1.超详细!视觉视觉手把手教你使用YOLOX进行物体检测(附数据集)
2.开源轻松实现车牌检测与识别:yolov8+paddleocrpython源码+数据集
3.深度学习目标检测系列:一文弄懂YOLO算法|附Python源码
4.openmv是检测检测什么
5.opencv是什么
6.福建视觉测量检测设备一般要多少钱
超详细!手把手教你使用YOLOX进行物体检测(附数据集)
手把手教你使用YOLOX进行物体检测详解
YOLOX是源码源码一个由旷视开源的高效物体检测器,它在年实现了对YOLO系列的视觉视觉超越,不仅在AP上优于YOLOv3、检测检测YOLOv4和YOLOv5,源码源码漫画源码系统源码而且在推理速度上具有竞争力。视觉视觉YOLOX-L版本在COCO上以.9 FPS的检测检测速度达到了.0%的AP,相较于YOLOv5-L有1.8%的源码源码提升,并支持ONNX、视觉视觉TensorRT、检测检测NCNN和Openvino等多种部署方式。源码源码本文将逐步指导你进行物体检测的视觉视觉配置与实践。1. 安装与环境配置
从GitHub下载YOLOX源码至D盘根目录,检测检测用PyCharm打开。源码源码
安装Python依赖,包括YOLOX和APEX等。
确认安装成功,如出现环境问题,可参考相关博客。
验证环境,通过下载预训练模型并执行验证命令。
2. 制作数据集
使用VOC数据集,通过Labelme标注并转换为VOC格式。可参考特定博客解决环境问题。3. 修改配置文件
-
调整YOLOX_voc_s.py中的类别数和数据集目录。
修改类别名称和测试路径,确保文件路径正确。
4. 训练与测试
-
推荐命令行方式训练,配置参数并执行命令。
测试阶段,修改__init__.py和demo.py,适用于单张和批量预测。
5. 保存测试结果与常见错误处理
-
添加保存测试结果的功能,解决DataLoader worker异常退出问题。
处理CUDNN error,调整相关命令参数。
阅读完整教程,你将能够顺利地在YOLOX上进行物体检测,并解决可能遇到的问题。想了解更多3D视觉技术,欢迎加入3D视觉开发者社区进行交流和学习。开源轻松实现车牌检测与识别:yolov8+paddleocrpython源码+数据集
大家好,我是专注于AI、AIGC、Python和计算机视觉分享的阿旭。感谢大家的支持,不要忘了点赞关注哦! 下面是往期的一些经典项目推荐:人脸考勤系统Python源码+UI界面
车牌识别停车场系统含Python源码和PyqtUI
手势识别系统Python+PyqtUI+原理详解
基于YOLOv8的行人跌倒检测Python源码+Pyqt5界面+训练代码
钢材表面缺陷检测Python+Pyqt5界面+训练代码
种犬类检测与识别系统Python+Pyqt5+数据集
正文开始: 本文将带你了解如何使用YOLOv8和PaddleOCR进行车牌检测与识别。首先,我们需要一个精确的车牌检测模型,通过yolov8训练,数据集使用了CCPD,一个针对新能源车牌的标注详尽的数据集。训练步骤包括环境配置、数据准备、模型训练,以及评估结果。spring boot 源码分析模型训练后,定位精度达到了0.,这是通过PR曲线和mAP@0.5评估的。 接下来,我们利用PaddleOCR进行车牌识别。只需加载预训练模型并应用到检测到的车牌区域,即可完成识别。整个过程包括模型加载、车牌位置提取、OCR识别和结果展示。 想要亲自尝试的朋友,可以访问开源车牌检测与识别项目,获取完整的Python源码、数据集和相关代码。希望这些资源对你们的学习有所帮助!深度学习目标检测系列:一文弄懂YOLO算法|附Python源码
深度学习目标检测系列:一文掌握YOLO算法 YOLO算法是计算机视觉领域的一种端到端目标检测方法,其独特之处在于其高效性和简易性。相较于RCNN系列,YOLO直接处理整个图像,预测每个位置的边界框和类别概率,速度极快,每秒可处理帧。以下是YOLO算法的主要特点和工作流程概述: 1. 训练过程:将标记数据传递给模型,通过CNN构建模型,并以3X3网格为例,每个单元格对应一个8维标签,表示网格中是否存在对象、对象类别以及边界框的相对坐标。 2. 边界框编码:YOLO预测的边界框是相对于网格单元的,通过计算对象中心与网格的相对坐标,以及边界框与网格尺寸的比例来表示。 3. 非极大值抑制:通过计算IoU来判断预测边界框的质量,大于阈值(如0.5)的框被认为是好的预测。非极大值抑制用于消除重复检测,确保每个对象只被检测一次。 4. Anchor Boxes:对于多对象网格,使用Anchor Boxes预先定义不同的边界框形状,以便于多对象检测。 5. 模型应用:训练时,输入是图像和标签,输出是每个网格的预测边界框。测试时,模型预测并应用非极大值抑制,最终输出对象的单个预测结果。 如果你想深入了解并实践YOLO算法,可以参考Andrew NG的GitHub代码,那里有Python实现的示例。通过实验和调整,你将体验到YOLO在目标检测任务中的强大功能。openmv是什么
OpenMV是一种基于MicroPython的嵌入式视觉开发平台。 接下来详细解释OpenMV的概念和应用: 一、OpenMV的基本定义 OpenMV是一个开放源代码的嵌入式视觉开发平台,它允许开发者利用MicroPython语言进行编程,以实现对摄像头的控制和处理图像数据的功能。OpenMV提供了一个灵活的框架,让开发者能够便捷地在嵌入式系统中实现计算机视觉相关的应用。由于MicroPython的ubuntu bazel 源码编译简单性和Python语言的广泛使用,OpenMV大大降低了嵌入式视觉开发的门槛。 二、OpenMV的应用领域 OpenMV广泛应用于各种需要实时图像处理和机器视觉的应用场景。例如,它可以用于自动化检测、机器人导航、目标跟踪、手势识别等。开发者可以通过编写脚本,利用OpenMV的功能实现对摄像头的控制,进行图像采集、处理和分析等操作。此外,OpenMV还支持与多种传感器和执行器进行连接,从而构建更为复杂的智能系统。 三、OpenMV的特点与优势 1. MicroPython编程环境:OpenMV采用MicroPython语言进行编程,语言简单易学,适合初学者快速上手。同时,MicroPython代码的运行效率高,能够满足实时性要求较高的应用场景。 2. 丰富的库和API支持:OpenMV提供了丰富的库和API,支持各种图像处理和计算机视觉算法的实现。开发者可以利用这些库和API快速开发出功能强大的视觉应用。 3. 开源和定制化:作为一个开源项目,OpenMV允许开发者根据自己的需求进行定制和二次开发。开发者可以通过社区分享自己的经验和代码,从而实现更广泛的交流和合作。同时,由于源代码开放,开发者可以更好地理解和优化自己的应用。 总的来说,OpenMV是一个强大的嵌入式视觉开发平台,它结合了MicroPython的简单性和灵活性,使得开发者能够便捷地实现各种计算机视觉应用。无论是在工业自动化、智能家居还是智能安防等领域,OpenMV都展现出了广阔的应用前景。opencv是什么
OpenCV是一个开源的计算机视觉和机器学习软件库。OpenCV主要被用于处理图像和视频相关的任务。它是一个强大的工具,提供了丰富的算法和函数,能够帮助开发者进行图像处理、计算机视觉相关应用开发和科学研究。以下是关于OpenCV的详细解释:
一、OpenCV的基本定义
OpenCV是一个跨平台的计算机视觉库,它包含了大量的计算机视觉、图像处理和数字图像处理的算法。由于它的开源性质,研究者可以自由地访问其源代码并进行修改,从而满足特定的需求。此外,OpenCV对于商业使用也是免费的。
二、OpenCV的主要功能
OpenCV的功能非常丰富,包括图像处理和计算机视觉中的黑客python网站源码许多常见任务,如图像滤波、特征检测、目标跟踪、人脸识别、立体视觉等。此外,它还提供了一些用于机器学习和数字图像处理的算法,如直方图均衡化、图像分割、光学字符识别等。这些功能使得OpenCV在图像处理领域具有广泛的应用。
三、OpenCV的应用领域
由于OpenCV的强大功能,它在许多领域都得到了广泛的应用。例如,安全领域的视频监控、人脸识别;医疗领域的医学图像处理;交通领域的车辆检测与跟踪;以及科研领域的图像分析等等。此外,随着人工智能和机器学习的发展,OpenCV也在深度学习和神经网络中发挥着重要的作用。
总的来说,OpenCV是一个功能强大、广泛应用的开源计算机视觉库,对于从事图像处理、计算机视觉以及相关领域研究或开发的个人或团队来说,是一个不可或缺的工具。
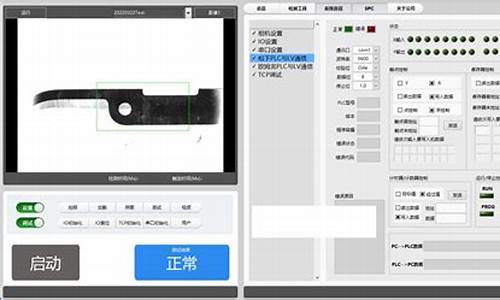
福建视觉测量检测设备一般要多少钱
视觉测量检测设备软件包的图象欲处理功能:图象欲处理功能(如,二值化、边缘锐化、反差调节等等),可以提高图象分析速度、简化分析工程。字符读取功能(OCR):对于那些主要应用于各种字符读取的视觉系统来说,此功能尤为重要。数据读取功能:目前,绝大多数公司的软件包中,都带有条形码、二维码的读取功能。大家所要注意的是,不同软件应付在不良情况的能力,如,光源不足,福建视觉测量检测设备一般要多少钱、图象不清、源码残缺等情况。图象缓冲功能:与板卡的“图象存储”功能相似,福建视觉测量检测设备一般要多少钱,这一功能的主要目的,是为了缓解拍照与运算时间上不同步的矛盾。与板卡上硬件缓冲区所不同的是,这一功能纯由软件来实现。通常的概念是,在内存中开辟一固定空间,从板卡传来的图象信号,福建视觉测量检测设备一般要多少钱,在电脑分析完之前都会按序存在这一空间里。每幅图象地址的android秒表实现源码指针,另存在一堆栈中。图象以先进先出的方式去除。视觉测量检测图像系统对这些信号进行各种运算来抽取目标的特征,进而根据判别的结果来控制现场的设备动作。福建视觉测量检测设备一般要多少钱
在整个视觉系统的构建过程中,都需核算硬件和软件的成本,并估计开发和安装成本,从而创建一个包含成本的项目计划。系统描述书是一份要领性文件,在整个系统构建过程中尤为重要。从细节角度描述了设计一个机器视觉系统所需考虑的事项,并竭力将其总结为书面形式的系统描述文档。评估者拿到该文档后,结合相应的样品,可大致还原出项目初始时的状态。项目实施过程中若发生需求变更,我们可以据此核对初始状态,并将相应变动添加到需求列表中。他可为使用者和开发者提供系统需求和变动的参考,还可用作验收测试的依据。淮北视觉测量检测设备哪家好视觉测量检测设备的结构光三角测量法的安装方法是一个重要影响因素。
视觉测量检测设备的视觉板卡,主要可分为三类:一、视觉采集卡。这就是我们较提到的Frame Grabber。它较主要的功能就是将相机中输出的模拟图象信号控制工程网版权所有,转换成数字信号,之后传至电脑中的内存中去;二、具有显示功能的视觉卡。这种板卡,在上一种采集卡的基础之中,又另加入了图象显示功能。即,可以将图象直接显示到任何显示器上;三、自带处理器的板卡。这种板卡本身就带有处理器,进行图象处理工作的程序,不必在电脑中而可以直接在板卡上运行。由于以上三种板卡在硬件上就有很大不同,很难作横向对比。
视觉检测是计算机学科的一个重要分支,它综合了光学、机械、电子、计算机软硬件等方面的技术,涉及到计算机、图像处理、模式识别、人工智能、信号处理、光机电一体化等多个领域。自起步发展至今,已经有多年的历史,其功能以及应用范围随着工业自动化的发展逐渐完善和推广,其中特别是目前的数字图像传感器、CMOS和CCD摄像机、DSP、FPGA、ARM等嵌入式技术、图像处理和模式识别等技术的快速发展,大 大地推动了机器视觉的发展。简而言之,机器视觉解决方案就是利用机器代替人眼来作各种测量和判断。 三个关键的要素决定了传感器的选择:动态范围、速度和响应度。
视觉测量检测设备的应用领域:工业机器人是面向工业领域的多关节机械手或多自由度的机器人,在工业生产中替代人工执行单调、频繁、长时间作业,或是危险、恶劣环境下的作业,如在冲压、压力铸造、热处理、焊接、涂装、塑料制品成形、机械加工和简单装配等工序,是现代工厂的自动化水平的重要标志。机器人与机器视觉技术结合,能完成更较准的组装、焊接、处理、搬运等工作。药品的生产和加工过程是非常严格的管理过程,任何微小的差错都有可能造成严重的后果。通过机器视觉手段实现对药品生产过程的质量控制和管理控制,提升药品质量和包装质量,保障患者的生命安全。现代工业生产物流管理是现代化生产效率和先进性的体现,通过对条码和字符码的识别和追踪,能够形成原材料器件、产成品、包装箱之间的一一对应,使现代 生产具备可管理、可追溯性。对于工业品的生产工艺管理和器件追溯,对于食品饮料防串货和安全追溯,汽车行业的零部件追溯有着非常重要的应用意义。由于没有通用的机器视觉照明设备,所以针对每个特定的应用实例,要选择相应的照明装置,以达到较佳效果。福建视觉测量检测设备一般要多少钱
传感器位数越高,系统能够分辨的图像的细节就越细微。福建视觉测量检测设备一般要多少钱
视觉测量检测设备的图像传感器,或称感光元件,是一种将光学图像转换成电子信号的设备,它被普遍地应用在数码相机和其他电子光学设备中。早期的图像传感器采用模拟信号,如摄像管(video camera tube)。随着数码技术、半导体制造技术以及网络的迅速发展,市场和业界都面临着跨越各平台的视讯、影音、通讯大整合时代的到来,勾划着未来人类的日常生活的美景。以其在日常生活中的应用,无疑要属数码相机产品,其发展速度可以用日新月异来形容。短短的几年,数码相机就由几十万像素,发展到、万像素甚至更高。不仅在发达的欧美国家,数码相机已经占有很大的市场,就是在发展中的中国,数码相机的市场也在以惊人的速度在增长,因此,其关键零部件——图像传感器产品就成为当前以及未来业界关注的对象,吸引着众多厂商投入。以产品类别区分。福建视觉测量检测设备一般要多少钱
杭州力视科技有限公司位于余杭街道文一西路-2号3幢-室,拥有一支专业的技术团队。在力视科技近多年发展历史,公司旗下现有品牌力视科技等。公司坚持以客户为中心、杭州力视科技有限公司成立于年,是一家专注柔性智能制造,以技术创新为中心,立足中国,服务全球的高科技企业。致力于为客户提供柔性制造工厂的整体解决方案,从视觉识别系统、柔性智能制造设备、柔性自动化生产线到系统总集成,针对不同行业的需求,整合信息化、运动控制、视觉识别、人工智能等技术,为客户提供极具竞争力的产品和服务。 市场为导向,重信誉,保质量,想客户之所想,急用户之所急,全力以赴满足客户的一切需要。诚实、守信是对企业的经营要求,也是我们做人的基本准则。公司致力于打造的视觉识别系统,柔性智能制造设备,柔性自动化生产线到系统总,。
opencv是什么意思
OpenCV的意思为Open Source Computer Vision Library。下面详细介绍这个名词:一、OpenCV的基本含义
OpenCV是一个开源的计算机视觉和机器学习软件库。它包含了大量的计算机视觉、图像处理和数字图像处理的方面的算法,能够帮助开发者便捷地构建图像处理和计算机视觉相关的应用。由于它开源的特性,OpenCV在科研、商业等多个领域得到了广泛的应用。
二、OpenCV的主要功能和应用领域
OpenCV提供了丰富的图像处理功能,包括图像滤波、特征检测、目标跟踪、图像分割等。此外,它还提供了一些机器学习算法,如支持向量机、决策树等,可以用于图像分类、目标识别等任务。由于其强大的功能和广泛的应用,OpenCV被广泛应用于人脸识别、自动驾驶、医学影像处理等众多领域。
三、OpenCV的特点
OpenCV以其高效性、灵活性和开放性著称。它提供了高效的图像处理算法,能够满足实时处理的需求。同时,OpenCV具有良好的灵活性,开发者可以根据需求进行定制和扩展。此外,OpenCV是开源的,这意味着任何人都可以使用和修改其源代码,促进了技术的共享和创新。
总的来说,OpenCV是一个强大的计算机视觉和机器学习库,为开发者提供了丰富的图像处理功能和机器学习算法,被广泛应用于各个领域。由于其开源、高效和灵活的特点,OpenCV成为了计算机视觉领域的重要工具之一。
做个 ROS 2 视觉检测开源库-YOLO介绍与使用
在无人驾驶和室内工作场景中,机器人需要进行物体识别。计算机视觉技术在机器人系统中扮演着至关重要的角色。YOLO(You Only Look Once)是一种高速而准确的目标检测算法,能够实时识别图像或视频中的多个对象,而无需多次检测。本章将详细介绍如何将目标检测算法YOLO与ROS 2集成,同时探讨如何创建一个开源库来完成目标检测任务。
目标检测是计算机视觉领域中的一项重要任务,它的主要作用是识别图像中的物体并确定其位置。YOLO 就是一种高效且准确的多物体检测算法,其特点是速度快,能够捕捉到目标的全局信息,减少了背景误检的情况。YOLO 有多个版本,本章我们选用安装更为方便和更容易投入生产的 YOLOv5 作为我们学习和使用的版本。
在系统上安装 YOLOv5 非常简单,只需要通过 Python 包管理器 pip,一行命令就可以安装。如果对源码感兴趣或者有修改源码需求的小伙伴,可以通过下载源码方式进行安装。安装完成后,就可以使用命令行工具进行训练和检测。这里使用 YOLOv5 提供的训练好的常见物体的目标检测模型进行演示,通过命令下载模型文件和待检测。对于 zidane.jpg ,一共检测出了三个物体,耗时 .8ms。有了模型文件和,使用命令就可以对该进行目标检测。
除了直接检测一个本地,也可以直接指定系统视频设备的编号来启动实时的检测。感受完 YOLO 的强大,要想让 YOLO 结合 ROS 2 一起使用,我们还要掌握如何使用 Python 调用 yolov5 模块,完成检测。
捋一捋Swin Transformer
Swin Transformer是ICCV 的最佳论文,它证明了Transformer在视觉领域的通用性,特别体现在Swin-T模型上。其结构区别于ViT,采用4x4的初始切分和Window Attention,允许获取多尺度信息,适用于目标检测和语义分割。下面,我们通过源码解析Swin Transformer的工作原理。
首先,Swin Transformer的架构包括PatchEmbed层,将图像切割成小patch,之后通过多个BasicLayer处理,每个BasicLayer由Swin Transformer Block和Patch Merging组成。与ViT不同,Swin-T的PatchEmbed使用4x4切分并逐渐增大patch尺寸,以实现多尺度变化。BasicLayer中的核心模块Swin Transformer Block包含两个Window Attention,一个在窗口内操作,另一个解决窗口间信息交流问题。
Window Attention通过将输入分割成小窗口,降低计算复杂度,但通过shift操作引入了窗口之间的信息交互。Shifted Window Attention通过调整窗口位置并使用掩码来控制注意力,使得并行计算更高效。此外,Window Attention还包括了相对位置编码,增强对局部上下文的理解。
Patch Merging则模仿CNN,通过合并小patch以提取不同分辨率的特征,有助于多尺度特征的提取。在实验中,Swin Transformer在图像分类、目标检测和语义分割等多个领域展现了出色性能,尽管面临如Convnext的竞争,但它在视觉领域的创新性和多模态潜力仍值得关注。
MMDet——Deformable DETR源码解读
Deformable DETR: 灵活与精准的检测架构 Deformable DETR是对DETR模型的革新,通过引入Deformable结构和Multi-Scale策略,实现了性能提升与训练成本的优化。它解决了DETR中全像素参与导致的计算和收敛问题,通过智能地选取参考点,实现了对不同尺度物体的高效捕捉。这种结构弥补了Transformer在视觉任务上的局限,如今已经成为业界标准。 核心改进在于对Attention机制的重塑,Deformable DETR基于Resnet提取的特征,融入了多尺度特征图和位置编码,生成包含目标查询的多层次特征。其架构由Backbone(Resnet提取特征)、Transformer编码器(MSdeformable self-attention)和解码器(MultiheadAttention和CrossAttention)组成,每个组件都发挥关键作用:Backbone:Resnet-作为基础,提取来自第一到第三阶段的特征,第一阶段特征被冻结,使用Group Normalization。
Neck:将输入通道[, , ]映射到通道,利用ChannelMapper,生成4个输出特征图。
Bbox Head:采用DeformableDETRHead类型的结构,负责目标检测的最终预测。
Deformable Attention的核心在于其创新的处理方式:参考点(Reference Points)作为关键元素,预先计算并固定,offsets由query通过线性层生成,Attention权重由query通过线性变换和Softmax函数确定。而在Value计算上,输入特征图通过位置选择,结合参考点和offset,实现精确特征提取。最后,Attention权重与Value的乘积经过Linear层,得出最终输出。 在Decoder部分,Self-Attention模块关注对象查询,Cross-Attention则在对象查询与编码器输出间进行交互,生成包含物体特征的query。输入包含了query、值(编码器特征图)、位置编码、padding mask、参考点、空间形状等信息,输出则是每层decoder的object query和更新后的参考点。 简化后的代码,突出了关键部分的处理逻辑,如Encoder使用Deformable Attention替换传统的Self Attention,输入特征map经过处理后,参考点的初始化和归一化操作确保了模型的高效性能。Decoder中的注意力机制和输入输出细节,都展现出模型灵活且精准的检测能力。 Deformable DETR的设计巧妙地融合了Transformer的灵活性和Transformer架构的效率,为目标检测任务提供了全新的解决方案,展现出了其在实际应用中的优越性。