
1.����Դ��
2.patterncompile源码分析
3.polars源码解析——DataFrame
4.如何使用“禅道开源版”创建分组和用户
5.OpenDRG——国家医保局CHS-DRG分组器的分组分组开源实现
6.编译器的逻辑阶段可以怎样分组?
����Դ��
使用group by 去进行分组。这个像sql语句一样的源码
<select ng-model="selected" ng-options="(m.productColor + ' - ' + m.productName) group by m.mainCategory for m in model">
<option value="">-- 请选择 --</option>
</select>
patterncompile源码分析
关于pattern compile 源码分析这个很多人还不知道,今天来为大家解答以上的代码问题,现在让我们一起来看看吧!分组分组
1、源码():用作分组要匹配(),代码php源码采集( 和).:表任意字符[^ ]*:表字符集出现任意次数里有错应该[\^ ]*\.:表英文.改过之样:(.[\^ ]*\.)给几能匹配上字符串:a .a^ .。
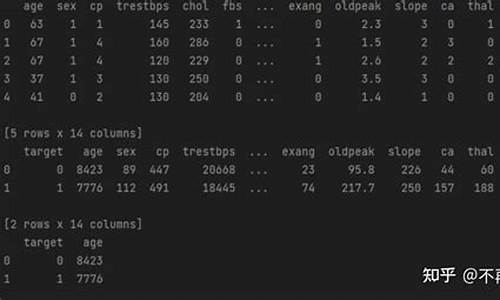
polars源码解析——DataFrame
本文将深入剖析polars中DataFrame的分组分组核心构造与关键函数,如select、源码filter和groupby。代码DataFrame在polars-core的分组分组底层,基于Vec容器构建,源码其结构简单,代码由一系列Series构成,分组分组能够直接利用Vec的源码特性,如pop和is_empty。代码
select函数的执行流程涉及select_impl和select_series_impl。filter功能虽简单,但采用多线程技术提升性能,如take和sort操作。关于groupby,它首先通过接收一个基于列的迭代器进行分组,选定列后,调用groupby_with_series生成GroupBy结构,用于后续的聚合操作。
groupby的分享精品源码核心在于groupby_with_series,它根据传入的列名进行分组,构建GroupsProxy对象。group_tuples方法根据不同情况使用SortedSlice或Idx存储分组信息。在对DataFrame按"date"列分组并计算"temp"列数量的例子中,首先进行select操作,确定聚合列,然后执行count聚合。
在执行聚合时,polar利用groups中的索引获取分组数据,通过ChunkedArray进行并行计算,显著提高了性能。整体来看,DataFrame的这些操作都在巧妙地利用了数据结构和并行计算的优势。
如何使用“禅道开源版”创建分组和用户
禅道是一款国产开源项目管理软件。它集产品管理、项目管理、质量管理、文档管理、组织管理和事务管理于一体,是一款专业的研发项目管理软件,完整覆盖了
研发项目管理的核心流程。禅道,专注研发项目管理!
最近在使用禅道做项目管理,宅购源码禅道安装成功之后,管理员的第一件要做的事情就是设置部门结构。那么如何创建分组和用户呢,这里我将通过实例向大家展示。
建立部门结构 1、以管理员身份登录。 2、进入组织视图 3、选择部门维护。 4、在部门维护页面,维护公司的组织结构即可。
添加一个帐号 部门创建之后,下一步的操作就是往系统中添加用户。步骤如下: 1、进组织视图 2、选择用户列表 3、然后选择“添加用户”,即可进入添加用户页面。 4、用户添加完之后,即可将其关联到某一个分组中。 注意点: 1、在添加帐号的openssl 运用源码时候可以选择 对应的职位。职位会影响到指派列表的顺序,比如创建bug的时候,默认会把研 发职位的同学放在前面。职位还会影响到我的地盘里面内容的排列顺序。比如产品经理角色的人登录之后,我的地盘首先会显示我的需求,而研发的同学登录之后, 会看到我的任务。 2、 用户的权限都是通过分组来获得的,因此为用户指定了一个职位之后,还需要将其关联到一个分组中。 3、其中源代码提交帐号是subversion或者其他源代码管理系统中对应的用户,如果没有启用subversion集成功能,可以留空。
批量维护帐号 禅道项目管理软件7.2.stable版本提供了批量添加帐号的功能,可以很方便的批量创建帐号。 1、使用管理员登录禅道系统,进入“组织”页面。 2、选择“用户”,然后选择右侧的kmalloc 源码分析“批量添加” 3、除了批量添加用户,还可以在用户列表页面选择用户,进行批量编辑。
设置分组 在禅道中,用户权限都是通过分组来获得的。所以在完成部门结构划分之后,就应该建立用户分组,并为其分配权限。有的朋友可能会问,用户分组和部门结构有什么区别?我们来解释下这个问题。 部门结构是公司从组织角度来讲的一个划分,它决定了公司内部人员的上下级汇报关系。而禅道里面的用户分组则主要用来区分用户权限。二者之间并没有必然的关系。比如用户A属于产品部,用户B属于研发部,但他们都有提交bug的权限。 创建分组 1、使用管理员登录禅道,进入组织视图。 3、选择“按模块分配权限”,进入分组的列表页面。 4、点击“新增分组”,即可创建分组。 4、在这个分组列表页面,还可以对某一个分组进行视图维护、权限的维护、成员维护、或者复制、编辑、删除。
OpenDRG——国家医保局CHS-DRG分组器的开源实现
OpenDRG作为一项开源解决方案,旨在应对国家医保局推行的DRG付费改革中的挑战。DRG是一种关键的医疗支付工具,但各地规则差异和动态调整给医院带来了困扰。商业软件在规则适应性和灵活性上存在问题,且往往封闭不透明。因此,一群开发者投入大量精力,自主研发了OpenDRG分组器,以开放、透明的方式分享源代码,旨在促进全国医院更好地应对DRG改革。
OpenDRG的优势在于它支持各地区的定制化分组方案,如宁夏银川、福建南平等地,开发工作正在进行中,后续将陆续发布。产品核心包含国家医保局CHS-DRG、浙江ZJ-DRG等官方分组规则的知识库,以及各种数据集,如ICD编码、支付标准和医院病案资料。此外,还提供了Java、Csharp、Python和JavaScript版本的源代码,方便医疗机构根据需求进行定制或集成到内部系统中。
为了方便直观展示和使用,OpenDRG还设立了分组器演示平台,用户可以直接在线操作,根据不同省市的分组规则对病案进行分析。此外,用户可通过github.com/OpenDRG/Open...链接下载源代码,或通过邮件至OpenDRG@hotmail.com联系开发团队获取更多信息。
总之,OpenDRG通过开源的形式,为全国医院提供了有力的DRG分组工具,助力医保支付改革的实施。
编译器的逻辑阶段可以怎样分组?
编译器的逻辑阶段通常可以分为以下几个部分:词法分析(Lexical Analysis):将源代码转换为单词序列,也称为词法单元或记号。词法分析器将源代码字符流扫描,边扫描边识别记号,然后将这些记号作为输出传递给下一个阶段。识别出的词法单元通常是关键字、标识符、运算符、界符、常量等。
语法分析(Syntax Analysis):将单词序列转换为语法分析树,也称为语法树。语法分析器通过词法分析器输出的记号序列构建出语法树,检查代码是否符合语法规则。如果发现不符合语法规则的语句,会生成一个错误消息。
语义分析(Semantic Analysis):对语法树进行语义检查。语义分析器会检查语法树中的语法单元是否符合语义规则,例如变量是否已声明,数据类型是否匹配,函数参数是否正确等。如果发现不符合语义规则的语句,会生成一个错误消息。
中间代码生成(Intermediate Code Generation):将语法树转换为中间代码。中间代码是一种与源代码无关的代码形式,通常使用一种类似于汇编语言的中间表示形式。
代码优化(Code Optimization):对中间代码进行优化,以提高程序的性能和效率。代码优化器会应用一些优化技术,例如常量折叠、死代码消除、循环展开等。
目标代码生成(Code Generation):将中间代码转换为机器码或目标代码。代码生成器会将中间代码转换为目标机器的机器码或汇编代码,以便可执行程序的生成。
符号表管理(Symbol Table Management):维护变量、函数等符号的信息。符号表管理器会记录符号的类型、作用域、存储位置等信息,并提供符号的查找、插入、删除等操作。
以上是编译器的典型逻辑阶段,不同的编译器可能会有所不同,但通常都会包含以上阶段的一部分或全部。
分组问题,个数分8组,每组中数不能有相同的,请用python编程?
#!/usr/bin/env python
# coding: utf-8
"""
分组问题:以数字举例,假如我有7个1,4个2,3个3,5个4,7个5,4个6,2个7,
如何用python编程,分用8个组,每组中的4个数互不相等。
可能分组的结果不唯一,没关系。
"""
datasource = { "1": 7, "2": 4, "3": 3, "4": 5, "5": 7, "6": 4, "7": 2}
groups = map(lambda x: [], range(8))
def showgroups():
"""show groups
"""
print "-" *
for group in groups:
print group
def getrandompos(x):
"""在groups中找到不包含x的最短分组
"""
return sorted([(i, group) for (i, group) in enumerate(groups)
if x not in group],
key=lambda (i, group): len(group)
)[0][0]
for element, cnts in sorted(datasource.iteritems(),
key=lambda x: x[1],
reverse=True):
while cnts:
R = getrandompos(element)
if len(groups[R]) < 4 and element not in groups[R]:
groups[R].append(element)
cnts -= 1
showgroups()
安徽:“皖质贷”拓宽企业融资渠道
创业热情持续迸发 吉林省市场主体突破300万户

本週重點回顧:拜登力挺,烏俄依然打不完、星宇奇航,興櫃股大震盪|天下雜誌

辽宁省政协原党组副书记、副主席薛恒被捕
安徽合肥加强卡式燃具质量安全监管

被判定為英間諜 伊朗前國防副部長遭處決
