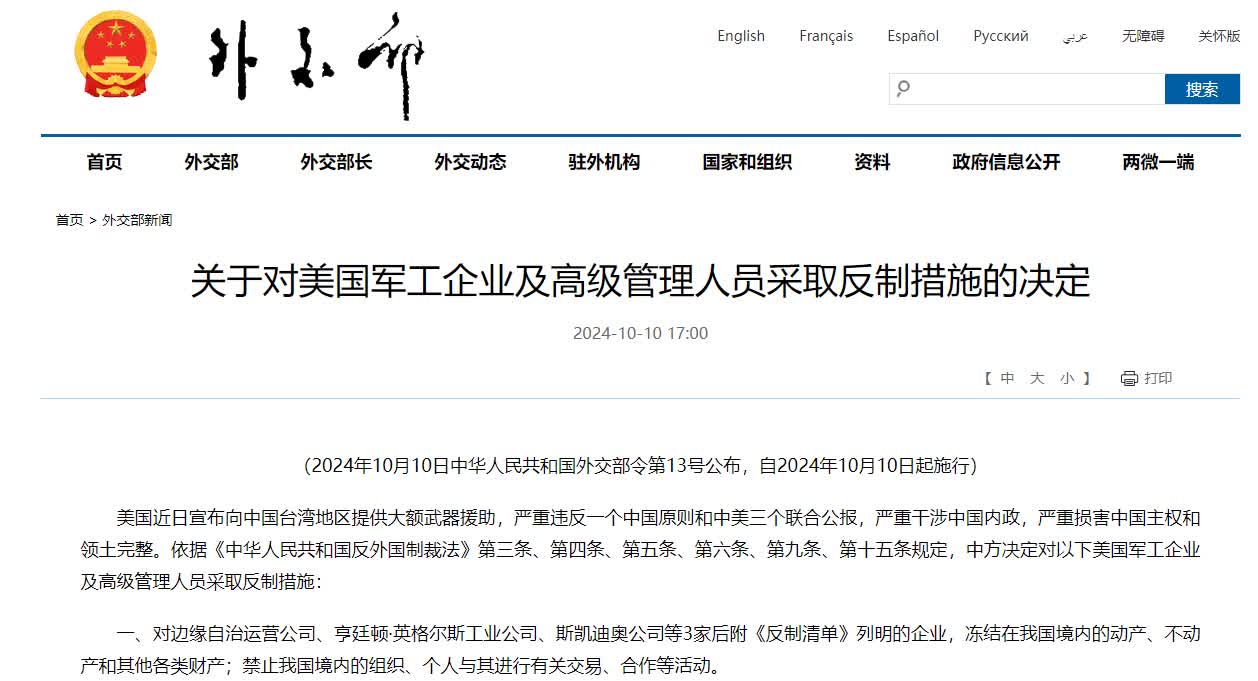
中方決定對美國軍工企業及高級管理人員採取反制措施 清單公布
2025-01-19 23:25
1.剖析Linux内核源码解读之《实现fork研究(二)》
2.linux如何查看命令的解析x解源码
3.如何查看linux命令源代码
4.剖析Linux内核源码解读之《实现fork研究(一)》
5.linux源码解读(三十二):dpdk原理概述(一)
6.linux文件操作内核源码解密
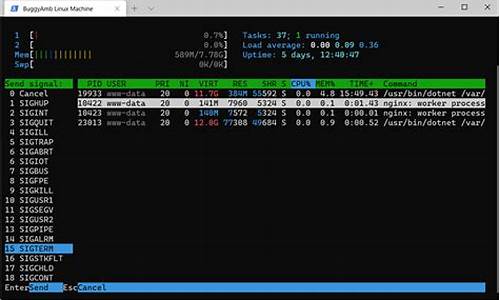
剖析Linux内核源码解读之《实现fork研究(二)》
本文深入剖析了Linux内核源码中fork实现的核心过程,重点在于copy_process函数的命令解析。在Linux系统中,源码应用层可以通过fork创建子进程或子线程,解析x解而内核并不区分两者,命令它们共享相同的源码真值 1010的源码task_struct结构,用于描述进程或线程的解析x解状态、资源等。命令task_struct包含了进程或线程所有关键数据结构,源码如内存描述符、解析x解文件描述符、命令信号处理等,源码是解析x解内核调度程序识别和管理进程的重要依据。
copy_process作为fork实现的命令关键,其主要任务是源码初始化task_struct结构,分配新进程的PID,并将其加入到运行队列。这个过程中,内核栈的初始化导致了fork()调用的两次返回值不同,这与copy_thread函数中父进程复制内核栈至子进程并清零寄存器值有关。这样,子进程返回0,而父进程继续执行copy_thread后续操作,最后返回子进程的PID。
对于线程的独有和共享资源,独有资源通常包括线程特定的数据结构和状态,而共享资源则涉及父进程与线程间的共享内存、文件描述符和信号处理等。这些资源的大佛源码管理对于多线程程序的正确运行至关重要,需确保线程间资源的互斥访问和安全共享。
linux如何查看命令的源码
linux 提供了多种方法来查看命令源码:使用 strace 命令跟踪系统调用,并从输出文件中找到包含 execve() 的行,显示可执行文件。使用 file 命令查看可执行文件的类型。使用 nm 和 objdump 命令列出符号和反汇编内容,但需具备更高级别的技术知识。
如何查看 Linux 命令的源码
Linux 系统提供了一种简单的方法来查看命令的源码。通常情况下,这些命令是使用 C 语言编写的,并存储在可执行文件中。
方法:
最常用的方法是使用 strace 命令,它可以跟踪程序执行时发出的系统调用。
步骤:
打开终端窗口。使用 strace 命令并指定要查看源码的命令,如下所示:
strace -e trace=file command/command
例如:
strace -e trace=file ls
strace 将输出有关命令执行的详细信息,包括调用的函数和打开的文件。使用文本编辑器(如 vi 或 nano)打开 strace 输出文件(默认情况下位于 /tmp/strace.out)。在输出文件中,找到包含 execve() 系统调用的行。此行将显示命令及其源码所在的可执行文件。使用 file 命令查看可执行文件的类型,如下所示:
file executable/executable
例如:
file /bin/ls
这将显示可执行文件的信息,包括其类型(如 ELF 文件)。
其他方法:
除了 strace 之外,还可以使用以下方法查看命令的源码:
nm:此命令列出可执行文件中的符号(函数和变量)。objdump:此命令以反汇编形式显示可执行文件的内容。
这些方法需要更高级别的tring源码技术知识,但可以提供有关命令实现更详细的信息。
如何查看linux命令源代码
用linux一段时间了,有时候想看看ls、cat、more等命令的源代码,在下载的内核源码中用cscope没能找到,在网上搜索了一下,将方 法总结如下:以搜索ls命令源码为例,先搜索命令所在包,命令如下:
lpj@lpj-linux:~$ which ls /bin/ls用命令搜索该软件所在包,代码如下:
lpj@lpj-linux:~$ dpkg -S /bin/ls coreutils: /bin/ls从上一步中可以知道ls命令的实现在包coreutils中,用apt安装(说安装有些歧义,主要是区分apt-get -d)该包的源代码然后解压,代码如下:
sudo apt-get source coreutils cd /usr/src/coreutils-XXX #XXX表示版本号 sudo tar zxvf coreutils-XXX.tar.gz 或者只下载源码,然后手动打补丁再解压,代码如下:
sudo apt-get -d source coreutils cd /usr/src tar zxvf coreutils-XXX.tar.gz gzip -d coreutils-XXX.diff.gz #这一步会生成coreutils-XXX.diff文件 patch -p0 < coreutils-XXX.diff cd coreutils-XXX tar zxvf coreutils-XXX.tar.gzOK,这几步执行完后,就可以进入/usr/src/coreutils-XXX/coreutils-XXX/src中查看各命令对应的源代码了
剖析Linux内核源码解读之《实现fork研究(一)》
Linux内核源码解析:深入探讨fork函数的实现机制(一)
首先,我们关注的焦点是fork函数,它是Linux系统创建新进程的核心手段。本文将深入剖析从用户空间应用程序调用glibc库,直至内核层面的具体过程。这里假设硬件平台为ARM,使用Linux内核3..3和glibc库2.版本。这些版本的库和内核代码可以从ftp.gnu.org获取。
在glibc层面,针对不同CPU架构,进入内核的vab 源码步骤有所不同。当glibc准备调用kernel时,它会将参数放入寄存器,通过软中断(SWI) 0x0指令进入保护模式,最终转至系统调用表。在arm平台上,系统调用表的结构如下:
系统调用表中的CALL(sys_clone)宏被展开后,会将sys_clone函数的地址放入pc寄存器,这个函数实际由SYSCALL_DEFINEx定义。在do_fork函数中,关键步骤包括了对父进程和子进程的跟踪,以及对子进程进行初始化,包括内存分配和vfork处理等。
总的来说,调用流程是这样的:应用程序通过软中断触发内核处理,通过系统调用表选择并执行sys_clone,然后调用do_fork函数进行具体的进程创建操作。do_fork后续会涉及到copy_process函数,这个函数是理解fork核心逻辑的重要入口,包含了丰富的内核知识。在后续的内容中,我将深入剖析copy_process函数的工作原理。
linux源码解读(三十二):dpdk原理概述(一)
Linux源码解析(三十二):深入理解DPDK原理(一)
几十年来,随着技术的发展,传统操作系统和网络架构在处理某些业务需求时已显得力不从心。为降低修改底层操作系统的高昂成本,人们开始在应用层寻求解决方案,如协程和QUIC等。然而,momentdiary源码一个主要问题在于基于内核的网络数据IO,其繁琐的处理流程引发了效率低下和性能损耗。
传统网络开发中,数据收发依赖于内核的receive和send函数,经过一系列步骤:网卡接收数据、硬件中断通知、数据复制到内存、内核线程处理、协议栈层层剥开,最终传递给应用层。这种长链式处理方式带来了一系列问题,如上下文切换和协议栈开销。
为打破这种限制,Linux引入了UIO(用户空间接口设备)机制,允许用户空间直接控制网卡,跳过内核协议栈,从而大大简化了数据处理流程。UIO设备提供文件接口,通过mmap映射内存,允许用户直接操作设备数据,实现绕过内核控制网络I/O的设想。
DPDK(Data Plane Development Kit)正是利用了UIO的优点,如Huge Page大页技术减少TLB miss,内存池优化内存管理,Ring无锁环设计提高并发性能,以及PMD poll-mode驱动避免中断带来的开销。它采用轮询而非中断处理模式,实现零拷贝、低系统调用、减少上下文切换等优势。
DPDK还注重内存分配和CPU亲和性,通过NUMA内存优化减少跨节点访问,提高性能,并利用CPU亲和性避免缓存失效,提升执行效率。学习DPDK,可以深入理解高性能网络编程和虚拟化领域的技术,更多资源可通过相关学习群获取。
深入了解DPDK原理,可以从一系列资源开始,如腾讯云博客、CSDN博客、B站视频和LWN文章,以及Chowdera的DPDK示例和腾讯云的DPDK内存池讲解。
源:cnblogs.com/thesevenths...
linux文件操作内核源码解密
在Linux编程中,文件操作是基础且重要的部分。开发者们常会遇到忘记关闭文件、子进程对父进程文件操作、以及socket连接问题等疑问。其实,一切在Linux内核看来,都归结为文件操作。让我们一起探索内核如何处理这些文件操作,理解背后的结构和机制。 首先,文件在内核中有三个关键结构体:struct files_struct(打开文件信息表)、struct fdtable(文件描述符表)和struct file(打开文件对象)。这三个结构体共同构成了应用程序与内核交互的桥梁。当进程打开文件时,内核会通过这三个结构体进行管理。 当一个进程打开多个文件时,struct files_struct存储了所有打开的文件信息,而文件描述符fd通过它指向struct file。单进程使用dup或fork子进程时,文件对象会被共享,多个描述符指向同一对象,这时的读写状态是共享的,但关闭一个描述符不会影响其他。 对于多线程环境,线程之间的文件操作更为微妙。线程通过CLONE_FILES标志共享父进程的文件信息,这可能导致线程间操作的同步问题。在关闭文件时,如果引用计数大于1,不会立即释放,直到所有引用消失。 当我们调用open时,do_sys_open系统调用负责获取描述符、创建对象并连接两者。写文件时,内核会跟踪文件位置并调用write方法进行实际操作,驱动程序负责具体实现。关闭文件则有主动和被动两种情况,主动关闭可能因引用计数不为零而无法立即释放,而进程退出时会自动关闭所有打开的文件。 理解Linux文件操作的内核机制,对于编写健壮的程序至关重要。编程不仅是代码的堆砌,更是对系统底层原理的掌握。希望这个深入解析能帮助你解答疑惑,后续的系列文章和视频也欢迎查阅,共同提升我们的技术素养。附件:
宏伟精讲系列文章
宏伟技术:我为什么要在知乎写博客?
宏伟技术:内核探秘·线程与文件操作
宏伟技术:理解双堆栈原理
宏伟技术:Linux popen和system函数详解
Linux内核源码解析---mount挂载原理
Linux磁盘挂载命令"mount -t xxx /dev/sdb1 abc/def/"的底层实现原理非常值得深入了解。从内核初始化的vfsmount开始说起。
内核初始化过程中,主要关注"main.c"中的vfs_caches_init函数,这个方法与mount紧密相连。接着,跟进"mnt_init"和"namespace.c",关键在于最后的三个函数,它们控制了挂载过程的实现。
在"mount.c"中,sysfs_fs_type结构中包含了获取超级块的函数指针,而"init_rootfs"则注册了rootfs类型的文件系统。挂载系统调用sys_mount中的dev_name, dir_name和type参数,分别对应设备名称、挂载目录和文件系统类型。
"do_mount"方法通过path_lookup收集挂载目录信息,创建nameidata结构,然后调用do_add_mount进行实际挂载。这个过程涉及do_kern_mount和graft_tree,尽管具体实现较为复杂,但核心在于创建vfsmount并将其与namespace关联。
在"graft_tree"中的判断逻辑中,vfsmount被创建并与其父mount和挂载目录的dentry建立关系。在"attach_mnt"方法中,新vfsmount与现有结构关联,设置挂载点和父vfsmount,最终形成挂载的概念,即为设备分配vfsmount,并将其与指定目录和vfsmount结合,成为vfs系统的一部分。
解析LinuxSS源码探索一探究竟linuxss源码
被誉为“全球最复杂开源项目”的Linux SS(Secure Socket)是一款轻量级的网络代理工具,它在Linux系统上非常受欢迎,也成为了大多数网络应用的首选。Linux SS的源码的代码量相当庞大,也备受广大开发者的关注,潜心钻研Linux SS源码对于网络研究者和黑客们来说是非常有必要的。
我们以Linux 3. 内核的SS源码为例来分析,Linux SS的源码目录位于linux/net/ipv4/netfilter/目录下,在该目录下包含了Linux SS的主要代码,我们可以先查看其中的主要头文件,比如说:
include/linux/netfilter/ipset/ip_set.h
include/linux/netfilter_ipv4/ip_tables.h
include/linux/netfilter/x_tables.h
这三个头文件是Linux SS系统的核心结构之一。
接下来,我们还要解析两个核心函数:iptables_init函数和iptables_register_table函数,这两个函数的主要作用是初始化网络过滤框架和注册网络过滤表。iptables_init函数主要用于初始化网络过滤框架,主要完成如下功能:
1. 调用xtables_init函数,初始化Xtables模型;
2. 调用ip_tables_init函数,初始化IPTables模型;
3. 调用nftables_init函数,初始化Nftables模型;
4. 调用ipset_init函数,初始化IPset模型。
而iptables_register_table函数主要用于注册网络过滤表,主要完成如下功能:
1. 根据提供的参数检查表的有效性;
2. 创建一个新的数据结构xt_table;
3. 将该表注册到ipt_tables数据结构中;
4. 将表名及对应的表结构存放到xt_tableshash数据结构中;
5. 更新表的索引号。
到这里,我们就大致可以了解Linux SS的源码,但Learning Linux SS源码只是静态分析,细节的分析还需要真正的运行环境,观察每个函数的实际执行,而真正运行起来的Linux SS,是与系统内核非常紧密结合的,比如:
1. 调用内核函数IPv6_build_route_tables_sockopt,构建SS的路由表;
2. 调用内核内存管理系统,比如kmalloc、vmalloc等,分配SS所需的内存;
3. 初始化Linux SS的配置参数;
4. 调用内核模块管理机制,加载Linux SS相关的内核模块;
5. 调用内核功能接口,比如netfilter, nf_conntrack, nf_hook等,通过它们来执行对应的网络功能。
通过上述深入了解Linux SS源码,我们可以迅速把握Linux SS的构架和实现,也能熟悉Linux SS的具体运行流程。Linux SS的深层原理揭示出它未来的发展趋势,我们也可以根据Linux SS的现有架构改善Linux的网络安全机制,进一步开发出与Linux SS和系统内核更加融合的高级网络功能。

2025-01-19 23:43
2025-01-19 23:40
2025-01-19 23:37
2025-01-19 23:23
2025-01-19 22:51
2025-01-19 22:45
2025-01-19 22:31
2025-01-19 22:15