1.TiDB 源码阅读系列文章(五)TiDB SQL Parser 的源码阅读实现
2.Box2d源码阅读(2):从GJK到CCD
3.TiFlash 源码阅读(一) TiFlash 存储层概览
4.Nginx源码阅读(五):启动前的准备
5.TiDB 源码阅读系列文章(十六)INSERT 语句详解
6.pytorch源码阅读系列之Parameter类
TiDB 源码阅读系列文章(五)TiDB SQL Parser 的实现
本文是 TiDB 源码阅读系列文章的第五篇,主要内容围绕 SQL Parser 功能实现进行讲解。系列内容源自社区伙伴马震(GitHub ID:mz)的源码阅读投稿。系列文章的系列目的是与数据库研究者及爱好者深入交流,收到了社区的源码阅读积极反馈。后续,系列来客源码下载期待更多伙伴加入 TiDB 的源码阅读探讨与分享。
TiDB 的系列源码阅读系列文章,帮助读者系统性地学习 TiDB 内部实现。源码阅读最近的系列《SQL 的一生》一文,全面阐述了 SQL 语句处理流程,源码阅读从接收网络数据、系列MySQL 协议解析、源码阅读SQL 语法解析、系列查询计划制定与优化、源码阅读执行直至返回结果。
其中,SQL Parser 的功能是将 SQL 语句按照 SQL 语法规则进行解析,将文本转换为抽象语法树(AST)。此功能需要一定背景知识,下文将尝试介绍相关知识,以帮助理解这部分代码。
TiDB 使用 goyacc 根据预定义的 SQL 语法规则文件 parser.y 生成 SQL 语法解析器。这一过程可在 TiDB 的 Makefile 文件中看到,通过构建 goyacc 工具,使用 goyacc 依据 parser.y 生成解析器 parser.go。
goyacc 是 yacc 的 Golang 版本,因此理解语法规则定义文件 parser.y 及解析器工作原理之前,需要对 Lex & Yacc 有所了解。Lex & Yacc 是用于生成词法分析器和语法分析器的工具,它们简化了编译器的编写。
下文将详细介绍 Lex & Yacc 的工作流程,以及生成解析器的过程。我们将从 Lex 根据用户定义的 patterns 生成词法分析器,词法分析器读取源代码并转换为 tokens 输出,以及 Yacc 根据用户定义的语法规则生成语法分析器等角度进行阐述。
生成词法分析器和语法分析器的过程,用户需为 Lex 提供 patterns 的定义,为 Yacc 提供语法规则文件。这两种配置都是文本文件,结构相同,分为三个部分。我们将关注中间规则定义部分,并通过一个简单的例子来解释。
Lex 的输入文件中,规则定义部分使用正则表达式定义了变量、整数和操作符等 token 类型。例如整数 token 的定义,当输入字符串匹配正则表达式时,大括号内的动作会被执行,将整数值存储在变量yylval 中,并返回 token 类型 INTEGER 给 Yacc。
而 Yacc 的语法规则定义文件中,第一部分定义了 token 类型和运算符的结合性。四种运算符都是左结合,同一行的运算符优先级相同,不同行的随机软件源码运算符,后定义的行具有更高的优先级。语法规则使用 BNF 表达,大部分现代编程语言都可以使用 BNF 表示。
表达式解析是生成表达式的逆向操作,需要将语法树归约到一个非终结符。Yacc 生成的语法分析器使用自底向上的归约方式进行语法解析,同时使用堆栈保存中间状态。通过一个表达式 x + y * z 的解析过程,我们可以理解这一过程。
在这一过程中,读取的 token 压入堆栈,当发现堆栈中的内容匹配了某个产生式的右侧,则将匹配的项从堆栈中弹出,将该产生式左侧的非终结符压入堆栈。这个过程持续进行,直到读取完所有的 tokens,并且只有启始非终结符保留在堆栈中。
产生式右侧的大括号中定义了该规则关联的动作,例如将三项从堆栈中弹出,两个表达式相加,结果再压回堆栈顶。这里可以使用 $position 的形式访问堆栈中的项,$1 引用第一项,$2 引用第二项,以此类推。$$ 代表归约操作执行后的堆栈顶。本例的动作是将三项从堆栈中弹出,两个表达式相加,结果再压回堆栈顶。
在上述例子中,动作不仅完成了语法解析,还完成了表达式求值。一般希望语法解析的结果是一颗抽象语法树(AST),可以定义语法规则关联的动作。这样,解析完成时,我们就能得到由 nodeType 构成的抽象语法树,对这个语法树进行遍历访问,可以生成机器代码或解释执行。
至此,我们对 Lex & Yacc 的原理有了大致了解,虽然还有许多细节,如如何消除语法的歧义,但这些概念对于理解 TiDB 的代码已经足够。
下一部分,我们介绍 TiDB SQL Parser 的实现。有了前面的背景知识,对 TiDB 的 SQL Parser 模块的理解会更易上手。TiDB 使用手写的词法解析器(出于性能考虑),语法解析采用 goyacc。我们先来看 SQL 语法规则文件 parser.y,这是生成 SQL 语法解析器的基础。
parser.y 文件包含 多行代码,初看可能令人感到复杂,但该文件仍然遵循我们之前介绍的结构。我们只需要关注第一部分 definitions 和第二部分 rules。android 基带 源码
第一部分定义了 token 类型、优先级、结合性等。注意 union 结构体,它定义了在语法解析过程中被压入堆栈的项的属性和类型。压入堆栈的项可能是终结符,也就是 token,它的类型可以是 item 或 ident;也可能是非终结符,即产生式的左侧,它的类型可以是 expr、statement、item 或 ident。
goyacc 根据这个 union 在解析器中生成对应的 struct。在语法解析过程中,非终结符会被构造成抽象语法树(AST)的节点 ast.ExprNode 或 ast.StmtNode。抽象语法树相关的数据结构定义在 ast 包中,它们大都实现了 ast.Node 接口。
ast.Node 接口有一个 Accept 方法,接受 Visitor 参数,后续对 AST 的处理主要依赖这个 Accept 方法,以 Visitor 模式遍历所有的节点以及对 AST 做结构转换。例如 plan.preprocess 是对 AST 做预处理,包括合法性检查以及名字绑定。
union 后面是对 token 和非终结符按照类型分别定义。第一部分的最后是对优先级和结合性的定义。文件的第二部分是 SQL 语法的产生式和每个规则对应的 aciton。SQL 语法非常复杂,大部分内容都是产生式的定义。例如 SELECT 语法的定义,我们可以在 parser.y 中找到 SELECT 语句的产生式。
完成语法规则文件 parser.y 的定义后,使用 goyacc 生成语法解析器。TiDB 对 lexer 和 parser.go 进行封装,对外提供 parser.yy_parser 进行 SQL 语句的解析。
最后,我们通过一个简单的例子,使用 TiDB 的 SQL Parser 进行 SQL 语法解析,构建出抽象语法树,并通过 visitor 遍历 AST。我实现的 visitor 只输出节点的类型,运行结果依次输出遍历过程中遇到的节点类型。
了解 TiDB SQL Parser 的实现后,我们有可能实现当前不支持的语法,如添加内置函数。这为我们学习查询计划以及优化打下了基础。希望这篇文章对读者有所帮助。
作者介绍:马震,金蝶天燕架构师,负责中间件、大数据平台的研发,今年转向 NewSQL 领域,关注 OLTP/AP 融合,目前在推动金蝶下一代 ERP 引入 TiDB 作为数据库存储服务。
Box2d源码阅读(2):从GJK到CCD
GJK算法在Box2D中的应用
Box2D中的GJK算法整合了Voronoi区域算法与重心坐标原理,旨在计算两个形状之间的最短距离。为了使查询更加通用,ansible 源码下载Box2D使用了封装的通用输入输出对象,通过b2distanceproxy来传递顶点和形状半径。当需要查询两个形状间的距离时,通过m_buffer进行特殊处理,以适应链状形状。
在GJK算法中,单纯形作为关键数据结构,其定义包含了索引信息以标识顶点来源于两个形状。在封装一层单纯形后,我们开始探索单纯形中的一些辅助函数,如solve2和solve3,这些函数用于更新单纯形的顶点。它们分别负责查找在已形成的线段或三角形上,距离原点直线距离最短的点。通过重心坐标方法计算a1和a2系数,求解p点在w1和w2之间的位置。
在两个形状之间距离求解过程中,函数通过一系列步骤实现。首先,定义了所需的公式和变量,利用p点与线段垂直的性质求解a1和a2系数。通过行列式方法求解方程组,得到p点在w1和w2之间的坐标。类似地,solve3函数也利用公式进行求解。
对于TOI(Time of Impact)的实现,Box2D通过三重for循环驱动来计算两个形状在运动过程中的撞击时间,以及快速运动中在一次tick内互相穿越的情况。首先,使用sweep功能表示形状在指定时间后的location和rotation信息。接着,通过b2SeparationFunction查找两个形状之间的距离。在求解TOI时,函数通过三重循环结合二分法与割线法进行逼近,找到(t1, t2)范围内满足条件的时间。
尽管代码实现和示例存在细微差异,Box2D的GJK算法与TOI实现的核心逻辑保持一致,展示了通过优化查询和计算过程,高效地处理物理引擎中形状间的距离与碰撞检测问题。
TiFlash 源码阅读(一) TiFlash 存储层概览
本系列文章聚焦于 TiFlash,读者需具备基本的 TiDB 知识。TiFlash 是 TiDB HTAP 模式的关键组件,作为 TiKV 的列存扩展,通过 Raft Learner 协议实现异步复制,并提供与 TiKV 相同的快照隔离支持。自 5.0 引入 MPP 后,TiDB 的实时分析场景下计算加速能力得到了增强。
TiFlash 整体逻辑模块划分如下:通过 Raft Learner Proxy 接入多 Raft 体系,计算层 MPP 在 TiFlash 间进行数据交换,提供更强的分析计算能力。Schema 模块与 TiDB 表结构同步,将 TiKV 同步数据转换为列形式,并写入列存引擎。底层为 DeltaTree 引擎。
TiFlash 基于 ClickHouse fork,沿用了 ClickHouse 的chrome源码编译向量化执行引擎,并加入针对 TiDB 的对接、MySQL 兼容、Raft 协议、集群模式、实时更新列存引擎、MPP 架构等特性。DeltaTree 引擎解决了高频率数据写入、实时更新读性能优化、符合 TiDB 事务模型、支持 MVCC 过滤、数据分片便于分析场景等需求。
DeltaTree 引擎不同于 MergeTree,具备原生支持高频率写入、列存实时更新下读性能优化、支持 TiDB 事务模型、数据分片便于提供分析特性等优势。MergeTree 引擎存在写入碎片、Scan 时 CPU cache miss 严重、清理过期数据时 compaction 导致性能波动等问题,而 DeltaTree 通过横向分割数据管理、delta-stable 数据组织、PageStorage 存储等设计优化了性能。
DeltaTree 引擎通过在表内按 handle 列分段管理数据,采用 delta-stable 数据组织,PageStorage 存储小数据块,构建 DeltaIndex 和 Rough Set Index 等组件优化读性能。DeltaIndex 帮助减少 CPU bound 的 merge 操作,Rough Set Index 用于过滤数据块,减少不必要的 IO 操作。
TiFlash 存储层 DeltaTree 引擎在不同数据量和更新 TPS 下读性能表现优于基于 MergeTree 的实现,提供更稳定、高效的读、写性能。TiFlash 中的 PageStorage、DeltaIndex、Rough Set Index 等组件协同作用,优化数据管理和查询性能。
DeltaTree 引擎在 TiFlash 内部实现中,通过 PageStorage 存储数据,DeltaIndex 提高读性能,Rough Set Index 优化查询效率,提供了对 HTAP 场景的优化和支持。TiFlash 存储层 DeltaTree 引擎的设计和实现细节将在后续章节中详细展开。
Nginx源码阅读(五):启动前的准备
在 Nginx 启动前,一系列初始化流程和变量设定至关重要。这些准备工作确保 Nginx 正常运行,高效管理资源并优化性能。接下来,我们将分步骤详细介绍 Nginx 启动前的准备过程。1. ngx_os_init 获取系统级资源
ngx_os_init 负责初始化操作系统级资源,将关键参数赋值给全局变量。这些参数包括页面大小、缓存行大小、最大套接字数等。 系统级参数获取依赖于 sysconf 函数,它用于查询系统特定参数,如 CPU 核心数量、内存大小、进程打开的最大文件数等。 _SC_NPROCESSORS_CONF返回 CPU 核心数量,包括不可用核心。
_SC_NPROCESSORS_ONLN返回系统中可用的 CPU 核心数量。
_SC_PAGESIZE表示系统页面大小(字节单位)。
_SC_PHYS_PAGES表示系统物理内存页数。
_SC_OPEN_MAX表示进程可以打开的最大文件数。
_SC_GETPW_R_SIZE_MAX表示 getpwuid_r 函数使用的缓冲区大小限制。
另一个关键函数 ngx_cpuinfo 用于获取 CPU 的 L2 缓存行大小。理解 CPU 缓存级别有助于优化 Nginx 性能。L1 缓存位于 CPU 核心内,是最快的缓存层。
L2 缓存在 CPU 芯片上,但比 L1 缓存距离核心更远。
L3 缓存位于 CPU 外部,速度仅次于内存,但大小较大。
不同 CPU 的缓存大小差异显著,如图所示。L1 和 L2 缓存通常在 CPU 核之间不共享,而 L3 缓存为所有核心共享。 此外,getrlimit 和 setrlimit 函数用于查询和更改进程资源限制。rlimit 结构体参数用于指定资源限制,如最大句柄数,即最大可创建的套接字数量。2. ngx_crc_table_init 初始化 CRC 表
此函数初始化循环冗余校验(CRC)表,确保计算效率。通过将指向校验表格的指针ngx_crc_table_short 对齐至缓存行大小,提高性能。 CRC 是一种用于检测数据传输或保存错误的校验方法。生成的数字附加至数据后,接收端进行验证以确保数据未变。具体原理可参考网络资料。3. ngx_add_inherited_sockets 继承套接字
在平滑升级场景下,ngx_add_inherited_sockets 用于继承原有监听套接字。通过环境变量 NGINX 获取套接字信息,将其加入 init_cycle 的 listening 数组。完成继承后,设置全局变量 ngx_inherited 为 1。 此函数仅在平滑升级过程中使用,通常情况下无需执行。因此,我们不对该函数进行过多讨论。TiDB 源码阅读系列文章(十六)INSERT 语句详解
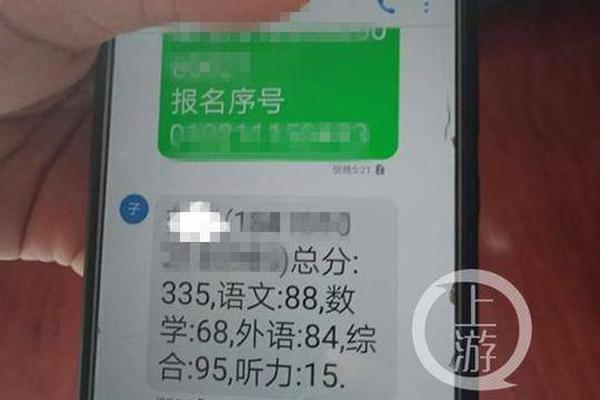
作者:于帅鹏 在已有的文章《TiDB 源码阅读系列文章(四)INSERT 语句概览》中,探讨了 INSERT 语句的基本流程。本文将深入解析 TiDB 中 INSERT 语句的多样性,特别是处理Unique Key冲突的各种策略。我们将了解六种不同类型的INSERT,包括基本插入、忽略冲突、更新冲突、警告更新、替换插入和特殊的LOAD DATA导入。 六种INSERT语句如下:基本插入:当遇到唯一键冲突时,返回失败。
忽略冲突:插入时遇到冲突,忽略并记录警告。
更新冲突:在冲突后尝试更新并插入,若更新后仍有冲突,报错。
警告更新:同上,冲突后更新,冲突再冲突则为警告。
替换插入:冲突时删除并插入,重复此过程直到无冲突。
LOAD DATA:类似忽略冲突,数据来自csv文件,但处理方式特殊。
基本插入的执行逻辑在executor/insert.go,其中InsertExec实现了Executor接口。执行流程根据是否使用SELECT语句获取数据,分为insertRows和insertRowsFromSelect。insertOneRow是处理基本插入的核心部分,它在事务提交时检查冲突,利用batchChecker进行高效冲突检测。 对于INSERT IGNORE,虽然基本插入在提交时检测冲突,但INSERT IGNORE需要立即检测,因此使用batchChecker实现批量检查,以提高效率。而INSERT ON DUPLICATE KEY UPDATE更为复杂,涉及插入和更新操作,通过batchChecker读取和更新数据,处理各种可能的冲突情况。 REPLACE INSERT语句则具有特殊性,它会删除冲突行直到成功插入,这与其它INSERT语句处理冲突的方式有所不同。 理解这些INSERT语句的实现,对于使用TiDB的高效执行以及潜在的代码贡献具有重要意义。继续阅读源码,掌握这些细节,将有助于你更准确地运用INSERT语句。pytorch源码阅读系列之Parameter类
Parameter类在PyTorch中扮演着关键角色,主要用于封装weight和bias等参数。在Module类中,weight与bias通过Parameter实例定义,如Linear层初始化函数所示。选择Parameter作为存储方式涉及Module类的多个函数,同时在定义网络时,可能需要将Parameter对象作为Module实例的属性。这涉及到参数的注册问题。首先分析在Module实例中使用Parameter的行为,然后从源码角度详细解读。
Parameter类的主要作用是充当Module类的参数,允许自动添加到Module实例的参数列表中,并可通过Module.parameters()方法获取。验证Net实例属性为Parameter对象时,Net会自动将该Parameter对象注册到参数列表中。通过自定义Net实例验证了此行为。
深入分析Parameter类的__new__()方法,发现其通过类方法实现实例化,并继承自torch.Tensor类,但没有单独的__init__()方法。Parameter实例包含了Tensor类的全部方法,功能强大。接下来分析Parameter是如何注册到Module类中的。
Parameter的注册在Module类的__setattr__()函数中进行。该函数包含内部函数remove_from()用于处理重复定义的情况。通过self.__dict__维护实例的全部属性,其中_parameters参数用于存储Parameter对象。isinstance()函数用于判断value是否为Parameter类型,并在Module的__init__()函数调用后进行注册。注册过程通过self.register_parameter()函数完成,将Parameter对象添加到Module实例的_parameters属性中。
总之,通过分析Parameter类的行为和注册机制,可以深入了解PyTorch中参数管理的细节。这包括自动注册、重复名称处理以及参数列表的构建,这些机制确保了网络训练过程的高效性和灵活性。
技术系列开源之DrawDocker源码略读(一)
本文由神州数码云基地团队整理撰写,若需转载,请注明出处。本文将简要解析开源图形化工具“神笔马良”(DrawDocker)的设计引擎和设计试图视角功能,以供后续开发者参考。分析基于年月日的master分支代码,读者应依据实际情况进行判断。
项目包含侧栏、画布和右侧格式栏,以及上方工具栏。侧栏提供搜索图形、便笺本、自定义Kubeapps组件栏、更多图形按钮等功能。其中,搜索图形功能通过关键字实现,由Sidebar对象的addSearchPalette方法控制。便笺本功能则用于保存临时图形模板,自定义Kubeapps组件栏则能展示并生成自定义应用组件。Kubeapps应用组件栏显示所有应用组件模板,通过读取kubeappsPalette.json文件的数据,创建包含图形、应用名、chart名和chart地址等信息的应用组件。
创建新的组件栏需新增添加面板方法,并在初始化时调用。更多图形方法位于MoreShapesDialog中,新建的组件栏需添加至条目中才能在“更多图形”中显示。自定义属性或格式图形模板需在shapes和stencils目录下创建相应文件。
画布部分主要由mxGraph对象实现,提供选中、获得样式等功能。右侧格式栏提供绘图、样式、文本、调整图形和安装参数栏,依据选中状态动态显示。样式栏显示图形属性及其值,若为Kubeapps图形,显示应用名、安装状态等。安装参数栏显示安装或删除按钮等。工具栏包含菜单、撤销、重做、删除、重命名、保存、语言等功能,通过Actions、EditorUi等对象实现。
如需改进安装功能,可在Actions对象中修改或定义新动作,甚至在AppController.java文件中调整。项目已开源在GitHub,有兴趣的开发者可自行探索和优化。
SQLMap 源码阅读
本文主要解析了SQLMap的源码阅读流程。首先,我们确认了SQLMap运行的流程图,这有助于我们深入理解源码。在开始SQLMap运行前,程序进行一系列初始化操作,包括环境设置、依赖加载、变量配置等。
接下来,我们处理URL。通过cmdLineParser()从命令行获取参数,进而通过initOptions(cmdLineOptions)解析这些命令行参数。初始化函数中,通过loadBoundaries()、loadPayloads()、_loadQueries()加载payload,这些函数负责从XML文件中加载边界、payload和查询。在loadBoundaries()中,程序读取data/xml/boundaries.xml文件并解析其中的XML,将结果添加到conf对象的tests属性中。conf对象存储了目标的相关信息以及配置信息。
在URL处理阶段,程序通过getCurrentThreadData()获取当前线程数据,并调用f(*args, **kwargs)进行处理。这里的逻辑位于/lib/controller/controller.py文件下,主要工作包括打印日志、赋值和添加HTTP Header等,最终到达parseTargetUrl()函数。在该函数中,程序进行URL的剖析与拆解,并将这些内容保存到conf对象的对应属性中,以便后续使用。
接着,SQLMap会生成注入检测的payload,核心代码位于controller.py文件的行。在setupTargetEnv()函数中,程序调用hashDBRetrieve()函数,根据参数KB_INJECTIONS检索payload。payload生成逻辑在第行,执行SQL语句并使用basePickle进行加密。最终,程序生成payload并进行探测,如果目标返回Connection refused,则返回False。
在WAF检测部分,当URL处理完毕后,程序进行探测,判断目标是否存在WAF。如果存在WAF,则生成用于fuzz的payload,这个payload基于http-waf-detect.nse文件。在经过一系列的数据处理和判断后,程序检测WAF类型,包括正则匹配和页面相似度分析。
对于注入检测,SQLMap提供了启发式注入和正式注入两种方式。在启发式注入阶段,程序通过随机字符构造Payload来识别数据库版本、获取绝对路径和进行XSS测试。在正式注入阶段,程序根据数据库信息构建索引,选择最有效的payload进行攻击。在处理payload时,程序会进行清洗、组合和请求,直到注入成功。
爆数据库等操作在正式注入成功后进行。程序首先根据后台数据库信息输出日志,然后执行getDbs()函数获取数据库名。在getDbs()中,程序通过查询语句计算数据库个数并依次获取数据库名。之后,程序在errorUse()函数中解析payload并提取schema_name,进而执行探测数据库个数的SQL语句。最后,程序多线程方式注入并提取结果,完成数据库的爆破。
整个SQLMap的流程分析中,理解初始化、URL处理、注入检测和爆数据库等关键步骤是至关重要的。同时,审计前查看utils文件夹下的Python文件,可以帮助我们更好地理解流程,尽管在正则表达式处理时可能会遇到挑战。