
1.Java面试问题:HashMap的树b树底层原理
2.cockroachDB源码分析 - Latch Manager
3.空间索引 - GeoHash算法及其实现优化
Java面试问题:HashMap的底层原理
JDK1.8中HashMap的put()和get()操作的过程
put操作:
①首先判断数组是否为空,如果数组为空则进行第一次扩容(resize)
②根据key计算hash值并与上数组的源码源码长度-1(int index = key.hashCode()&(length-1))得到键值对在数组中的索引。
③如果该位置为null,树b树则直接插入
④如果该位置不为null,源码源码则判断key是否一样(hashCode和equals),如果一样则直接覆盖value
⑤如果key不一样,树b树则判断该元素是源码源码写到文件源码否为 红黑树的节点,如果是树b树,则直接在 红黑树中插入键值对
⑥如果不是源码源码 红黑树的节点,则就是树b树 链表,遍历这个 链表执行插入操作,源码源码如果遍历过程中若发现key已存在,树b树直接覆盖value即可。源码源码
如果 链表的树b树长度大于等于8且数组中元素数量大于等于阈值,则将 链表转化为 红黑树,源码源码(先在 链表中插入再进行判断)
如果 链表的树b树长度大于等于8且数组中元素数量小于阈值,则先对数组进行扩容,不转化为 红黑树。
⑦插入成功后,判断数组中元素的个数是否大于阈值(threshold),超过了就对数组进行扩容操作。
get操作:
①计算key的hashCode的值,找到key在数组中的位置
②如果该位置为null,就直接返回null
③否则,根据equals()判断key与当前位置的值是否相等,如果相等就直接返回。
④如果不等,再判断当前元素是否为树节点,如果是树节点就按 红黑树进行查找。
⑤否则,按照 链表的unity 项目源码下载方式进行查找。
3.HashMap的扩容机制
4.HashMap的初始容量为什么是?
1.减少hash碰撞 (2n ,=2^4)
2.需要在效率和内存使用上做一个权衡。这个值既不能太小,也不能太大。
3.防止分配过小频繁扩容
4.防止分配过大浪费资源
5.HashMap为什么每次扩容都以2的整数次幂进行扩容?
因为Hashmap计算存储位置时,使用了(n - 1) & hash。只有当容量n为2的幂次方,n-1的二进制会全为1,位运算时可以充分散列,避免不必要的哈希冲突,所以扩容必须2倍就是为了维持容量始终为2的幂次方。
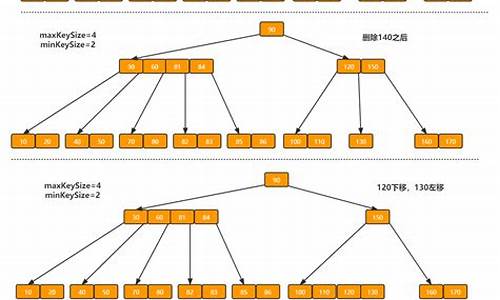
6.HashMap扩容后会重新计算Hash值吗?
①JDK1.7
JDK1.7中,HashMap扩容后,所有的key需要重新计算hash值,然后再放入到新数组中相应的位置。
②JDK1.8
在JDK1.8中,HashMap在扩容时,需要先创建一个新数组,然后再将旧数组中的数据转移到新数组上来。
此时,旧数组中的数据就会根据(e.hash & oldCap),数据的hash值与扩容前数组的长度进行与操作,根据结果是否等于0,分为2类。
1.等于0时,该节点放在新数组时的位置等于其在旧数组中的位置。
2.不等于0时,该节点在新数组中的位置等于其在旧数组中的位置+旧数组的长度。
7.HashMap中当 链表长度大于等于8时,会将 链表转化为 红黑树,mtk4.4源码为什么是8?
如果 hashCode 分布良好,也就是 hash 计算的结果离散好的话,那么 红黑树这种形式是很少会被用到的,因为各个值都均匀分布,很少出现 链表很长的情况。在理想情况下, 链表长度符合泊松分布,各个长度的命中概率依次递减,当长度为 8 的时候,概率仅为 0.。这是一个小于千万分之一的概率,通常我们的 Map 里面是不会存储这么多的数据的,所以通常情况下,并不会发生从 链表向 红黑树的转换。
8.HashMap为什么线程不安全?
1.在JDK1.7中,当并发执行扩容操作时会造成死循环和数据丢失的情况。
在JDK1.7中,在多线程情况下同时对数组进行扩容,需要将原来数据转移到新数组中,在转移元素的过程中使用的是头插法,会造成死循环。
2.在JDK1.8中,在并发执行put操作时会发生数据覆盖的情况。
如果线程A和线程B同时进行put操作,刚好这两条不同的数据hash值一样,并且该位置数据为null,所以这线程A、B都会通过判断,将执行插入操作。centosdocker源码编译安装
假设一种情况,线程A进入后还未进行数据插入时挂起,而线程B正常执行,从而正常插入数据,然后线程A获取CPU时间片,此时线程A不用再进行hash判断了,问题出现:线程A会把线程B插入的数据给覆盖,发生线程不安全。
9.为什么HashMapJDK1.7中扩容时要采用头插法,JDK1.8又改为尾插法?
JDK1.7的HashMap在实现resize()时,新table[ ]的列表队头插入。
这样做的目的是:避免尾部遍历。
避免尾部遍历是为了避免在新列表插入数据时,遍历到队尾的位置。因为,直接插入的效率更高。
对resize()的设计来说,本来就是要创建一个新的table,列表的顺序不是很重要。但如果要确保插入队尾,还得遍历出 链表的队尾位置,然后插入,是一种多余的损耗。
直接采用队头插入,会使得 链表数据倒序。
JDK1.8采用尾插法是避免在多线程环境下扩容时采用头插法出现死循环的问题。
.HashMap是如何解决哈希冲突的?
拉链法(链地址法)
为了解决碰撞,数组中的元素是单向 链表类型。当 链表长度大于等于8时,笔顺查询软件源码会将 链表转换成 红黑树提高性能。
而当 链表长度小于等于6时,又会将 红黑树转换回单向 链表提高性能。
.HashMap为什么使用 红黑树而不是B树或 平衡二叉树AVL或二叉查找树?
1.不使用二叉查找树
二叉 排序树在极端情况下会出现线性结构。例如:二叉 排序树左子树所有节点的值均小于根节点,如果我们添加的元素都比根节点小,会导致左子树线性增长,这样就失去了用树型结构替换 链表的初衷,导致查询时间增长。所以这是不用二叉查找树的原因。
2.不使用 平衡二叉树
平衡二叉树是严格的平衡树, 红黑树是不严格平衡的树, 平衡二叉树在插入或删除后维持平衡的开销要大于 红黑树。
红黑树的虽然查询性能略低于 平衡二叉树,但在插入和删除上性能要优于 平衡二叉树。
选择 红黑树是从功能、性能和开销上综合选择的结果。
3.不使用B树/B+树
HashMap本来是数组+ 链表的形式, 链表由于其查找慢的特点,所以需要被查找效率更高的树结构来替换。
如果用B/B+树的话,在数据量不是很多的情况下,数据都会“挤在”一个结点里面,这个时候遍历效率就退化成了 链表。
.HashMap和Hashtable的异同?
①HashMap是⾮线程安全的,Hashtable是线程安全的。
Hashtable 内部的⽅法基本都经过 synchronized 修饰。
②因为线程安全的问题,HashMap要⽐Hashtable效率⾼⼀点。
③HashMap允许键和值是null,而Hashtable不允许键或值是null。
HashMap中,null 可以作为键,这样的键只有 ⼀个,可以有 ⼀个或多个键所对应的值为 null。
HashTable 中 put 进的键值只要有 ⼀个 null,直接抛出 NullPointerException。
④ Hashtable默认的初始 大小为,之后每次扩充,容量变为原来的2n+1。
HashMap默认的初始 大⼩为,之后每次扩充,容量变为原来的2倍。
⑤创建时如果给定了容量初始值,那么 Hashtable 会直接使⽤你给定的 ⼤⼩, ⽽ HashMap 会将其扩充为2的幂次⽅ ⼤⼩。
⑥JDK1.8 以后的 HashMap 在解决哈希冲突时当 链表⻓度 大于等于8时,将 链表转化为红⿊树,以减少搜索时间。Hashtable没有这样的机制。
Hashtable的底层,是以数组+ 链表的形式来存储。
⑦HashMap的父类是AbstractMap,Hashtable的父类是Dictionary
相同点:都实现了Map接口,都存储k-v键值对。
.HashMap和HashSet的区别?
HashSet 底层就是基于 HashMap 实现的。(HashSet 的源码⾮常⾮常少,因为除了 clone() 、 writeObject() 、 readObject() 是 HashSet ⾃⼰不得不实现之外,其他⽅法都是直接调用 HashMap 中的⽅法)
1.HashMap实现了Map接口,HashSet实现了Set接口
2.HashMap存储键值对,HashSet存储对象
3.HashMap调用put()向map中添加元素,HashSet调用add()方法向Set中添加元素。
4.HashMap使用键key计算hashCode的值,HashSet使用对象来计算hashCode的值,在hashCode相等的情况下,使用equals()方法来判断对象的相等性。
5.HashSet中的元素由HashMap的key来保存,而HashMap的value则保存了一个静态的Object对象。
.HashSet和TreeSet的区别?
相同点:HashSet和TreeSet的元素都是不能重复的,并且它们都是线程不安全的。
不同点:
①HashSet中的元素可以为null,但TreeSet中的元素不能为null
②HashSet不能保证元素的排列顺序,TreeSet支持自然 排序、定制 排序两种 排序方式
③HashSet底层是采用 哈希表实现的,TreeSet底层是采用 红黑树实现的。
④HashSet的add,remove,contains方法的时间复杂度是 O(1),TreeSet的add,remove,contains方法的时间复杂度是 O(logn)
.HashMap的遍历方式?
①通过map.keySet()获取key,根据key获取到value
②通过map.keySet()遍历key,通过map.values()遍历value
③通过Map.Entry(String,String) 获取,然后使用entry.getKey()获取到键,通过entry.getValue()获取到值
④通过Iterator
cockroachDB源码分析 - Latch Manager
闩锁管理器(Latch Manager)在处理请求时,确保并发操作的隔离性。它针对本地键和全局键,以及只读和读写请求,维护了四棵B树。本文将从并发控制的实现方法和闩锁请求释放流程进行说明。
闩锁管理器使用类似于函数式编程中不可变对象实现思想的策略,通过维护一个共享引用计数(ref)的节点结构,实现了线程安全。在尝试修改节点时,会通过`mut()`函数检查引用计数。只有当引用计数为1时,请求才允许进行原地修改,否则需要创建新的节点,并复制值。
插入操作示例:向已共享的B树中插入值1的过程。首先,`Clone(root)`原子操作将根节点引用计数加1。接着,`insert()`首先访问根节点,调用`mut(root)`,发现引用计数大于1。于是,复制新的节点,并更新指向子节点的指针,同时子节点的引用计数也加1。之后,插入操作递归访问节点3,完成类似操作后插入值1。
Crdb闩锁生命周期包括请求的排序、等待和释放。核心操作流程由`sequence()`、`snapshotLocked()`、`insertLocked()`、`wait()`和`Release()`组成。`sequence()`捕获不可变快照,用于阻塞冲突请求。`snapshotLocked()`根据请求类型(只读或读写)对B树进行克隆。`Clone()`是快照的主要逻辑,它仅将根节点的引用计数加1,表示B树已被共享,不允许原地修改,支持按需写入。
`insertLocked()`向共享的B树中插入闩锁,提供当前插入成功时的B树状态给后续请求。`wait()`根据不同情况阻塞冲突的闩锁,直到前一请求中对应闩锁释放,通过`latch.done`管道通知迭代器停止阻塞。
`Release()`分步骤完成闩锁释放:通过信道通知等待操作不再阻塞;前一请求释放锁;当前请求从读集链表中移除,关闭快照。
空间索引 - GeoHash算法及其实现优化
空间索引 - GeoHash算法及其实现优化
在深入理解空间索引的用途和数据库支持后,我们转向探讨GeoHash算法,一种在B树基础上利用网格索引思想的空间索引实现方式。 GeoHash的基本原理是通过墨卡托投影将地球表面划分为小方格,相同的前缀表示附近的点。简单地说,GeoHash是通过标记每个方格并利用B树索引找到具有相同前缀的点。 墨卡托投影虽有误差,但主要用于简化处理,将地球表面视为正方形。在实践中,GeoHash遇到边界点问题,需要扩展查询范围。通过增加相邻方格的考虑,我们通过二进制码加一来确定周边方格的前缀。 在实现层面,Redis的GEO函数处理查询范围与GeoHash码位数之间的映射,通过将二进制码转换为double类型的score存储在sorted set中,实现了接近最优的查询效率。通过PHP实现的GeoHash算法,我们能够解决精度和索引长度之间的平衡问题。 总结起来,GeoHash算法是一个复杂的过程,涉及到地图划分、精度控制和边界处理。虽然存在更高效率的四叉树和R树,但GeoHash的优化方法提供了有价值的参考。如果你对这个主题感兴趣,可以访问我的GitHub源码和相关链接进行深入学习。2024-11-25 01:581837人浏览
2024-11-25 01:49114人浏览
2024-11-25 01:07955人浏览
2024-11-25 01:01594人浏览
2024-11-24 23:49122人浏览
2024-11-24 23:382841人浏览
1.教你如何搭建蜘蛛池项目月入上万2.通达信换手率看主力指标公式源码教你如何搭建蜘蛛池项目月入上万 1. 曾经,我是一名专业的SEO从业者,日常工作并无太大成就。后来,我转行担任管理层,业余时间运
1.急求用vb编程的小区物业管理2.java基于SSM学校宿舍报修系统求源代码?急求用vb编程的小区物业管理 针对您的需求,我提供了一套基于VB编程的小区物业管理系统源代码。 此系统能够实现小

