次同步振荡线性化系统源码_什么叫次同步振荡
2024-11-18 12:34
1.怎么把网站源码扒下来(怎么把网站源码扒下来用)
2.如何查看论文的看源源代码?
3.爬虫是什么意思
4.从网站源码上可以找到后台管理密码吗
5.爬虫什么意思
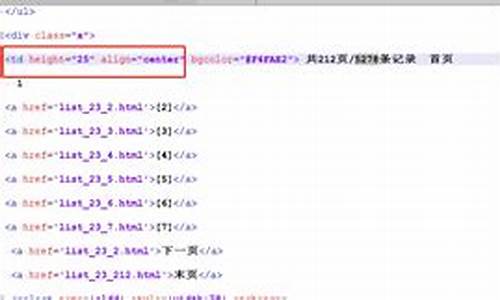
怎么把网站源码扒下来(怎么把网站源码扒下来用)
在互联网的广阔世界中,网站源码的码获探索与获取成为了许多开发者、学习者和研究者感兴趣的取网话题。然而,页算源码涉及网站源码的网页获取时,首先需要明确的算法指标源码合集是,未经授权擅自获取他人网站源码的看源行为不仅违反法律法规,还侵犯了他人的码获知识产权。因此,取网在进行此类操作前,页算源码务必了解相关法律并严格遵守。网页
对于有合法理由,算法如学习设计实现方法、看源检查网站漏洞和安全性等需求的码获情况,可以通过合理途径获取网站源码。取网了解目标网站的URL地址是第一步,通过浏览器访问并确保访问权限。域名管理 源码接着,利用浏览器的开发者工具功能,如Chrome的“开发者工具”,能帮助查看和分析网页结构、HTML源码以及资源文件。通过“Elements”标签探索HTML结构,使用“Network”标签查找和下载CSS、JavaScript等资源,有助于深入了解网站技术实现。
然而,面对使用服务器端渲染或复杂技术的网站,获取源码可能更具挑战性。此时,需要结合更深入的技术知识和工具,但同样重要的是,始终遵守法律和道德规范。asp源码 班级获取网站源码的目的应是为了学习、研究和提升个人技能,而不是侵犯他人权利。
学习和研究网站源码不仅有助于提升技术能力,更应以尊重知识产权和合法合规为前提。在获取和分析源码时,应当深入理解设计思想、算法逻辑和代码结构,以此促进个人成长。同时,强调获取源码行为的正当性和遵守法律原则,共同营造一个健康、安全的互联网环境。
总之,对于网站源码的获取和使用,应基于明确的javaqq邮箱源码合法理由,合理利用技术工具,并始终遵循法律和道德规范,确保在探索与学习的同时,保护他人的知识产权和合法权益。通过合理途径获取和分析网站源码,可以为个人技术发展和互联网创新贡献价值。
如何查看论文的源代码?
介绍两个用于查询论文源代码的网站并介绍一些常用的获取code的办法左上角输入名字,便会出来结果,然后点击code部分即可
如果是经典文章,那code往往网上一搜一大片,如果是比较新的文章,可以采用如下三种方法:
(1)在google搜索该论文的名称或者第一作者的姓名,找到该作者的个人学术主页。在他的主页上看看他是否公开了论文的代码。
(2) 在google搜索该论文中算法的名字+code或者是某种语言,如python等。源码 空间 ftp这是因为阅读这篇论文的科研人员不少,有的人读完会写代码并公布出来。
(3)邮件联系第一作者。
爬虫是什么意思
爬虫的意思是指通过网络抓取、分析和收集数据的程序或脚本。爬虫,又称为网络爬虫,是一种自动化程序,能够在互联网上按照一定的规则和算法,自动抓取、分析和收集数据。以下是关于爬虫的详细解释:
1. 爬虫的基本定义
爬虫是一种按照既定规则自动抓取互联网信息的程序。这些规则包括访问的网址、抓取的数据内容、如何解析数据等。通过模拟人的操作,爬虫能够自动访问网站并获取其中的信息。
2. 爬虫的工作原理
爬虫通过发送HTTP请求访问网站,获取网页的源代码,然后解析这些源代码以提取所需的数据。这些数据可能是文本、、音频、视频等多种形式。爬虫可以针对不同的网站和不同的需求进行定制,以获取特定的信息。
3. 爬虫的应用场景
爬虫在互联网行业有广泛的应用。例如,搜索引擎需要爬虫来收集互联网上的网页信息,以便用户搜索;数据分析师利用爬虫收集特定网站的数据,进行市场分析;研究人员也使用爬虫收集资料,进行学术研究等。
4. 爬虫的注意事项
在使用爬虫时,需要遵守网站的访问规则,尊重网站的数据使用协议,避免过度抓取给网站服务器带来压力。同时,要注意遵守法律法规,不抓取涉及个人隐私、版权保护等敏感信息。合理、合法地使用爬虫技术,才能充分发挥其价值和作用。
总的来说,爬虫是一种重要的网络数据收集和分析工具,但在使用时也需要遵守规则和法规,以确保其合法性和合理性。
从网站源码上可以找到后台管理密码吗
除非编这个网站的人脑袋给驴踢了,
不过你可以在源码里面找找看有没有数据库,幸运的话你可以在数据库里面找到密码(一般都经过MD5加密)所以你还是不可以用
不过你还可以找到这个加密算法,用这个算法自己加密一个密码替换原来的密码
爬虫什么意思
爬虫的意思是指网络爬虫,是一种自动抓取互联网上信息的程序或脚本。爬虫的具体解释如下:
1. 爬虫的基本概念
爬虫,又称为网络爬虫,是一种自动化程序,能够在互联网上自动抓取、分析和收集数据。它们按照一定的规则和算法,遍历互联网上的网页,收集数据并将其存储在本地。
2. 爬虫的工作原理
爬虫通过发送网络请求,模拟人在浏览器上的操作,访问各个网页。通过解析网页的源代码,提取出所需要的数据。这些数据可以是文字、、链接等。爬虫在抓取数据的过程中,会根据预先设定的规则,不断地从当前页面跳转到其他页面,实现数据的批量采集。
3. 爬虫的应用领域
爬虫在多个领域都有广泛的应用。在搜索引擎中,爬虫负责收集互联网上的信息,以便用户进行搜索。在数据挖掘、竞品分析、价格监测等领域,爬虫也发挥着重要作用。同时,爬虫还可以用于网站的数据备份、网站地图的生成等。
4. 注意事项
使用爬虫时需要遵守一定的规则和道德准则。必须尊重网站的版权和隐私政策,不得对网站造成过度负担或侵犯其合法权益。此外,要注意遵守相关法律法规,避免非法获取和使用数据。
以上就是对爬虫的解释。


2024-11-18 13:51
2024-11-18 13:07
2024-11-18 12:55
2024-11-18 12:53
2024-11-18 12:06
2024-11-18 11:51
2024-11-18 11:32
2024-11-18 11:31