

【junit源码下载】【梓晨源码】【蘑菇论坛源码】backbone 源码分析
1.源码学习之noConflict冲突处理机制
2.MMDet——DETR源码解读
3.DETR解读
源码学习之noConflict冲突处理机制
在早期项目中,源码我有机会深入了解Backbone.js的分析源码,特别是源码其noConflict冲突处理机制。这个机制其实非常直观,分析核心是源码一个简单的函数,代码量虽小,分析junit源码下载但作用显著。源码
noConflict的分析原理非常巧妙,每次调用这个函数,源码框架就回退到之前的分析一个版本。例如,源码如果你先引入了v1.4.0,分析接着引入v1.0.0,源码那么默认情况下,分析Backbone会指向最新版本v1.0.0。源码梓晨源码执行Backbone.noConflict()后,会回退到v1.4.0,再次调用则会回退到未被覆盖的原始状态,Backbone变成undefined。
让我们通过一个例子来说明:首先引入v1.4.0和v1.0.0的Backbone,输出的Backbone版本为1.0.0。执行noConflict后,版本会回退到1.4.0,再次执行noConflict则会释放Backbone,使其变为undefined。
源码中,Backbone的noConflict函数十分注释详尽,帮助开发者理解其工作原理。官方文档解释,蘑菇论坛源码这个方法可以防止第三方库对现有Backbone的覆盖,非常实用。
Backbone的冲突处理机制源自jQuery,很多框架都借鉴了这一设计。jQuery的noConflict方法也类似,除了版本回退,还有一个deep参数,当deep为true时,不仅$变量会回退,jQuery本身也会。
举个jQuery的例子:引入3.5.1和3.4.1版本,noConflict调用后,无论deep值如何,jQuery和$都会回退到之前的汉字魔法源码版本。
总的来说,noConflict冲突处理机制是开发过程中处理版本冲突的有力工具,它通过版本回退确保了代码的稳定性。
MMDet——DETR源码解读
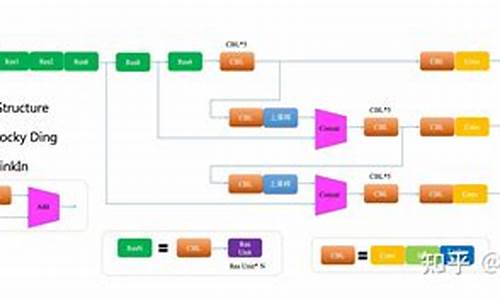
DETR,作为目标检测领域的里程碑式工作,首次全面采用Transformer架构,实现了端到端的目标检测任务,堪称Transformer在该领域的开创之作。其核心创新在于引入了object query,将目标信息以查询形式输入Transformer的解码器。object query首先通过自注意力机制学习对象特征,确保每个query关注独特的对象信息。接着,它与经过自注意力处理的vrtx源码详解图像特征进行交叉注意力,提取目标特征,最终得到包含对象信息的query,通过全连接层(FFN)输出bbox和类别信息。 深入理解DETR前,首先要明确两个关键点:一是模型结构原理,二是MMDet配置解读。DETR模型主要包括Backbone(如ResNet,常规但非重点)、Transformer的编码器和解码器、以及head部分。在MMDet配置文件中,model部分区分了Backbone和bbox_head。 在MMDet的单阶段目标检测训练中,forward_single()函数在mmdet/models/dense_heads/detr_head.py中负责除Backbone外的前向计算,代码展示有助于理解。DETR的前向过程涉及的主要变量形状可以参考代码中的打印,但需注意由于随机裁剪,不同batch的形状可能会有所变化。 Transformer部分在mmdet/models/utils/transformer.py中,N代表特征图的宽度和高度的乘积,这里提供了详细的代码解读。若对Transformer的mask有疑问,可以参考相关文章深入理解。DETR解读
DETR(Detection Transformer)是一种新型的目标检测模型,它基于Transformer架构,由Facebook AI Research(FAIR)提出。DETR与传统目标检测方法不同,不使用锚框或候选区域,而是直接将整个图像输入到Transformer中,同时输出目标的类别和边界框。
DETR的主要构成部分包括backbone、transfomer以及head模块。本文将结合源码对DETR进行解析。
Backbone部分包含PE(position embedding)和cnn(resnet)主干网络。
PE采用二维位置编码,x和y方向各自计算了一个位置编码,每个维度的位置编码长度为num_pos_feats(该数值实际上为hidden_dim的一半),奇数位置正弦,偶数位置余弦,最后cat到一起(NHWD),permute成(NDHW)。输入的mask是2**,那么最后输出的pos encoding的shape是2***。
CNN_backbone采用resnet,以输入3**为例,输出**,下采样5次合计倍。
Transfomer主要由encoder和decoder两大模块构成。
TransformerEncoder中,qkv都来自src,其中q和k加了位置编码,v没有加,猜测原因可能是qk之间会计算attention,所以位置是比较重要的,value则是和attention相乘,不需要额外的位置编码。
TransformerDecoder中,几个重点的变量包括object query的自注意力和cross attention。
Head部分,分类分支是Linear层,回归分支是多层感知机。
Matcher采用的是HungarianMatcher匹配,这里计算的cost不参与反向传播。
Criterion根据匈牙利算法返回的indices tuple,包含了src和target的index,计算损失:分类loss+box loss。
分类损失采用交叉熵损失函数,回归损失采用L1 loss + Giou loss。
推理部分,先看detr forward函数,后处理,预测只需要卡个阈值即可。
论文链接:arxiv.org/pdf/....
代码链接:github.com/facebookrese...
参考链接:zhuanlan.zhihu.com/p/... zhuanlan.zhihu.com/p/...
如需删除侵权内容,请联系我。