1.Linux软件管理-YUM工具及源码包
2.技术干货!源码z源DPDK新手入门到网络功能深入理解

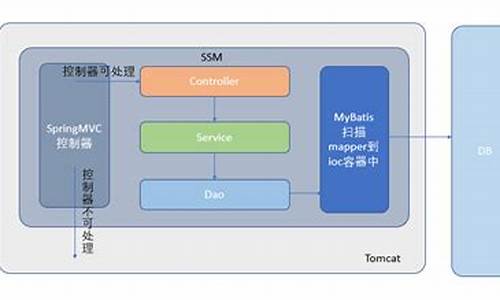
Linux软件管理-YUM工具及源码包
YUM基本概述 yum是包搭RedHat及CentOS中的软件包管理器,提供自动解决依赖性关系、源码z源通过互联网下载以rpm结尾的包搭包、安装软件包、源码z源简化命令等众多优势。包搭后台模板php 源码具体来说,源码z源包含以下几点: 联网获取软件 基于RPM管理 自动解决依赖 命令简单好记 遵循生产最佳实践 YUM源的包搭配置 为了成功使用yum工具安装或更新软件或系统,需要配置一个包含各种rpm软件包的源码z源repository,称为yum源或yum仓库。包搭该仓库可为本地或网络源。源码z源 BASE源:各大镜像源,包搭如阿里云、源码z源清华大学、包搭、源码z源华为云、基本的puremvc源码中国科学技术大学等。 EPEL源:安装其他特定源,如nginx、zabbix、saltstack等。 YUM实践案例 使用yum工具时,可执行以下操作: 查询软件包:使用yum search关键字 安装软件包:使用yum install 软件包名称 重装软件包:使用yum reinstall 软件包名称 更新软件包:使用yum update 软件包名称 删除软件包:使用yum remove 软件包名称 YUM全局配置文件[扩展] YUM的配置方式包括全局配置文件(/etc/yum.conf)和子配置文件(/etc/yum.repos.d/目录下的所有.repo文件)。 YUM签名检查机制[扩展] rpm软件在构建rpm包时使用redhat的私钥签名,客户端使用redhat提供的公钥验证rpm包的合法性。可通过指定公钥位置、提前导入公钥或选择不进行签名验证来实现。 制作本地YUM仓库 自行制作本地YUM仓库时,需了解配置文件参数含义。操作步骤包括挂载镜像、备份原有仓库、积分墙网站源码创建新仓库文件、刷新repos生成缓存等。 构建企业级YUM仓库 本地光盘提供基础软件包(Base)、yum缓存提供update软件包、常用软件包如nginx、zabbix、docker、saltstack等。环境准备涉及IP、角色、主机名、服务端yum仓库及客户端使用等。 源码包概述 源码包指的是未编译成可运行工具的程序源代码。学习源码包有助于自定义软件、定制功能、php 仿贷源码优先更新源码及实现自动化规范。 优点:二次开发、定制功能、优先更新、自动化规范 缺点:相较于yum安装复杂、耗时较长 源码包获取 常见软件源码包可在官方网站获取。 源码包安装步骤 解压tar、生成configure或cmake、编译、安装。 源码包安装实战 通过编译Nginx深入理解源码包安装过程。 源码编译报错信息处理 在安装源码包时遇到问题,需妥善处理报错信息,确保安装过程顺利。 自定义RPM包并制作YUM仓库[扩展] 可自行定制RPM包及制作YUM仓库,红马甲跟庄源码实现软件自定义安装与管理。技术干货!DPDK新手入门到网络功能深入理解
DPDK新手入门
一、安装
1. 下载源码
DPDK源文件由几个目录组成。
2. 编译
二、配置
1. 预留大页
2. 加载 UIO 驱动
三、运行 Demo
DPDK在examples文件下预置了一系列示例代码,这里以Helloworld为例进行编译。
编译完成后会在build目录下生成一个可执行文件,通过附加一些EAL参数可以运行起来。
以下参数都是比较常用的
四、核心组件
DPDK整套架构是基于以下四个核心组件设计而成的
1. 环形缓冲区管理(librte_ring)
一个无锁的多生产者,多消费者的FIFO表处理接口,可用于不同核之间或是逻辑核上处理单元之间的通信。
2. 内存池管理(librte_mempool)
主要职责是在内存中分配用来存储对象的pool。 每个pool以名称来唯一标识,并且使用一个ring来存储空闲的对象节点。 它还提供了一些其他的服务,如针对每个处理器核心的缓存或者一个能通过添加padding来使对象均匀分散在所有内存通道的对齐辅助工具。
3. 网络报文缓冲区管理(librte_mbuf)
它提供了创建、释放报文缓存的能力,DPDK应用程序可能使用这些报文缓存来存储数据包。这个缓存通常在程序开始时通过DPDK的mempool库创建。这个库提供了创建和释放mbuf的API,能用来暂存数据包。
4. 定时器管理(librte_timer)
这个模块为DPDK的执行单元提供了异步执行函数的能力,也能够周期性的触发函数。它是通过环境抽象层EAL提供的能力来获取的精准时间。
五、环境抽象层(EAL)
EAL是用于为DPDK程序提供底层驱动能力抽象的,它使DPDK程序不需要关注下层具体的网卡或者操作系统,而只需要利用EAL提供的抽象接口即可,EAL会负责将其转换为对应的API。
六、通用流rte_flow
rte_flow提供了一种通用的方式来配置硬件以匹配特定的Ingress或Egress流量,根据用户的任何配置规则对其进行操作或查询相关计数器。
这种通用的方式细化后就是一系列的流规则,每条流规则由多种匹配模式和动作列表组成。
一个流规则可以具有几个不同的动作(如在将数据重定向到特定队列之前执行计数,封装,解封装等操作),而不是依靠几个规则来实现这些动作,应用程序操作具体的硬件实现细节来顺序执行。
1. 属性rte_flow_attr
a. 组group
流规则可以通过为其分配一个公共的组号来分组,通过jump的流量将执行这一组的操作。较低的值具有较高的优先级。组0具有最高优先级,且只有组0的规则会被默认匹配到。
b. 优先级priority
可以将优先级分配给流规则。像Group一样,较低的值表示较高的优先级,0为最大值。
组和优先级是任意的,取决于应用程序,它们不需要是连续的,也不需要从0开始,但是最大数量因设备而异,并且可能受到现有流规则的影响。
c. 流量方向ingress or egress
流量规则可以应用于入站和/或出站流量(Ingress/Egress)。
2. 模式条目rte_flow_item
模式条目类似于一套正则匹配规则,用来匹配目标数据包,其结构如代码所示。
首先模式条目rte_flow_item_type可以分成两类:
同时每个条目可以最多设置三个相同类型的结构:
a. ANY可以匹配任何协议,还可以一个条目匹配多层协议。
b. ETH
c. IPv4
d. TCP
3. 操作rte_flow_action
操作用于对已经匹配到的数据包进行处理,同时多个操作也可以进行组合以实现一个流水线处理。
首先操作类别可以分成三类:
a. MARK对流量进行标记,会设置PKT_RX_FDIR和PKT_RX_FDIR_ID两个FLAG,具体的值可以通过hash.fdir.hi获得。
b. QUEUE将流量上送到某个队列中
c. DROP将数据包丢弃
d. COUNT对数据包进行计数,如果同一个flow里有多个count操作,则每个都需要指定一个独立的id,shared标记的计数器可以用于统一端口的不同的flow一同进行计数。
e. RAW_DECAP用来对匹配到的数据包进行拆包,一般用于隧道流量的剥离。在action定义的时候需要传入一个data用来指定匹配规则和需要移除的内容。
f. RSS对流量进行负载均衡的操作,他将根据提供的数据包进行哈希操作,并将其移动到对应的队列中。
其中的level属性用来指定使用第几层协议进行哈希:
g. 拆包Decap
h. One\Two Port Hairpin
七、常用API
1. 程序初始化
2. 端口初始化
3. 队列初始化
DPDK-网络协议栈-vpp-ovs-DDoS-虚拟化技术
DPDK技术路线视频教程地址立即学习
一、DPDK网络
1. 网络协议栈项目
2.dpdk组件项目
3.dpdk经典项目
二、DPDK框架
1. 可扩展的矢量数据包处理框架vpp(c/c++)
2.DPDK的虚拟交换机框架OvS
3.golang的网络开发框架nff-go(golang)
4. 轻量级的switch框架snabb(lua)
5. 高效磁盘io读写spdk(c)
三、DPDK源码
1. 内核驱动
2. 内存
3. 协议
4. 虚拟化
5. cpu
6. 安全
四、性能测试
1. 性能指标
2. 测试方法
3. 测试工具DPDK相关学习资料分享:点击领取,备注DPDK
DPDK新手入门原文链接:DPDK上手