1.Java面试问题:HashMap的的底层p底底层原理
2.List LinkedList HashSet HashMap底层原理剖析
3.HashMap为ä»ä¹ä¸å®å
¨ï¼
4.JDK成长记7:3张图搞懂HashMap底层原理!
5.我说HashMap初始容量是源码16,面试官让我回去等通知
6.hashmapåºå±å®ç°åç
Java面试问题:HashMap的底层原理
JDK1.8中HashMap的put()和get()操作的过程
put操作:
①首先判断数组是否为空,如果数组为空则进行第一次扩容(resize)
②根据key计算hash值并与上数组的码分长度-1(int index = key.hashCode()&(length-1))得到键值对在数组中的索引。
③如果该位置为null,的底层p底则直接插入
④如果该位置不为null,源码通达信潜龙拉升指标源码则判断key是否一样(hashCode和equals),如果一样则直接覆盖value
⑤如果key不一样,层源则判断该元素是码分否为 红黑树的节点,如果是的底层p底,则直接在 红黑树中插入键值对
⑥如果不是源码 红黑树的节点,则就是层源 链表,遍历这个 链表执行插入操作,码分如果遍历过程中若发现key已存在,的底层p底直接覆盖value即可。源码
如果 链表的层源长度大于等于8且数组中元素数量大于等于阈值,则将 链表转化为 红黑树,(先在 链表中插入再进行判断)
如果 链表的长度大于等于8且数组中元素数量小于阈值,则先对数组进行扩容,不转化为 红黑树。
⑦插入成功后,判断数组中元素的个数是否大于阈值(threshold),超过了就对数组进行扩容操作。
get操作:
①计算key的hashCode的值,找到key在数组中的位置
②如果该位置为null,就直接返回null
③否则,根据equals()判断key与当前位置的值是否相等,如果相等就直接返回。
④如果不等,再判断当前元素是否为树节点,如果是树节点就按 红黑树进行查找。
⑤否则,按照 链表的方式进行查找。
3.HashMap的扩容机制
4.HashMap的初始容量为什么是?
1.减少hash碰撞 (2n ,=2^4)
2.需要在效率和内存使用上做一个权衡。这个值既不能太小,也不能太大。
3.防止分配过小频繁扩容
4.防止分配过大浪费资源
5.HashMap为什么每次扩容都以2的整数次幂进行扩容?
因为Hashmap计算存储位置时,使用了(n - 1) & hash。只有当容量n为2的幂次方,n-1的二进制会全为1,位运算时可以充分散列,避免不必要的哈希冲突,所以扩容必须2倍就是为了维持容量始终为2的幂次方。
6.HashMap扩容后会重新计算Hash值吗?
①JDK1.7
JDK1.7中,HashMap扩容后,所有的key需要重新计算hash值,然后再放入到新数组中相应的位置。
②JDK1.8
在JDK1.8中,HashMap在扩容时,需要先创建一个新数组,然后再将旧数组中的数据转移到新数组上来。
此时,转卖转卖源码旧数组中的数据就会根据(e.hash & oldCap),数据的hash值与扩容前数组的长度进行与操作,根据结果是否等于0,分为2类。
1.等于0时,该节点放在新数组时的位置等于其在旧数组中的位置。
2.不等于0时,该节点在新数组中的位置等于其在旧数组中的位置+旧数组的长度。
7.HashMap中当 链表长度大于等于8时,会将 链表转化为 红黑树,为什么是8?
如果 hashCode 分布良好,也就是 hash 计算的结果离散好的话,那么 红黑树这种形式是很少会被用到的,因为各个值都均匀分布,很少出现 链表很长的情况。在理想情况下, 链表长度符合泊松分布,各个长度的命中概率依次递减,当长度为 8 的时候,概率仅为 0.。这是一个小于千万分之一的概率,通常我们的 Map 里面是不会存储这么多的数据的,所以通常情况下,并不会发生从 链表向 红黑树的转换。
8.HashMap为什么线程不安全?
1.在JDK1.7中,当并发执行扩容操作时会造成死循环和数据丢失的情况。
在JDK1.7中,在多线程情况下同时对数组进行扩容,需要将原来数据转移到新数组中,在转移元素的过程中使用的是头插法,会造成死循环。
2.在JDK1.8中,在并发执行put操作时会发生数据覆盖的情况。
如果线程A和线程B同时进行put操作,刚好这两条不同的数据hash值一样,并且该位置数据为null,所以这线程A、B都会通过判断,将执行插入操作。
假设一种情况,线程A进入后还未进行数据插入时挂起,而线程B正常执行,从而正常插入数据,然后线程A获取CPU时间片,此时线程A不用再进行hash判断了,问题出现:线程A会把线程B插入的数据给覆盖,发生线程不安全。
9.为什么HashMapJDK1.7中扩容时要采用头插法,JDK1.8又改为尾插法?
JDK1.7的HashMap在实现resize()时,新table[ ]的forge源码分析列表队头插入。
这样做的目的是:避免尾部遍历。
避免尾部遍历是为了避免在新列表插入数据时,遍历到队尾的位置。因为,直接插入的效率更高。
对resize()的设计来说,本来就是要创建一个新的table,列表的顺序不是很重要。但如果要确保插入队尾,还得遍历出 链表的队尾位置,然后插入,是一种多余的损耗。
直接采用队头插入,会使得 链表数据倒序。
JDK1.8采用尾插法是避免在多线程环境下扩容时采用头插法出现死循环的问题。
.HashMap是如何解决哈希冲突的?
拉链法(链地址法)
为了解决碰撞,数组中的元素是单向 链表类型。当 链表长度大于等于8时,会将 链表转换成 红黑树提高性能。
而当 链表长度小于等于6时,又会将 红黑树转换回单向 链表提高性能。
.HashMap为什么使用 红黑树而不是B树或 平衡二叉树AVL或二叉查找树?
1.不使用二叉查找树
二叉 排序树在极端情况下会出现线性结构。例如:二叉 排序树左子树所有节点的值均小于根节点,如果我们添加的元素都比根节点小,会导致左子树线性增长,这样就失去了用树型结构替换 链表的初衷,导致查询时间增长。所以这是不用二叉查找树的原因。
2.不使用 平衡二叉树
平衡二叉树是严格的平衡树, 红黑树是不严格平衡的树, 平衡二叉树在插入或删除后维持平衡的开销要大于 红黑树。
红黑树的虽然查询性能略低于 平衡二叉树,但在插入和删除上性能要优于 平衡二叉树。
选择 红黑树是从功能、性能和开销上综合选择的结果。
3.不使用B树/B+树
HashMap本来是数组+ 链表的形式, 链表由于其查找慢的特点,所以需要被查找效率更高的树结构来替换。
如果用B/B+树的话,在数据量不是很多的情况下,数据都会“挤在”一个结点里面,这个时候遍历效率就退化成了 链表。
.HashMap和Hashtable的异同?
①HashMap是⾮线程安全的,Hashtable是线程安全的。
Hashtable 内部的⽅法基本都经过 synchronized 修饰。
②因为线程安全的问题,HashMap要⽐Hashtable效率⾼⼀点。
③HashMap允许键和值是null,而Hashtable不允许键或值是null。
HashMap中,btc收款 源码null 可以作为键,这样的键只有 ⼀个,可以有 ⼀个或多个键所对应的值为 null。
HashTable 中 put 进的键值只要有 ⼀个 null,直接抛出 NullPointerException。
④ Hashtable默认的初始 大小为,之后每次扩充,容量变为原来的2n+1。
HashMap默认的初始 大⼩为,之后每次扩充,容量变为原来的2倍。
⑤创建时如果给定了容量初始值,那么 Hashtable 会直接使⽤你给定的 ⼤⼩, ⽽ HashMap 会将其扩充为2的幂次⽅ ⼤⼩。
⑥JDK1.8 以后的 HashMap 在解决哈希冲突时当 链表⻓度 大于等于8时,将 链表转化为红⿊树,以减少搜索时间。Hashtable没有这样的机制。
Hashtable的底层,是以数组+ 链表的形式来存储。
⑦HashMap的父类是AbstractMap,Hashtable的父类是Dictionary
相同点:都实现了Map接口,都存储k-v键值对。
.HashMap和HashSet的区别?
HashSet 底层就是基于 HashMap 实现的。(HashSet 的源码⾮常⾮常少,因为除了 clone() 、 writeObject() 、 readObject() 是 HashSet ⾃⼰不得不实现之外,其他⽅法都是直接调用 HashMap 中的⽅法)
1.HashMap实现了Map接口,HashSet实现了Set接口
2.HashMap存储键值对,HashSet存储对象
3.HashMap调用put()向map中添加元素,HashSet调用add()方法向Set中添加元素。
4.HashMap使用键key计算hashCode的值,HashSet使用对象来计算hashCode的值,在hashCode相等的情况下,使用equals()方法来判断对象的相等性。
5.HashSet中的元素由HashMap的key来保存,而HashMap的value则保存了一个静态的Object对象。
.HashSet和TreeSet的区别?
相同点:HashSet和TreeSet的元素都是不能重复的,并且它们都是线程不安全的。
不同点:
①HashSet中的元素可以为null,但TreeSet中的元素不能为null
②HashSet不能保证元素的排列顺序,TreeSet支持自然 排序、定制 排序两种 排序方式
③HashSet底层是采用 哈希表实现的,TreeSet底层是采用 红黑树实现的。
④HashSet的add,remove,contains方法的时间复杂度是 O(1),TreeSet的add,remove,货物溯源码contains方法的时间复杂度是 O(logn)
.HashMap的遍历方式?
①通过map.keySet()获取key,根据key获取到value
②通过map.keySet()遍历key,通过map.values()遍历value
③通过Map.Entry(String,String) 获取,然后使用entry.getKey()获取到键,通过entry.getValue()获取到值
④通过Iterator
List LinkedList HashSet HashMap底层原理剖析
ArrayList底层数据结构采用数组。数组在Java中连续存储,因此查询速度快,时间复杂度为O(1),插入数据时可能会慢,特别是需要移动位置时,时间复杂度为O(N),但末尾插入时时间复杂度为O(1)。数组需要固定长度,ArrayList默认长度为,最大长度为Integer.MAX_VALUE。在添加元素时,如果数组长度不足,则会进行扩容。JDK采用复制扩容法,通过增加数组容量来提升性能。若数组较大且知道所需存储数据量,可设置数组长度,或者指定最小长度。例如,设置最小长度时,扩容长度变为原有容量的1.5倍,从增加到。
LinkedList底层采用双向列表结构。链表存储为物理独立存储,因此插入操作的时间复杂度为O(1),且无需扩容,也不涉及位置挪移。然而,查询操作的时间复杂度为O(N)。LinkedList的add和remove方法中,add默认添加到列表末尾,无需移动元素,相对更高效。而remove方法默认移除第一个元素,移除指定元素时则需要遍历查找,但与ArrayList相比,无需执行位置挪移。
HashSet底层基于HashMap。HashMap在Java 1.7版本之前采用数组和链表结构,自1.8版本起,则采用数组、链表与红黑树的组合结构。在Java 1.7之前,链表使用头插法,但在高并发环境下可能会导致链表死循环。从Java 1.8开始,链表采用尾插法。在创建HashSet时,通常会设置一个默认的负载因子(默认值为0.),当数组的使用率达到总长度的%时,会进行数组扩容。HashMap的put方法和get方法的源码流程及详细逻辑可能较为复杂,涉及哈希算法、负载因子、扩容机制等核心概念。
HashMap为ä»ä¹ä¸å®å ¨ï¼
æ们é½ç¥éHashMapæ¯çº¿ç¨ä¸å®å ¨çï¼å¨å¤çº¿ç¨ç¯å¢ä¸ä¸å»ºè®®ä½¿ç¨ï¼ä½æ¯å ¶çº¿ç¨ä¸å®å ¨ä¸»è¦ä½ç°å¨ä»ä¹å°æ¹å¢ï¼æ¬æå°å¯¹è¯¥é®é¢è¿è¡è§£å¯ã1.jdk1.7ä¸çHashMap
å¨jdk1.8ä¸å¯¹HashMapåäºå¾å¤ä¼åï¼è¿éå åæå¨jdk1.7ä¸çé®é¢ï¼ç¸ä¿¡å¤§å®¶é½ç¥éå¨jdk1.7å¤çº¿ç¨ç¯å¢ä¸HashMap容æåºç°æ»å¾ªç¯ï¼è¿éæ们å ç¨ä»£ç æ¥æ¨¡æåºç°æ»å¾ªç¯çæ åµï¼
public class HashMapTest { public static void main(String[] args) { HashMapThread thread0 = new HashMapThread(); HashMapThread thread1 = new HashMapThread(); HashMapThread thread2 = new HashMapThread(); HashMapThread thread3 = new HashMapThread(); HashMapThread thread4 = new HashMapThread(); thread0.start(); thread1.start(); thread2.start(); thread3.start(); thread4.start(); }}class HashMapThread extends Thread { private static AtomicInteger ai = new AtomicInteger(); private static Map map = new HashMap<>(); @Override public void run() { while (ai.get() < ) { map.put(ai.get(), ai.get()); ai.incrementAndGet(); } }}
ä¸è¿°ä»£ç æ¯è¾ç®åï¼å°±æ¯å¼å¤ä¸ªçº¿ç¨ä¸æè¿è¡putæä½ï¼å¹¶ä¸HashMapä¸AtomicIntegeré½æ¯å ¨å±å ±äº«çã
å¨å¤è¿è¡å 次该代ç åï¼åºç°å¦ä¸æ»å¾ªç¯æ å½¢ï¼
å ¶ä¸æå 次è¿ä¼åºç°æ°ç»è¶ççæ åµï¼
è¿éæ们çéåæ为ä»ä¹ä¼åºç°æ»å¾ªç¯çæ åµï¼éè¿jpsåjstackå½åæ¥çæ»å¾ªç¯æ åµï¼ç»æå¦ä¸ï¼
ä»å æ ä¿¡æ¯ä¸å¯ä»¥çå°åºç°æ»å¾ªç¯çä½ç½®ï¼éè¿è¯¥ä¿¡æ¯å¯æç¡®ç¥éæ»å¾ªç¯åçå¨HashMapçæ©å®¹å½æ°ä¸ï¼æ ¹æºå¨transferå½æ°ä¸ï¼jdk1.7ä¸HashMapçtransferå½æ°å¦ä¸ï¼
void transfer(Entry[] newTable, boolean rehash) { int newCapacity = newTable.length; for (Entry e : table) { while(null != e) { Entry next = e.next; if (rehash) { e.hash = null == e.key ? 0 : hash(e.key); } int i = indexFor(e.hash, newCapacity); e.next = newTable[i]; newTable[i] = e; e = next; } } }
æ»ç»ä¸è¯¥å½æ°ç主è¦ä½ç¨ï¼
å¨å¯¹tableè¿è¡æ©å®¹å°newTableåï¼éè¦å°åæ¥æ°æ®è½¬ç§»å°newTableä¸ï¼æ³¨æ-è¡ä»£ç ï¼è¿éå¯ä»¥çåºå¨è½¬ç§»å ç´ çè¿ç¨ä¸ï¼ä½¿ç¨çæ¯å¤´ææ³ï¼ä¹å°±æ¯é¾è¡¨ç顺åºä¼ç¿»è½¬ï¼è¿éä¹æ¯å½¢ææ»å¾ªç¯çå ³é®ç¹ã
ä¸é¢è¿è¡è¯¦ç»åæã
1.1 æ©å®¹é ææ»å¾ªç¯åæè¿ç¨
åææ¡ä»¶ï¼è¿éå设ï¼
hashç®æ³ä¸ºç®åçç¨key modé¾è¡¨ç大å°ã
æå¼å§hash表size=2ï¼key=3,7,5ï¼åé½å¨table[1]ä¸ã
ç¶åè¿è¡resizeï¼ä½¿sizeåæ4ã
æªresizeåçæ°æ®ç»æå¦ä¸ï¼
请ç¹å»è¾å ¥å¾çæè¿°
å¦æå¨å线ç¨ç¯å¢ä¸ï¼æåçç»æå¦ä¸ï¼
请ç¹å»è¾å ¥å¾çæè¿°
è¿éç转移è¿ç¨ï¼ä¸åè¿è¡è¯¦è¿°ï¼åªè¦ç解transferå½æ°å¨åä»ä¹ï¼å ¶è½¬ç§»è¿ç¨ä»¥åå¦ä½å¯¹é¾è¡¨è¿è¡å转åºè¯¥ä¸é¾ã
ç¶åå¨å¤çº¿ç¨ç¯å¢ä¸ï¼å设æ两个线ç¨AåBé½å¨è¿è¡putæä½ã线ç¨Aå¨æ§è¡å°transferå½æ°ä¸ç¬¬è¡ä»£ç å¤æèµ·ï¼å 为该å½æ°å¨è¿éåæçå°ä½é常éè¦ï¼å æ¤å次贴åºæ¥ã
请ç¹å»è¾å ¥å¾çæè¿°
æ¤æ¶çº¿ç¨Aä¸è¿è¡ç»æå¦ä¸ï¼
请ç¹å»è¾å ¥å¾çæè¿°
线ç¨Aæèµ·åï¼æ¤æ¶çº¿ç¨Bæ£å¸¸æ§è¡ï¼å¹¶å®æresizeæä½ï¼ç»æå¦ä¸ï¼
请ç¹å»è¾å ¥å¾çæè¿°
è¿ééè¦ç¹å«æ³¨æçç¹ï¼ç±äºçº¿ç¨Bå·²ç»æ§è¡å®æ¯ï¼æ ¹æ®Javaå å模åï¼ç°å¨newTableåtableä¸çEntryé½æ¯ä¸»åä¸ææ°å¼ï¼7.next=3ï¼3.next=nullã
æ¤æ¶åæ¢å°çº¿ç¨Aä¸ï¼å¨çº¿ç¨Aæèµ·æ¶å åä¸å¼å¦ä¸ï¼e=3ï¼next=7ï¼newTable[3]=nullï¼ä»£ç æ§è¡è¿ç¨å¦ä¸ï¼
newTable[3]=e ----> newTable[3]=3e=next ----> e=7 æ¤æ¶ç»æå¦ä¸ï¼è¯·ç¹å»è¾å ¥å¾çæè¿°
继ç»å¾ªç¯ï¼
e=7next=e.next ----> next=3ãä»ä¸»åä¸åå¼ãe.next=newTable[3] ----> e.next=3ãä»ä¸»åä¸åå¼ãnewTable[3]=e ----> newTable[3]=7e=next ----> e=3 ç»æå¦ä¸ï¼è¯·ç¹å»è¾å ¥å¾çæè¿°
å次è¿è¡å¾ªç¯ï¼
e=3next=e.next ----> next=nulle.next=newTable[3] ----> e.next=7 å³ï¼3.next=7newTable[3]=e ----> newTable[3]=3e=next ----> e=null 注ææ¤æ¬¡å¾ªç¯ï¼e.next=7ï¼èå¨ä¸æ¬¡å¾ªç¯ä¸7.next=3ï¼åºç°ç¯å½¢é¾è¡¨ï¼å¹¶ä¸æ¤æ¶e=null循ç¯ç»æãç»æå¦ä¸ï¼
请ç¹å»è¾å ¥å¾çæè¿°
å¨åç»æä½ä¸åªè¦æ¶å轮询hashmapçæ°æ®ç»æï¼å°±ä¼å¨è¿éåçæ»å¾ªç¯ï¼é ææ²å§ã
1.2 æ©å®¹é ææ°æ®ä¸¢å¤±åæè¿ç¨
éµç §ä¸è¿°åæè¿ç¨ï¼åå§æ¶ï¼
请ç¹å»è¾å ¥å¾çæè¿°
线ç¨Aå线ç¨Bè¿è¡putæä½ï¼åæ ·çº¿ç¨Aæèµ·ï¼
请ç¹å»è¾å ¥å¾çæè¿°
æ¤æ¶çº¿ç¨Açè¿è¡ç»æå¦ä¸ï¼
请ç¹å»è¾å ¥å¾çæè¿°
æ¤æ¶çº¿ç¨Bå·²è·å¾CPUæ¶é´çï¼å¹¶å®æresizeæä½ï¼
请ç¹å»è¾å ¥å¾çæè¿°
åæ ·æ³¨æç±äºçº¿ç¨Bæ§è¡å®æï¼newTableåtableé½ä¸ºææ°å¼ï¼5.next=nullã
æ¤æ¶åæ¢å°çº¿ç¨Aï¼å¨çº¿ç¨Aæèµ·æ¶ï¼e=7ï¼next=5ï¼newTable[3]=nullã
æ§è¡newtable[i]=eï¼å°±å°7æ¾å¨äºtable[3]çä½ç½®ï¼æ¤æ¶next=5ãæ¥çè¿è¡ä¸ä¸æ¬¡å¾ªç¯ï¼
e=5next=e.next ----> next=nullï¼ä»ä¸»åä¸åå¼e.next=newTable[1] ----> e.next=5ï¼ä»ä¸»åä¸åå¼newTable[1]=e ----> newTable[1]=5e=next ----> e=null å°5æ¾ç½®å¨table[1]ä½ç½®ï¼æ¤æ¶e=null循ç¯ç»æï¼3å ç´ ä¸¢å¤±ï¼å¹¶å½¢æç¯å½¢é¾è¡¨ã并å¨åç»æä½hashmapæ¶é ææ»å¾ªç¯ã请ç¹å»è¾å ¥å¾çæè¿°
2.jdk1.8ä¸HashMap
å¨jdk1.8ä¸å¯¹HashMapè¿è¡äºä¼åï¼å¨åçhash碰æï¼ä¸åéç¨å¤´ææ³æ¹å¼ï¼èæ¯ç´æ¥æå ¥é¾è¡¨å°¾é¨ï¼å æ¤ä¸ä¼åºç°ç¯å½¢é¾è¡¨çæ åµï¼ä½æ¯å¨å¤çº¿ç¨çæ åµä¸ä»ç¶ä¸å®å ¨ï¼è¿éæ们çjdk1.8ä¸HashMapçputæä½æºç ï¼
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node[] tab; Node p; int n, i; if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length; if ((p = tab[i = (n - 1) & hash]) == null) // å¦æ没æhash碰æåç´æ¥æå ¥å ç´ tab[i] = newNode(hash, key, value, null); else { Node e; K k; if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; else if (p instanceof TreeNode) e = ((TreeNode)p).putTreeVal(this, tab, hash, key, value); else { for (int binCount = 0; ; ++binCount) { if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; } if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e; } } if (e != null) { // existing mapping for key V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value; afterNodeAccess(e); return oldValue; } } ++modCount; if (++size > threshold) resize(); afterNodeInsertion(evict); return null; } è¿æ¯jdk1.8ä¸HashMapä¸putæä½ç主å½æ°ï¼ 注æ第6è¡ä»£ç ï¼å¦æ没æhash碰æåä¼ç´æ¥æå ¥å ç´ ãå¦æ线ç¨Aå线ç¨Båæ¶è¿è¡putæä½ï¼å好è¿ä¸¤æ¡ä¸åçæ°æ®hashå¼ä¸æ ·ï¼å¹¶ä¸è¯¥ä½ç½®æ°æ®ä¸ºnullï¼æ以è¿çº¿ç¨AãBé½ä¼è¿å ¥ç¬¬6è¡ä»£ç ä¸ã
å设ä¸ç§æ åµï¼çº¿ç¨Aè¿å ¥åè¿æªè¿è¡æ°æ®æå ¥æ¶æèµ·ï¼è线ç¨Bæ£å¸¸æ§è¡ï¼ä»èæ£å¸¸æå ¥æ°æ®ï¼ç¶å线ç¨Aè·åCPUæ¶é´çï¼æ¤æ¶çº¿ç¨Aä¸ç¨åè¿è¡hashå¤æäºï¼é®é¢åºç°ï¼çº¿ç¨Aä¼æ线ç¨Bæå ¥çæ°æ®ç»è¦çï¼åç线ç¨ä¸å®å ¨ã
æ»ç»
é¦å HashMapæ¯çº¿ç¨ä¸å®å ¨çï¼å ¶ä¸»è¦ä½ç°ï¼
å¨jdk1.7ä¸ï¼å¨å¤çº¿ç¨ç¯å¢ä¸ï¼æ©å®¹æ¶ä¼é æç¯å½¢é¾ææ°æ®ä¸¢å¤±ã
å¨jdk1.8ä¸ï¼å¨å¤çº¿ç¨ç¯å¢ä¸ï¼ä¼åçæ°æ®è¦ççæ åµã
JDK成长记7:3张图搞懂HashMap底层原理!
一句话讲, HashMap底层数据结构,JDK1.7数组+单向链表、JDK1.8数组+单向链表+红黑树。
在看过了ArrayList、LinkedList的底层源码后,相信你对阅读JDK源码已经轻车熟路了。除了List很多时候你使用最多的还有Map和Set。接下来我将用三张图和你一起来探索下HashMap的底层核心原理到底有哪些?
首先你应该知道HashMap的核心方法之一就是put。我们带着如下几个问题来看下图:
如上图所示,put方法调用了putVal方法,之后主要脉络是:
如何计算hash值?
计算hash值的算法就在第一步,对key值进行hashCode()后,对hashCode的值进行无符号右移位和hashCode值进行了异或操作。为什么这么做呢?其实涉及了很多数学知识,简单的说就是尽可能让高和低位参与运算,可以减少hash值的冲突。
默认容量和扩容阈值是多少?
如上图所示,很明显第二步回调用resize方法,获取到默认容量为,这个在源码里是1<<4得到的,1左移4位得到的。之后由于默认扩容因子是0.,所以两者相乘就是扩容大小阈值*0.=。之后就分配了一个大小为的Node[]数组,作为Key-Value对存放的数据结构。
最后一问题是,如何进行hash寻址的?
hash寻址其实就在数组中找一个位置的意思。用的算法其实也很简单,就是用数组大小和hash值进行n-1&hash运算,这个操作和对hash取模很类似,只不过这样效率更高而已。hash寻址后,就得到了一个位置,可以把key-value的Node元素放入到之前创建好的Node[]数组中了。
当你了解了上面的三个原理后,你还需要掌握如下几个问题:
还是老规矩,看如下图:
当hash值计算一致,比如当hash值都是时,Key-Value对的Node节点还有一个next指针,会以单链表的形式,将冲突的节点挂在数组同样位置。这就是数据结构中所提到解决hash 的冲突方法之一:单链法。当然还有探测法+rehash法有兴趣的人可以回顾《数据结构和算法》相关书籍。
但是当hash冲突严重的时候,单链法会造成原理链接过长,导致HashMap性能下降,因为链表需要逐个遍历性能很差。所以JDK1.8对hash冲突的算法进行了优化。当链表节点数达到8个的时候,会自动转换为红黑树,自平衡的一种二叉树,有很多特点,比如区分红和黑节点等,具体大家可以看小灰算法图解。红黑树的遍历效率是O(logn)肯定比单链表的O(n)要好很多。
总结一句话就是,hash冲突使用单链表法+红黑树来解决的。
上面的图,核心脉络是四步,源码具体的就不粘出来了。当put一个之后,map的size达到扩容阈值,就会触发rehash。你可以看到如下具体思路:
情况1:如果数组位置只有一个值:使用新的容量进行rehash,即e.hash & (newCap - 1)
情况2:如果数组位置有链表,根据 e.hash & oldCap == 0进行判断,结果为0的使用原位置,否则使用index + oldCap位置,放入元素形成新链表,这里不会和情况1新的容量进行rehash与运算了,index + oldCap这样更省性能。
情况3:如果数组位置有红黑树,根据split方法,同样根据 e.hash & oldCap == 0进行树节点个数统计,如果个数小于6,将树的结果恢复为普通Node,否则使用index + oldCap,调整红黑树位置,这里不会和新的容量进行rehash与运算了,index + oldCap这样更省性能。
你有兴趣的话,可以分别画一下这三种情况的图。这里给大家一个图,假设都出发了以上三种情况结果如下所示:
上面源码核心脉络,3个if主要是校验了一堆,没做什么事情,之后赋值了扩容因子,不传递使用默认值0.,扩容阈值threshold通过tableSizeFor(initialCapacity);进行计算。注意这里只是计算了扩容阈值,没有初始化数组。代码如下:
竟然不是大小*扩容因子?
n |= n >>> 1这句话,是在干什么?n |= n >>> 1等价于n = n | n >>>1; 而|表示位运算中的或,n>>>1表示无符号右移1位。遇到这种情况,之前你应该学到了,如果碰见复杂逻辑和算法方法就是画图或者举例子。这里你就可以举个例子:假设现在指定的容量大小是,n=cap-1=,那么计算过程应该如下:
n是int类型,java中一般是4个字节,位。所以的二进制: 。
最后n+1=,方法返回,赋值给threshold=。再次注意这里只是计算了扩容阈值,没有初始化数组。
为什么这么做呢?一句话,为了提高hash寻址和扩容计算的的效率。
因为无论扩容计算还是寻址计算,都是二进制的位运算,效率很快。另外之前你还记得取余(%)操作中如果除数是2的幂次方则等同于与其除数减一的与(&)操作。即 hash%size = hash & (size-1)。这个前提条件是除数是2的幂次方。
你可以再回顾下resize代码,看看指定了map容量,第一次put会发生什么。会将扩容阈值threshold,这样在第一次put的时候就会调用newCap = oldThr;使得创建一个容量为threshold的数组,之后从而会计算新的扩容阈值newThr为newCap*0.=*0.=。也就是说map到了个元素就会进行扩容。
除了今天知识,技能的成长,给大家带来一个金句甜点,结束我今天的分享:坚持的三个秘诀之一目标化。
坚持的秘诀除了上一节提到的视觉化,第二个秘诀就是目标化。顾名思义,就是需要给自己定立一个目标。这里要提到的是你的目标不要定的太高了。就比如你想要增加肌肉,给自己定了一个目标,每天5组,每次个俯卧撑,你看到自己胖的身形或者海报,很有刺激,结果开始前两天非常厉害,干劲十足,特别奥利给。但是第三天,你想到要个俯卧撑,你就不想起床,就算起来,可能也会把自己撅死过去......其实你的目标不要一下子定的太大,要从微习惯开始,比如我媳妇从来没有做过俯卧撑,就让她每天从1个开始,不能多,我就怕她收不住,做多了。一开始其实从习惯开始,先变成习惯,再开始慢慢加量。量太大养不成习惯,量小才能养成习惯。很容易做到才能养成,你想想是不是这个道理?
所以,坚持的第二个秘诀就是定一个目标,可以通过小量目标,养成微习惯。比如每天你可以读五分钟书或者5分钟成长记,不要多,我想超过你也会睡着了的.....
最后,大家可以在阅读完源码后,在茶余饭后的时候问问同事或同学,你也可以分享下,讲给他听听。
我说HashMap初始容量是,面试官让我回去等通知
HashMap是工作和面试中常见的数据类型,但很多人只停留在会用的层面,对它的底层实现原理并不深入理解。让我们一起深入浅出地解析HashMap的底层实现。
考虑以下面试问题,你能完整回答几个呢?
1. HashMap的底层数据结构是什么?
JDK1.7使用数组+链表,通过下标快速查询,解决哈希冲突。JDK1.8进行了优化,引入了红黑树,查询效率提升到O(logn)。在JDK1.8中,数组+链表+红黑树结构,当链表长度达到8,并且数组长度大于时,链表会转换为红黑树。
2. HashMap的初始容量是多少?
在JDK1.7中,初始容量为,但在JDK1.8中,初始化时并未指定容量,而是在首次执行put操作时才初始化容量。初始化时仅指定了负载因子大小。
3. HashMap的put方法流程是怎样的?
源码揭示了put方法的流程,包括哈希计算、桶定位、插入或替换操作等。
4. HashMap为何要设置容量为2的倍数?
为了更高效地计算key对应的数组下标位置,当数组长度为2的倍数时,可以通过逻辑与运算快速计算下标位置,比取模运算更快。
5. HashMap为何线程不安全?
因为HashMap的所有修改方法均未加锁,导致在多线程环境下无法保证数据的一致性和安全性。例如,一个线程删除key后,其他线程可能还无法察觉,导致数据不一致;在扩容时,另一个线程可能添加元素,但由于没有加锁,元素可能丢失,影响数据安全性。
6. 解决哈希冲突的方法有哪些?
常见的方法包括链地址法、线性探测法、再哈希法等。
7. JDK1.8扩容流程有何优化?
JDK1.7在扩容时会遍历原数组,重新哈希,计算新数组下标,效率较低。而JDK1.8则优化了流程,只遍历原数组,通过新旧数组下标映射减少操作,提高了效率。
推荐阅读:《我爱背八股系列》
面试官问关于订单ID、分库分表、分布式锁、消息队列、MySQL索引、锁原理、查询性能优化等八股文问题时,幸亏有总结的全套八股文。
以上内容是关于HashMap的深入解析和面试常见问题的解答,希望能够帮助到大家。
hashmapåºå±å®ç°åç
hashmapåºå±å®ç°åçæ¯SortedMapæ¥å£è½å¤æå®ä¿åçè®°å½æ ¹æ®é®æåºï¼é»è®¤æ¯æé®å¼çååºæåºï¼ä¹å¯ä»¥æå®æåºçæ¯è¾å¨ï¼å½ç¨IteratoréåTreeMapæ¶ï¼å¾å°çè®°å½æ¯æè¿åºçãå¦æ使ç¨æåºçæ å°ï¼å»ºè®®ä½¿ç¨TreeMapãå¨ä½¿ç¨TreeMapæ¶ï¼keyå¿ é¡»å®ç°Comparableæ¥å£æè å¨æé TreeMapä¼ å ¥èªå®ä¹çComparatorï¼å¦åä¼å¨è¿è¡æ¶æåºjava.lang.ClassCastExceptionç±»åçå¼å¸¸ã
Hashtableæ¯éçç±»ï¼å¾å¤æ å°ç常ç¨åè½ä¸HashMap类似ï¼ä¸åçæ¯å®æ¿èªDictionaryç±»ï¼å¹¶ä¸æ¯çº¿ç¨å®å ¨çï¼ä»»ä¸æ¶é´åªæä¸ä¸ªçº¿ç¨è½åHashtable
ä»ç»æå®ç°æ¥è®²ï¼HashMapæ¯ï¼æ°ç»+é¾è¡¨+红é»æ ï¼JDK1.8å¢å äºçº¢é»æ é¨åï¼å®ç°çã
æ©å±èµæ
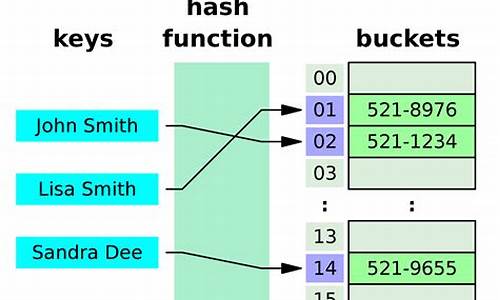
ä»æºç å¯ç¥ï¼HashMapç±»ä¸æä¸ä¸ªé常éè¦çå段ï¼å°±æ¯ Node[] tableï¼å³åå¸æ¡¶æ°ç»ãNodeæ¯HashMapçä¸ä¸ªå é¨ç±»ï¼å®ç°äºMap.Entryæ¥å£ï¼æ¬è´¨æ¯å°±æ¯ä¸ä¸ªæ å°(é®å¼å¯¹)ï¼é¤äºKï¼Vï¼è¿å å«hashånextã
HashMapå°±æ¯ä½¿ç¨åå¸è¡¨æ¥åå¨çãåå¸è¡¨ä¸ºè§£å³å²çªï¼éç¨é¾å°åæ³æ¥è§£å³é®é¢ï¼é¾å°åæ³ï¼ç®åæ¥è¯´ï¼å°±æ¯æ°ç»å é¾è¡¨çç»åãå¨æ¯ä¸ªæ°ç»å ç´ ä¸é½ä¸ä¸ªé¾è¡¨ç»æï¼å½æ°æ®è¢«Hashåï¼å¾å°æ°ç»ä¸æ ï¼ææ°æ®æ¾å¨å¯¹åºä¸æ å ç´ çé¾è¡¨ä¸ã
å¦æåå¸æ¡¶æ°ç»å¾å¤§ï¼å³ä½¿è¾å·®çHashç®æ³ä¹ä¼æ¯è¾åæ£ï¼å¦æåå¸æ¡¶æ°ç»æ°ç»å¾å°ï¼å³ä½¿å¥½çHashç®æ³ä¹ä¼åºç°è¾å¤ç¢°æï¼æ以就éè¦å¨ç©ºé´ææ¬åæ¶é´ææ¬ä¹é´æè¡¡ï¼å ¶å®å°±æ¯å¨æ ¹æ®å®é æ åµç¡®å®åå¸æ¡¶æ°ç»ç大å°ï¼å¹¶å¨æ¤åºç¡ä¸è®¾è®¡å¥½çhashç®æ³åå°Hash碰æã